 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Cross-Domain Data Privacy: A Distributed Approach to Secure Collaboration
Mar 31, 2025This paper proposes a data privacy protection framework based on federated learning, which aims to realize effective cross-domain data collaboration under the premise of ensuring data privacy through distributed learning. Federated learning greatly reduces the risk of privacy breaches by training the model locally on each client and sharing only model parameters rather than raw data. The experiment verifies the high efficiency and privacy protection ability of federated learning under different data sources through the simulation of medical, financial, and user data. The results show that federated learning can not only maintain high model performance in a multi-domain data environment but also ensure effective protection of data privacy. The research in this paper provides a new technical path for cross-domain data collaboration and promotes the application of large-scale data analysis and machine learning while protecting privacy.
Dynamic Operating System Scheduling Using Double DQN: A Reinforcement Learning Approach to Task Optimization
Mar 31, 2025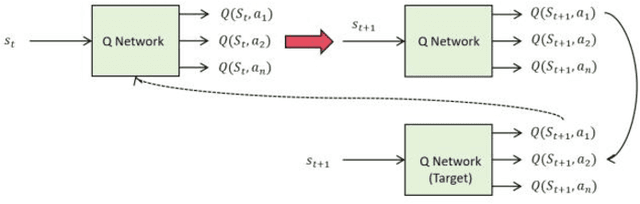


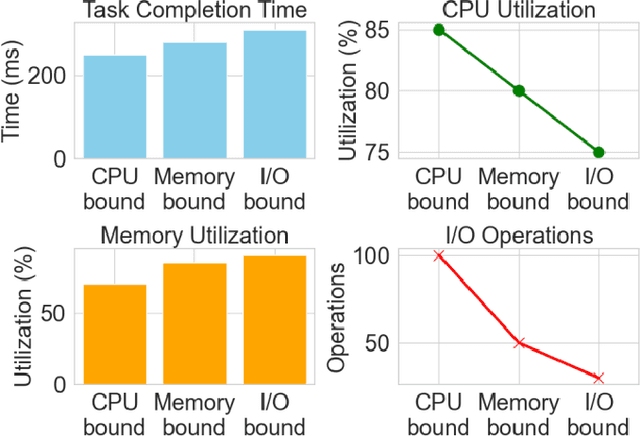
In this paper, an operating system scheduling algorithm based on Double DQN (Double Deep Q network) is proposed, and its performance under different task types and system loads is verified by experiments. Compared with the traditional scheduling algorithm, the algorithm based on Double DQN can dynamically adjust the task priority and resource allocation strategy, thus improving the task completion efficiency, system throughput, and response speed. The experimental results show that the Double DQN algorithm has high scheduling performance under light load, medium load and heavy load scenarios, especially when dealing with I/O intensive tasks, and can effectively reduce task completion time and system response time. In addition, the algorithm also shows high optimization ability in resource utilization and can intelligently adjust resource allocation according to the system state, avoiding resource waste and excessive load. Future studies will further explore the application of the algorithm in more complex systems, especially scheduling optimization in cloud computing and large-scale distributed environments, combining factors such as network latency and energy efficiency to improve the overall performance and adaptability of the algorithm.
Medical AI for Early Detection of Lung Cancer: A Survey
Oct 18, 2024



Lung cancer remains one of the leading causes of morbidity and mortality worldwide, making early diagnosis critical for improving therapeutic outcomes and patient prognosis. Computer-aided diagnosis (CAD) systems, which analyze CT images, have proven effective in detecting and classifying pulmonary nodules, significantly enhancing the detection rate of early-stage lung cancer. Although traditional machine learning algorithms have been valuable, they exhibit limitations in handling complex sample data. The recent emergence of deep learning has revolutionized medical image analysis, driving substantial advancements in this field. This review focuses on recent progress in deep learning for pulmonary nodule detection, segmentation, and classification. Traditional machine learning methods, such as SVM and KNN, have shown limitations, paving the way for advanced approaches like Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Generative Adversarial Networks (GAN). The integration of ensemble models and novel techniques is also discussed, emphasizing the latest developments in lung cancer diagnosis. Deep learning algorithms, combined with various analytical techniques, have markedly improved the accuracy and efficiency of pulmonary nodule analysis, surpassing traditional methods, particularly in nodule classification. Although challenges remain, continuous technological advancements are expected to further strengthen the role of deep learning in medical diagnostics, especially for early lung cancer detection and diagnosis. A comprehensive list of lung cancer detection models reviewed in this work is available at https://github.com/CaiGuoHui123/Awesome-Lung-Cancer-Detection
Efficient and Robust Knowledge Distillation from A Stronger Teacher Based on Correlation Matching
Oct 09, 2024



Knowledge Distillation (KD) has emerged as a pivotal technique for neural network compression and performance enhancement. Most KD methods aim to transfer dark knowledge from a cumbersome teacher model to a lightweight student model based on Kullback-Leibler (KL) divergence loss. However, the student performance improvements achieved through KD exhibit diminishing marginal returns, where a stronger teacher model does not necessarily lead to a proportionally stronger student model. To address this issue, we empirically find that the KL-based KD method may implicitly change the inter-class relationships learned by the student model, resulting in a more complex and ambiguous decision boundary, which in turn reduces the model's accuracy and generalization ability. Therefore, this study argues that the student model should learn not only the probability values from the teacher's output but also the relative ranking of classes, and proposes a novel Correlation Matching Knowledge Distillation (CMKD) method that combines the Pearson and Spearman correlation coefficients-based KD loss to achieve more efficient and robust distillation from a stronger teacher model. Moreover, considering that samples vary in difficulty, CMKD dynamically adjusts the weights of the Pearson-based loss and Spearman-based loss. CMKD is simple yet practical, and extensive experiments demonstrate that it can consistently achieve state-of-the-art performance on CIRAR-100 and ImageNet, and adapts well to various teacher architectures, sizes, and other KD methods.
MSDet: Receptive Field Enhanced Multiscale Detection for Tiny Pulmonary Nodule
Sep 21, 2024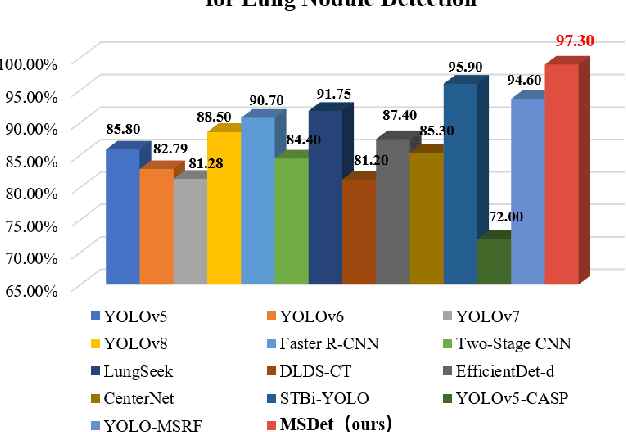
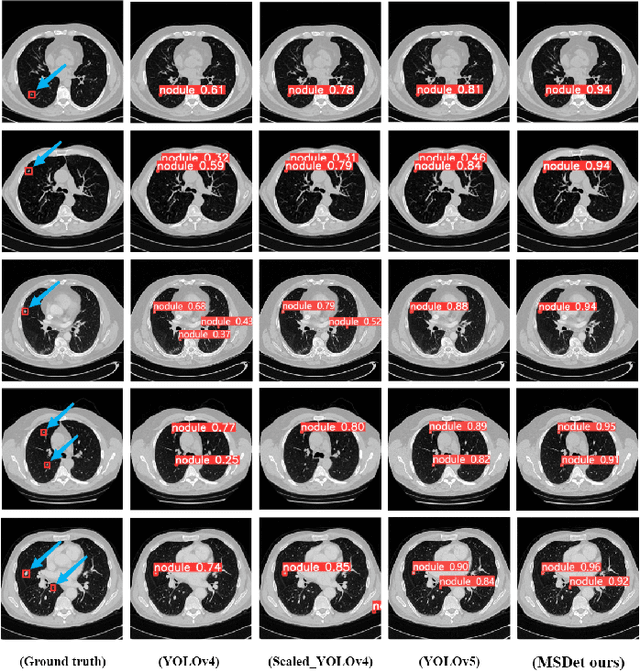
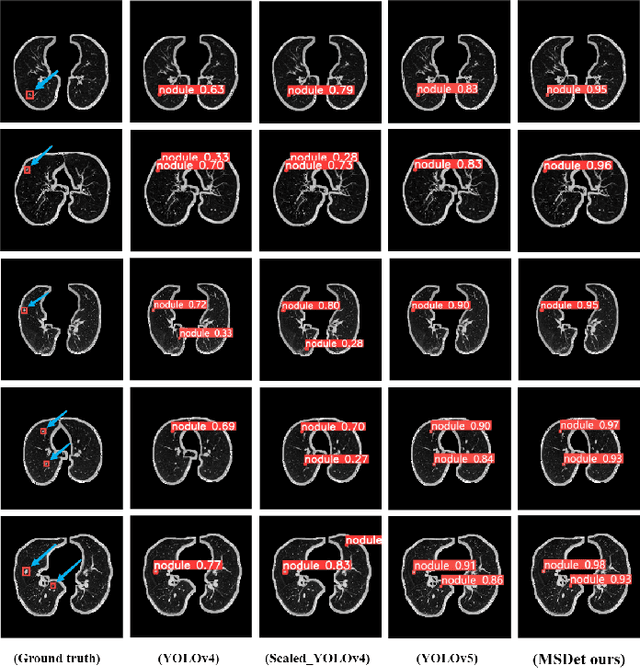
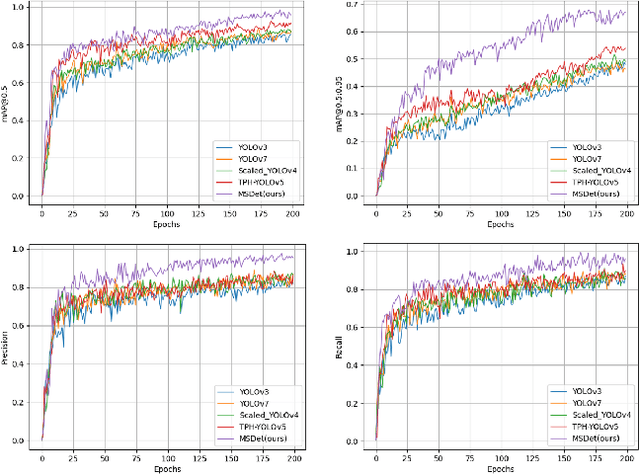
Pulmonary nodules are critical indicators for the early diagnosis of lung cancer, making their detection essential for timely treatment. However, traditional CT imaging methods suffered from cumbersome procedures, low detection rates, and poor localization accuracy. The subtle differences between pulmonary nodules and surrounding tissues in complex lung CT images, combined with repeated downsampling in feature extraction networks, often lead to missed or false detections of small nodules. Existing methods such as FPN, with its fixed feature fusion and limited receptive field, struggle to effectively overcome these issues. To address these challenges, our paper proposed three key contributions: Firstly, we proposed MSDet, a multiscale attention and receptive field network for detecting tiny pulmonary nodules. Secondly, we proposed the extended receptive domain (ERD) strategy to capture richer contextual information and reduce false positives caused by nodule occlusion. We also proposed the position channel attention mechanism (PCAM) to optimize feature learning and reduce multiscale detection errors, and designed the tiny object detection block (TODB) to enhance the detection of tiny nodules. Lastly, we conducted thorough experiments on the public LUNA16 dataset, achieving state-of-the-art performance, with an mAP improvement of 8.8% over the previous state-of-the-art method YOLOv8. These advancements significantly boosted detection accuracy and reliability, providing a more effective solution for early lung cancer diagnosis. The code will be available at https://github.com/CaiGuoHui123/MSDet