 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Diverse Assignment Strategies into DETRs
Jan 14, 2026Label assignment is a critical component in object detectors, particularly within DETR-style frameworks where the one-to-one matching strategy, despite its end-to-end elegance, suffers from slow convergence due to sparse supervision. While recent works have explored one-to-many assignments to enrich supervisory signals, they often introduce complex, architecture-specific modifications and typically focus on a single auxiliary strategy, lacking a unified and scalable design. In this paper, we first systematically investigate the effects of ``one-to-many'' supervision and reveal a surprising insight that performance gains are driven not by the sheer quantity of supervision, but by the diversity of the assignment strategies employed. This finding suggests that a more elegant, parameter-efficient approach is attainable. Building on this insight, we propose LoRA-DETR, a flexible and lightweight framework that seamlessly integrates diverse assignment strategies into any DETR-style detector. Our method augments the primary network with multiple Low-Rank Adaptation (LoRA) branches during training, each instantiating a different one-to-many assignment rule. These branches act as auxiliary modules that inject rich, varied supervisory gradients into the main model and are discarded during inference, thus incurring no additional computational cost. This design promotes robust joint optimization while maintaining the architectural simplicity of the original detector. Extensive experiments on different baselines validate the effectiveness of our approach. Our work presents a new paradigm for enhancing detectors, demonstrating that diverse ``one-to-many'' supervision can be integrated to achieve state-of-the-art results without compromising model elegance.
VQ-Map: Bird's-Eye-View Map Layout Estimation in Tokenized Discrete Space via Vector Quantization
Nov 03, 2024



Bird's-eye-view (BEV) map layout estimation requires an accurate and full understanding of the semantics for the environmental elements around the ego car to make the results coherent and realistic. Due to the challenges posed by occlusion, unfavourable imaging conditions and low resolution, \emph{generating} the BEV semantic maps corresponding to corrupted or invalid areas in the perspective view (PV) is appealing very recently. \emph{The question is how to align the PV features with the generative models to facilitate the map estimation}. In this paper, we propose to utilize a generative model similar to the Vector Quantized-Variational AutoEncoder (VQ-VAE) to acquire prior knowledge for the high-level BEV semantics in the tokenized discrete space. Thanks to the obtained BEV tokens accompanied with a codebook embedding encapsulating the semantics for different BEV elements in the groundtruth maps, we are able to directly align the sparse backbone image features with the obtained BEV tokens from the discrete representation learning based on a specialized token decoder module, and finally generate high-quality BEV maps with the BEV codebook embedding serving as a bridge between PV and BEV. We evaluate the BEV map layout estimation performance of our model, termed VQ-Map, on both the nuScenes and Argoverse benchmarks, achieving 62.2/47.6 mean IoU for surround-view/monocular evaluation on nuScenes, as well as 73.4 IoU for monocular evaluation on Argoverse, which all set a new record for this map layout estimation task. The code and models are available on \url{https://github.com/Z1zyw/VQ-Map}.
BEV2PR: BEV-Enhanced Visual Place Recognition with Structural Cues
Mar 11, 2024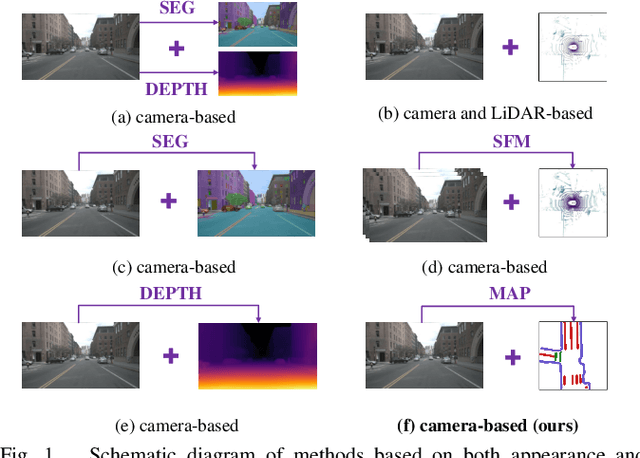
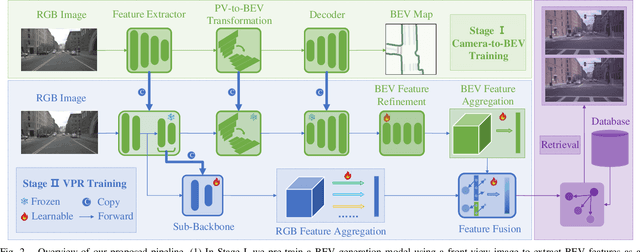

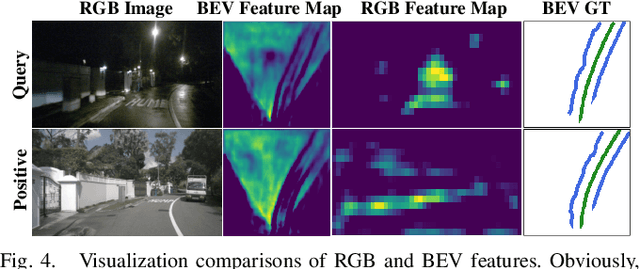
In this paper, we propose a new image-based visual place recognition (VPR) framework by exploiting the structural cues in bird's-eye view (BEV) from a single monocular camera. The motivation arises from two key observations about VPR: 1) For the methods based on both camera and LiDAR sensors, the integration of LiDAR in robotic systems has led to increased expenses, while the alignment of data between different sensors is also a major challenge. 2) Other image-/camera-based methods, involving integrating RGB images and their derived variants (e.g., pseudo depth images, pseudo 3D point clouds), exhibit several limitations, such as the failure to effectively exploit the explicit spatial relationships between different objects. To tackle the above issues, we design a new BEV-enhanced VPR framework, nemely BEV2PR, which can generate a composite descriptor with both visual cues and spatial awareness solely based on a single camera. For the visual cues, any popular aggregation module for RGB global features can be integrated into our framework. The key points lie in: 1) We use BEV segmentation features as an explicit source of structural knowledge in constructing global features. 2) The lower layers of the pre-trained backbone from BEV map generation are shared for visual and structural streams in VPR, facilitating the learning of fine-grained local features in the visual stream. 3) The complementary visual features and structural features can jointly enhance VPR performance. Our BEV2PR framework enables consistent performance improvements over several popular camera-based VPR aggregation modules when integrating them. The experiments on our collected VPR-NuScenes dataset demonstrate an absolute gain of 2.47% on Recall@1 for the strong Conv-AP baseline to achieve the best performance in our setting, and notably, a 18.06% gain on the hard set.