 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: A Benchmark for Knowledge Graph Construction, Question Answering, and In-Script Role-Playing over Movie Screenplays
Jan 13, 2026Movie screenplays are rich long-form narratives that interleave complex character relationships, temporally ordered events, and dialogue-driven interactions. While prior benchmarks target individual subtasks such as question answering or dialogue generation, they rarely evaluate whether models can construct a coherent story world and use it consistently across multiple forms of reasoning and generation. We introduce STAGE (Screenplay Text, Agents, Graphs and Evaluation), a unified benchmark for narrative understanding over full-length movie screenplays. STAGE defines four tasks: knowledge graph construction, scene-level event summarization, long-context screenplay question answering, and in-script character role-playing, all grounded in a shared narrative world representation. The benchmark provides cleaned scripts, curated knowledge graphs, and event- and character-centric annotations for 150 films across English and Chinese, enabling holistic evaluation of models' abilities to build world representations, abstract and verify narrative events, reason over long narratives, and generate character-consistent responses.
Heterogeneous Multi-Expert Reinforcement Learning for Long-Horizon Multi-Goal Tasks in Autonomous Forklifts
Jan 12, 2026Autonomous mobile manipulation in unstructured warehouses requires a balance between efficient large-scale navigation and high-precision object interaction. Traditional end-to-end learning approaches often struggle to handle the conflicting demands of these distinct phases. Navigation relies on robust decision-making over large spaces, while manipulation needs high sensitivity to fine local details. Forcing a single network to learn these different objectives simultaneously often causes optimization interference, where improving one task degrades the other. To address these limitations, we propose a Heterogeneous Multi-Expert Reinforcement Learning (HMER) framework tailored for autonomous forklifts. HMER decomposes long-horizon tasks into specialized sub-policies controlled by a Semantic Task Planner. This structure separates macro-level navigation from micro-level manipulation, allowing each expert to focus on its specific action space without interference. The planner coordinates the sequential execution of these experts, bridging the gap between task planning and continuous control. Furthermore, to solve the problem of sparse exploration, we introduce a Hybrid Imitation-Reinforcement Training Strategy. This method uses expert demonstrations to initialize the policy and Reinforcement Learning for fine-tuning. Experiments in Gazebo simulations show that HMER significantly outperforms sequential and end-to-end baselines. Our method achieves a task success rate of 94.2\% (compared to 62.5\% for baselines), reduces operation time by 21.4\%, and maintains placement error within 1.5 cm, validating its efficacy for precise material handling.
GDEPO: Group Dual-dynamic and Equal-right-advantage Policy Optimization with Enhanced Training Data Utilization for Sample-Constrained Reinforcement Learning
Jan 11, 2026Automated Theorem Proving (ATP) represents a fundamental challenge in Artificial Intelligence (AI), requiring the construction of machine-verifiable proofs in formal languages such as Lean to evaluate AI reasoning capabilities. Reinforcement learning (RL), particularly the high-performance Group Relative Policy Optimization (GRPO) algorithm, has emerged as a mainstream approach for this task. However, in ATP scenarios, GRPO faces two critical issues: when composite rewards are used, its relative advantage estimation may conflict with the binary feedback from the formal verifier; meanwhile, its static sampling strategy may discard entire batches of data if no valid proof is found, resulting in zero contribution to model updates and significant data waste. To address these limitations, we propose Group Dual-dynamic and Equal-right-advantage Policy Optimization (GDEPO), a method incorporating three core mechanisms: 1) dynamic additional sampling, which resamples invalid batches until a valid proof is discovered; 2) equal-right advantage, decoupling the sign of the advantage function (based on correctness) from its magnitude (modulated by auxiliary rewards) to ensure stable and correct policy updates; and 3) dynamic additional iterations, applying extra gradient steps to initially failed but eventually successful samples to accelerate learning on challenging cases. Experiments conducted on three datasets of varying difficulty (MinF2F-test, MathOlympiadBench, PutnamBench) confirm the effectiveness of GDEPO, while ablation studies validate the necessity of its synergistic components. The proposed method enhances data utilization and optimization efficiency, offering a novel training paradigm for ATP.
Federated Learning for Cross-Domain Data Privacy: A Distributed Approach to Secure Collaboration
Mar 31, 2025This paper proposes a data privacy protection framework based on federated learning, which aims to realize effective cross-domain data collaboration under the premise of ensuring data privacy through distributed learning. Federated learning greatly reduces the risk of privacy breaches by training the model locally on each client and sharing only model parameters rather than raw data. The experiment verifies the high efficiency and privacy protection ability of federated learning under different data sources through the simulation of medical, financial, and user data. The results show that federated learning can not only maintain high model performance in a multi-domain data environment but also ensure effective protection of data privacy. The research in this paper provides a new technical path for cross-domain data collaboration and promotes the application of large-scale data analysis and machine learning while protecting privacy.
Dynamic Operating System Scheduling Using Double DQN: A Reinforcement Learning Approach to Task Optimization
Mar 31, 2025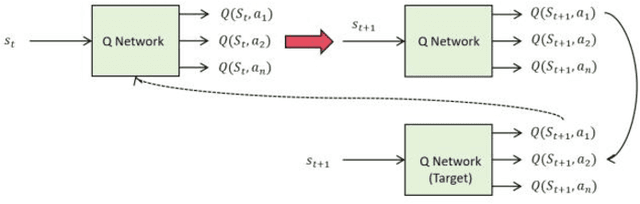


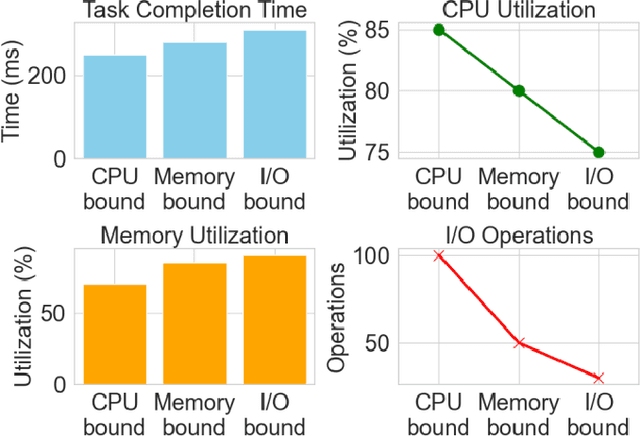
In this paper, an operating system scheduling algorithm based on Double DQN (Double Deep Q network) is proposed, and its performance under different task types and system loads is verified by experiments. Compared with the traditional scheduling algorithm, the algorithm based on Double DQN can dynamically adjust the task priority and resource allocation strategy, thus improving the task completion efficiency, system throughput, and response speed. The experimental results show that the Double DQN algorithm has high scheduling performance under light load, medium load and heavy load scenarios, especially when dealing with I/O intensive tasks, and can effectively reduce task completion time and system response time. In addition, the algorithm also shows high optimization ability in resource utilization and can intelligently adjust resource allocation according to the system state, avoiding resource waste and excessive load. Future studies will further explore the application of the algorithm in more complex systems, especially scheduling optimization in cloud computing and large-scale distributed environments, combining factors such as network latency and energy efficiency to improve the overall performance and adaptability of the algorithm.