 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV2PR: BEV-Enhanced Visual Place Recognition with Structural Cues
Paper and Code
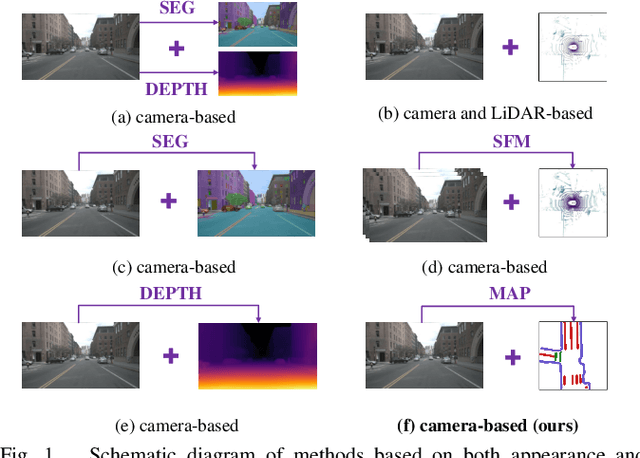
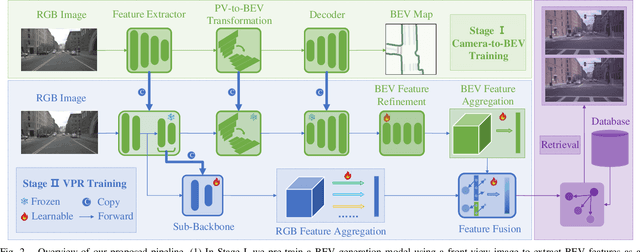

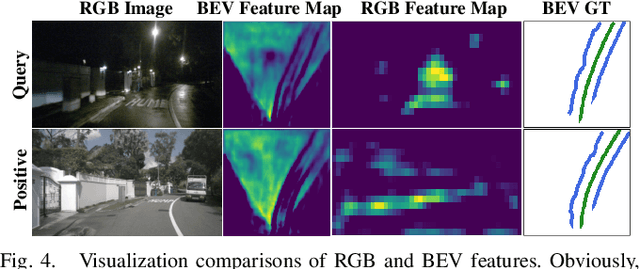
In this paper, we propose a new image-based visual place recognition (VPR) framework by exploiting the structural cues in bird's-eye view (BEV) from a single monocular camera. The motivation arises from two key observations about VPR: 1) For the methods based on both camera and LiDAR sensors, the integration of LiDAR in robotic systems has led to increased expenses, while the alignment of data between different sensors is also a major challenge. 2) Other image-/camera-based methods, involving integrating RGB images and their derived variants (e.g., pseudo depth images, pseudo 3D point clouds), exhibit several limitations, such as the failure to effectively exploit the explicit spatial relationships between different objects. To tackle the above issues, we design a new BEV-enhanced VPR framework, nemely BEV2PR, which can generate a composite descriptor with both visual cues and spatial awareness solely based on a single camera. For the visual cues, any popular aggregation module for RGB global features can be integrated into our framework. The key points lie in: 1) We use BEV segmentation features as an explicit source of structural knowledge in constructing global features. 2) The lower layers of the pre-trained backbone from BEV map generation are shared for visual and structural streams in VPR, facilitating the learning of fine-grained local features in the visual stream. 3) The complementary visual features and structural features can jointly enhance VPR performance. Our BEV2PR framework enables consistent performance improvements over several popular camera-based VPR aggregation modules when integrating them. The experiments on our collected VPR-NuScenes dataset demonstrate an absolute gain of 2.47% on Recall@1 for the strong Conv-AP baseline to achieve the best performance in our setting, and notably, a 18.06% gain on the hard set.