 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Progressive Self-Distillation with Logits Calibration for Personalized IIoT Edge Intelligence
Nov 30, 2024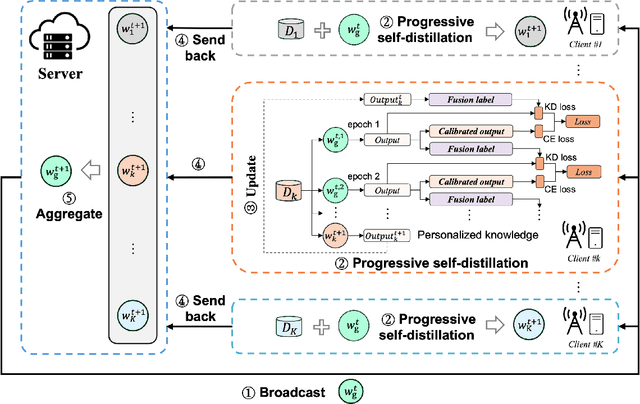



Personalized Federated Learning (PFL) focuses on tailoring models to individual IIoT clients in federated learning by addressing data heterogeneity and diverse user needs. Although existing studies have proposed effective PFL solutions from various perspectives, they overlook the issue of forgetting both historical personalized knowledge and global generalized knowledge during local training on clients. Therefore, this study proposes a novel PFL method, Federated Progressive Self-Distillation (FedPSD), based on logits calibration and progressive self-distillation. We analyze the impact mechanism of client data distribution characteristics on personalized and global knowledge forgetting. To address the issue of global knowledge forgetting, we propose a logits calibration approach for the local training loss and design a progressive self-distillation strategy to facilitate the gradual inheritance of global knowledge, where the model outputs from the previous epoch serve as virtual teachers to guide the training of subsequent epochs. Moreover, to address personalized knowledge forgetting, we construct calibrated fusion labels by integrating historical personalized model outputs, which are then used as teacher model outputs to guide the initial epoch of local self-distillation, enabling rapid recall of personalized knowledge. Extensive experiments under various data heterogeneity scenarios demonstrate the effectiveness and superiority of the proposed FedPSD method.
Efficient and Robust Knowledge Distillation from A Stronger Teacher Based on Correlation Matching
Oct 09, 2024



Knowledge Distillation (KD) has emerged as a pivotal technique for neural network compression and performance enhancement. Most KD methods aim to transfer dark knowledge from a cumbersome teacher model to a lightweight student model based on Kullback-Leibler (KL) divergence loss. However, the student performance improvements achieved through KD exhibit diminishing marginal returns, where a stronger teacher model does not necessarily lead to a proportionally stronger student model. To address this issue, we empirically find that the KL-based KD method may implicitly change the inter-class relationships learned by the student model, resulting in a more complex and ambiguous decision boundary, which in turn reduces the model's accuracy and generalization ability. Therefore, this study argues that the student model should learn not only the probability values from the teacher's output but also the relative ranking of classes, and proposes a novel Correlation Matching Knowledge Distillation (CMKD) method that combines the Pearson and Spearman correlation coefficients-based KD loss to achieve more efficient and robust distillation from a stronger teacher model. Moreover, considering that samples vary in difficulty, CMKD dynamically adjusts the weights of the Pearson-based loss and Spearman-based loss. CMKD is simple yet practical, and extensive experiments demonstrate that it can consistently achieve state-of-the-art performance on CIRAR-100 and ImageNet, and adapts well to various teacher architectures, sizes, and other KD methods.