 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassNet: Scaling Large Language Models for Graph Compiler Pass Generation
May 28, 2026Modern tensor compilers such as TorchInductor deliver substantial speedups on mainstream models, yet face a systematic performance ceiling on long-tail workloads -- our profiling shows that 43% of real-world subgraphs experience end-to-end slowdowns under default compilation. While LLMs offer a path toward automated optimization, existing efforts focus on standalone kernel generation. We argue that pass generation -- where LLMs author structured graph transformations that integrate directly into compiler pipelines -- is the more appropriate abstraction. We propose PassNet, the first large-scale ecosystem for LLM-based compiler pass generation, comprising: (1) PassNet-Dataset, over 18K unique computational graphs from 100K real-world models; and (2) PassBench, 200 curated long-tail fusible tasks (comprising 2,060 subgraphs in total) evaluated under the Error-aware Speedup Score (ES_t) -- a metric unifying correctness, stability, and performance -- with layered integrity defenses against systematic LLM exploitation. Experiments reveal that PassBench is both highly discriminative and genuinely unsaturated: the best frontier model trails TorchInductor by 37% in aggregate, yet on individual subgraphs LLMs achieve up to 3x speedup over the same compiler -- indicating that the bottleneck is consistency, not capability. Fine-tuning a small model on merely ~4K PassNet trajectories yields a 2.67x improvement approaching frontier-model performance, demonstrating substantial headroom and validating PassNet as live training infrastructure for advancing LLM-driven compiler optimization. All data, benchmarks, and tooling are publicly available.
OneDrive: Unified Multi-Paradigm Driving with Vision-Language-Action Models
Apr 20, 2026Vision-Language Models(VLMs) excel at autoregressive text generation, yet end-to-end autonomous driving requires multi-task learning with structured outputs and heterogeneous decoding behaviors, such as autoregressive language generation, parallel object detection and trajectory regression. To accommodate these differences, existing systems typically introduce separate or cascaded decoders, resulting in architectural fragmentation and limited backbone reuse. In this work, we present a unified autonomous driving framework built upon a pretrained VLM, where heterogeneous decoding behaviors are reconciled within a single transformer decoder. We demonstrate that pretrained VLM attention exhibits strong transferability beyond pure language modeling. By organizing visual and structured query tokens within a single causal decoder, structured queries can naturally condition on visual context through the original attention mechanism. Textual and structured outputs share a common attention backbone, enabling stable joint optimization across heterogeneous tasks. Trajectory planning is realized within the same causal LLM decoder by introducing structured trajectory queries. This unified formulation enables planning to share the pretrained attention backbone with images and perception tokens. Extensive experiments on end-to-end autonomous driving benchmarks demonstrate state-of-the-art performance, including 0.28 L2 and 0.18 collision rate on nuScenes open-loop evaluation and competitive results (86.8 PDMS) on NAVSIM closed-loop evaluation. The full model preserves multi-modal generation capability, while an efficient inference mode achieves approximately 40% lower latency. Code and models are available at https://github.com/Z1zyw/OneDrive
FIRE: A Comprehensive Benchmark for Financial Intelligence and Reasoning Evaluation
Feb 25, 2026We introduce FIRE, a comprehensive benchmark designed to evaluate both the theoretical financial knowledge of LLMs and their ability to handle practical business scenarios. For theoretical assessment, we curate a diverse set of examination questions drawn from widely recognized financial qualification exams, enabling evaluation of LLMs deep understanding and application of financial knowledge. In addition, to assess the practical value of LLMs in real-world financial tasks, we propose a systematic evaluation matrix that categorizes complex financial domains and ensures coverage of essential subdomains and business activities. Based on this evaluation matrix, we collect 3,000 financial scenario questions, consisting of closed-form decision questions with reference answers and open-ended questions evaluated by predefined rubrics. We conduct comprehensive evaluations of state-of-the-art LLMs on the FIRE benchmark, including XuanYuan 4.0, our latest financial-domain model, as a strong in-domain baseline. These results enable a systematic analysis of the capability boundaries of current LLMs in financial applications. We publicly release the benchmark questions and evaluation code to facilitate future research.
SoLA-Vision: Fine-grained Layer-wise Linear Softmax Hybrid Attention
Jan 16, 2026Standard softmax self-attention excels in vision tasks but incurs quadratic complexity O(N^2), limiting high-resolution deployment. Linear attention reduces the cost to O(N), yet its compressed state representations can impair modeling capacity and accuracy. We present an analytical study that contrasts linear and softmax attention for visual representation learning from a layer-stacking perspective. We further conduct systematic experiments on layer-wise hybridization patterns of linear and softmax attention. Our results show that, compared with rigid intra-block hybrid designs, fine-grained layer-wise hybridization can match or surpass performance while requiring fewer softmax layers. Building on these findings, we propose SoLA-Vision (Softmax-Linear Attention Vision), a flexible layer-wise hybrid attention backbone that enables fine-grained control over how linear and softmax attention are integrated. By strategically inserting a small number of global softmax layers, SoLA-Vision achieves a strong trade-off between accuracy and computational cost. On ImageNet-1K, SoLA-Vision outperforms purely linear and other hybrid attention models. On dense prediction tasks, it consistently surpasses strong baselines by a considerable margin. Code will be released.
Integrating Diverse Assignment Strategies into DETRs
Jan 14, 2026Label assignment is a critical component in object detectors, particularly within DETR-style frameworks where the one-to-one matching strategy, despite its end-to-end elegance, suffers from slow convergence due to sparse supervision. While recent works have explored one-to-many assignments to enrich supervisory signals, they often introduce complex, architecture-specific modifications and typically focus on a single auxiliary strategy, lacking a unified and scalable design. In this paper, we first systematically investigate the effects of ``one-to-many'' supervision and reveal a surprising insight that performance gains are driven not by the sheer quantity of supervision, but by the diversity of the assignment strategies employed. This finding suggests that a more elegant, parameter-efficient approach is attainable. Building on this insight, we propose LoRA-DETR, a flexible and lightweight framework that seamlessly integrates diverse assignment strategies into any DETR-style detector. Our method augments the primary network with multiple Low-Rank Adaptation (LoRA) branches during training, each instantiating a different one-to-many assignment rule. These branches act as auxiliary modules that inject rich, varied supervisory gradients into the main model and are discarded during inference, thus incurring no additional computational cost. This design promotes robust joint optimization while maintaining the architectural simplicity of the original detector. Extensive experiments on different baselines validate the effectiveness of our approach. Our work presents a new paradigm for enhancing detectors, demonstrating that diverse ``one-to-many'' supervision can be integrated to achieve state-of-the-art results without compromising model elegance.
Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
Dec 19, 2025The rapid evolution of text-to-image generation models has revolutionized visual content creation. While commercial products like Nano Banana Pro have garnered significant attention, their potential as generalist solvers for traditional low-level vision challenges remains largely underexplored. In this study, we investigate the critical question: Is Nano Banana Pro a Low-Level Vision All-Rounder? We conducted a comprehensive zero-shot evaluation across 14 distinct low-level tasks spanning 40 diverse datasets. By utilizing simple textual prompts without fine-tuning, we benchmarked Nano Banana Pro against state-of-the-art specialist models. Our extensive analysis reveals a distinct performance dichotomy: while \textbf{Nano Banana Pro demonstrates superior subjective visual quality}, often hallucinating plausible high-frequency details that surpass specialist models, it lags behind in traditional reference-based quantitative metrics. We attribute this discrepancy to the inherent stochasticity of generative models, which struggle to maintain the strict pixel-level consistency required by conventional metrics. This report identifies Nano Banana Pro as a capable zero-shot contender for low-level vision tasks, while highlighting that achieving the high fidelity of domain specialists remains a significant hurdle.
Online Segment Any 3D Thing as Instance Tracking
Dec 08, 2025Online, real-time, and fine-grained 3D segmentation constitutes a fundamental capability for embodied intelligent agents to perceive and comprehend their operational environments. Recent advancements employ predefined object queries to aggregate semantic information from Vision Foundation Models (VFMs) outputs that are lifted into 3D point clouds, facilitating spatial information propagation through inter-query interactions. Nevertheless, perception is an inherently dynamic process, rendering temporal understanding a critical yet overlooked dimension within these prevailing query-based pipelines. Therefore, to further unlock the temporal environmental perception capabilities of embodied agents, our work reconceptualizes online 3D segmentation as an instance tracking problem (AutoSeg3D). Our core strategy involves utilizing object queries for temporal information propagation, where long-term instance association promotes the coherence of features and object identities, while short-term instance update enriches instant observations. Given that viewpoint variations in embodied robotics often lead to partial object visibility across frames, this mechanism aids the model in developing a holistic object understanding beyond incomplete instantaneous views. Furthermore, we introduce spatial consistency learning to mitigate the fragmentation problem inherent in VFMs, yielding more comprehensive instance information for enhancing the efficacy of both long-term and short-term temporal learning. The temporal information exchange and consistency learning facilitated by these sparse object queries not only enhance spatial comprehension but also circumvent the computational burden associated with dense temporal point cloud interactions. Our method establishes a new state-of-the-art, surpassing ESAM by 2.8 AP on ScanNet200 and delivering consistent gains on ScanNet, SceneNN, and 3RScan datasets.
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025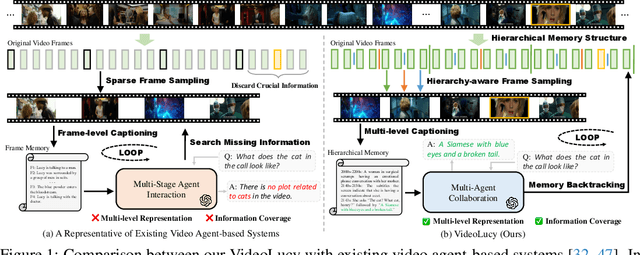
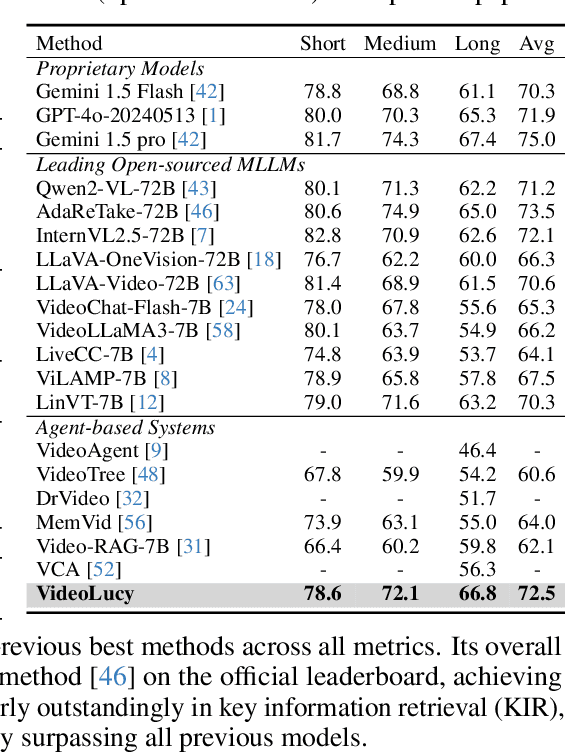
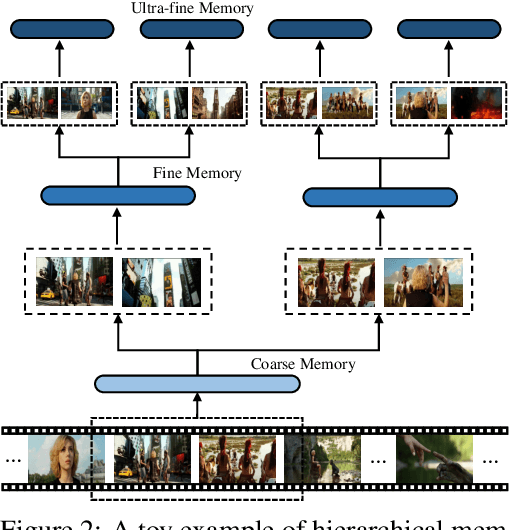

Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
WD-DETR: Wavelet Denoising-Enhanced Real-Time Object Detection Transformer for Robot Perception with Event Cameras
Jun 10, 2025Previous studies on event camera sensing have demonstrated certain detection performance using dense event representations. However, the accumulated noise in such dense representations has received insufficient attention, which degrades the representation quality and increases the likelihood of missed detections. To address this challenge, we propose the Wavelet Denoising-enhanced DEtection TRansformer, i.e., WD-DETR network, for event cameras. In particular, a dense event representation is presented first, which enables real-time reconstruction of events as tensors. Then, a wavelet transform method is designed to filter noise in the event representations. Such a method is integrated into the backbone for feature extraction. The extracted features are subsequently fed into a transformer-based network for object prediction. To further reduce inference time, we incorporate the Dynamic Reorganization Convolution Block (DRCB) as a fusion module within the hybrid encoder. The proposed method has been evaluated on three event-based object detection datasets, i.e., DSEC, Gen1, and 1Mpx. The results demonstrate that WD-DETR outperforms tested state-of-the-art methods. Additionally, we implement our approach on a common onboard computer for robots, the NVIDIA Jetson Orin NX, achieving a high frame rate of approximately 35 FPS using TensorRT FP16, which is exceptionally well-suited for real-time perception of onboard robotic systems.
Dual-Modality Computational Ophthalmic Imaging with Deep Learning and Coaxial Optical Design
Apr 13, 2025The growing burden of myopia and retinal diseases necessitates more accessible and efficient eye screening solutions. This study presents a compact, dual-function optical device that integrates fundus photography and refractive error detection into a unified platform. The system features a coaxial optical design using dichroic mirrors to separate wavelength-dependent imaging paths, enabling simultaneous alignment of fundus and refraction modules. A Dense-U-Net-based algorithm with customized loss functions is employed for accurate pupil segmentation, facilitating automated alignment and focusing. Experimental evaluations demonstrate the system's capability to achieve high-precision pupil localization (EDE = 2.8 px, mIoU = 0.931) and reliable refractive estimation with a mean absolute error below 5%. Despite limitations due to commercial lens components, the proposed framework offers a promising solution for rapid, intelligent, and scalable ophthalmic screening, particularly suitable for community health settings.