 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG1: Teaching LLMs to Reason on Graphs with Reinforcement Learning
May 24, 2025Although Large Language Models (LLMs) have demonstrated remarkable progress, their proficiency in graph-related tasks remains notably limited, hindering the development of truly general-purpose models. Previous attempts, including pretraining graph foundation models or employing supervised fine-tuning, often face challenges such as the scarcity of large-scale, universally represented graph data. We introduce G1, a simple yet effective approach demonstrating that Reinforcement Learning (RL) on synthetic graph-theoretic tasks can significantly scale LLMs' graph reasoning abilities. To enable RL training, we curate Erd\~os, the largest graph reasoning dataset to date comprising 50 diverse graph-theoretic tasks of varying difficulty levels, 100k training data and 5k test data, all drived from real-world graphs. With RL on Erd\~os, G1 obtains substantial improvements in graph reasoning, where our finetuned 3B model even outperforms Qwen2.5-72B-Instruct (24x size). RL-trained models also show strong zero-shot generalization to unseen tasks, domains, and graph encoding schemes, including other graph-theoretic benchmarks as well as real-world node classification and link prediction tasks, without compromising general reasoning abilities. Our findings offer an efficient, scalable path for building strong graph reasoners by finetuning LLMs with RL on graph-theoretic tasks, which combines the strengths of pretrained LLM capabilities with abundant, automatically generated synthetic data, suggesting that LLMs possess graph understanding abilities that RL can elicit successfully.
A Deep Learning Approach to Anomaly Detection in High-Frequency Trading Data
Mar 31, 2025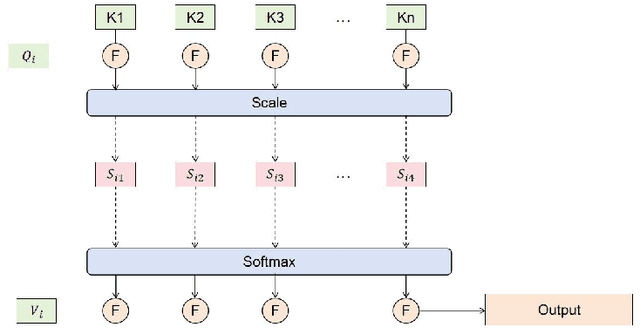
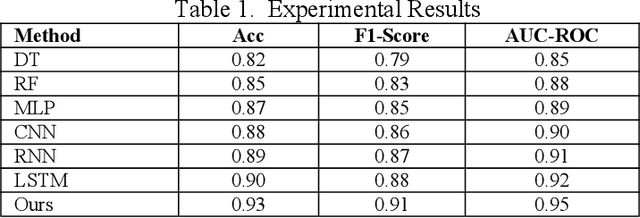
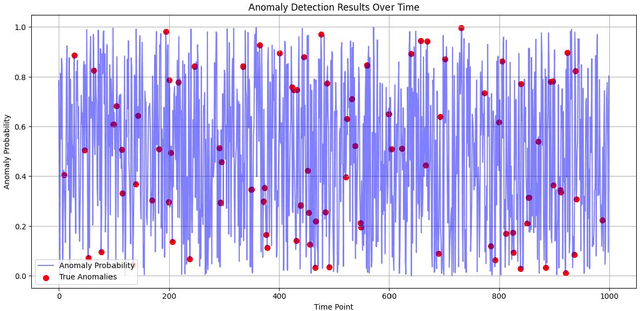
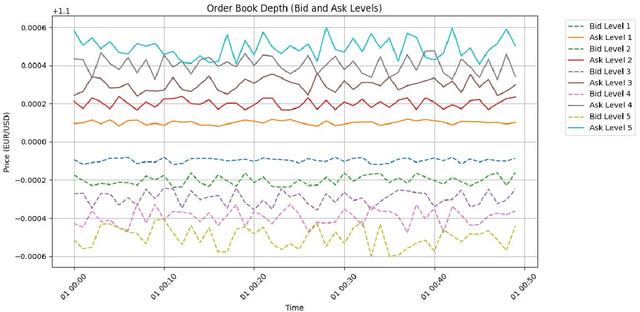
This paper proposes an algorithm based on a staged sliding window Transformer architecture to detect abnormal behaviors in the microstructure of the foreign exchange market, focusing on high-frequency EUR/USD trading data. The method captures multi-scale temporal features through a staged sliding window, extracts global and local dependencies by combining the self-attention mechanism and weighted attention mechanism of the Transformer, and uses a classifier to identify abnormal events. Experimental results on a real high-frequency dataset containing order book depth, spread, and trading volume show that the proposed method significantly outperforms traditional machine learning (such as decision trees and random forests) and deep learning methods (such as MLP, CNN, RNN, LSTM) in terms of accuracy (0.93), F1-Score (0.91), and AUC-ROC (0.95). Ablation experiments verify the contribution of each component, and the visualization of order book depth and anomaly detection further reveals the effectiveness of the model under complex market dynamics. Despite the false positive problem, the model still provides important support for market supervision. In the future, noise processing can be optimized and extended to other markets to improve generalization and real-time performance.
Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
Dec 23, 2024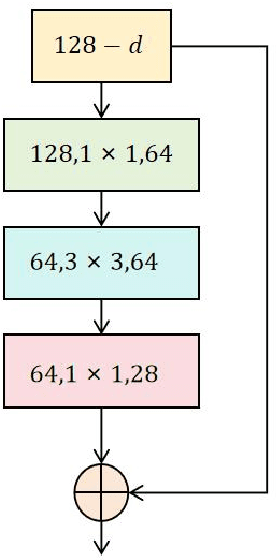

This study proposes a multi-task learning framework based on ResNeXt, aiming to solve the problem of feature extraction and task collaborative optimization in financial data mining. Financial data usually has the complex characteristics of high dimensionality, nonlinearity, and time series, and is accompanied by potential correlations between multiple tasks, making it difficult for traditional methods to meet the needs of data mining. This study introduces the ResNeXt model into the multi-task learning framework and makes full use of its group convolution mechanism to achieve efficient extraction of local patterns and global features of financial data. At the same time, through the design of task sharing layers and dedicated layers, it is established between multiple related tasks. Deep collaborative optimization relationships. Through flexible multi-task loss weight design, the model can effectively balance the learning needs of different tasks and improve overall performance. Experiments are conducted on a real S&P 500 financial data set, verifying the significant advantages of the proposed framework in classification and regression tasks. The results indicate that, when compared to other conventional deep learning models, the proposed method delivers superior performance in terms of accuracy, F1 score, root mean square error, and other metrics, highlighting its outstanding effectiveness and robustness in handling complex financial data. This research provides an efficient and adaptable solution for financial data mining, and at the same time opens up a new research direction for the combination of multi-task learning and deep learning, which has important theoretical significance and practical application value.
Architecture Matters: Uncovering Implicit Mechanisms in Graph Contrastive Learning
Nov 05, 2023With the prosperity of contrastive learning for visual representation learning (VCL), it is also adapted to the graph domain and yields promising performance. However, through a systematic study of various graph contrastive learning (GCL) methods, we observe that some common phenomena among existing GCL methods that are quite different from the original VCL methods, including 1) positive samples are not a must for GCL; 2) negative samples are not necessary for graph classification, neither for node classification when adopting specific normalization modules; 3) data augmentations have much less influence on GCL, as simple domain-agnostic augmentations (e.g., Gaussian noise) can also attain fairly good performance. By uncovering how the implicit inductive bias of GNNs works in contrastive learning, we theoretically provide insights into the above intriguing properties of GCL. Rather than directly porting existing VCL methods to GCL, we advocate for more attention toward the unique architecture of graph learning and consider its implicit influence when designing GCL methods. Code is available at https: //github.com/PKU-ML/ArchitectureMattersGCL.
ContraNorm: A Contrastive Learning Perspective on Oversmoothing and Beyond
Mar 12, 2023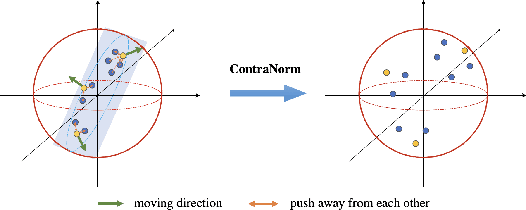
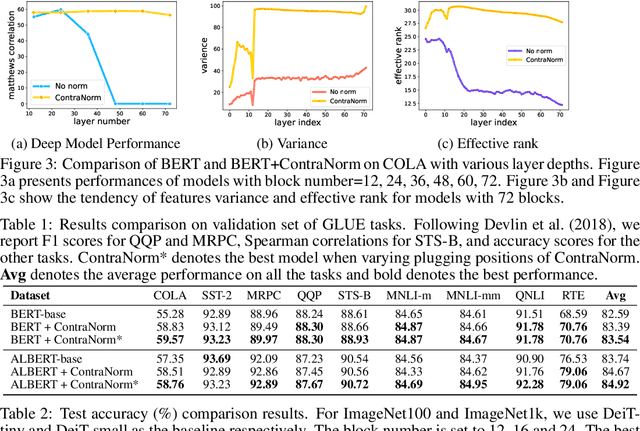
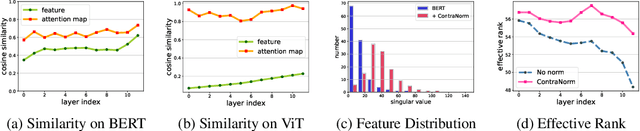
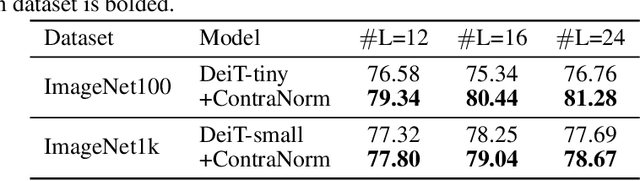
Oversmoothing is a common phenomenon in a wide range of Graph Neural Networks (GNNs) and Transformers, where performance worsens as the number of layers increases. Instead of characterizing oversmoothing from the view of complete collapse in which representations converge to a single point, we dive into a more general perspective of dimensional collapse in which representations lie in a narrow cone. Accordingly, inspired by the effectiveness of contrastive learning in preventing dimensional collapse, we propose a novel normalization layer called ContraNorm. Intuitively, ContraNorm implicitly shatters representations in the embedding space, leading to a more uniform distribution and a slighter dimensional collapse. On the theoretical analysis, we prove that ContraNorm can alleviate both complete collapse and dimensional collapse under certain conditions. Our proposed normalization layer can be easily integrated into GNNs and Transformers with negligible parameter overhead. Experiments on various real-world datasets demonstrate the effectiveness of our proposed ContraNorm. Our implementation is available at https://github.com/PKU-ML/ContraNorm.