 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraNorm: A Contrastive Learning Perspective on Oversmoothing and Beyond
Paper and Code
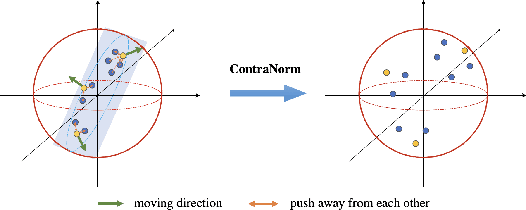
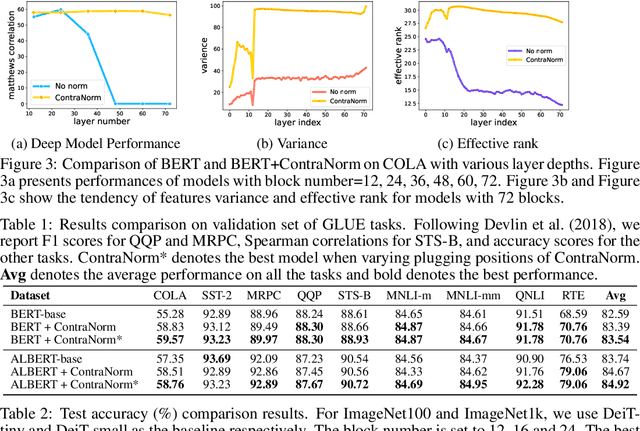
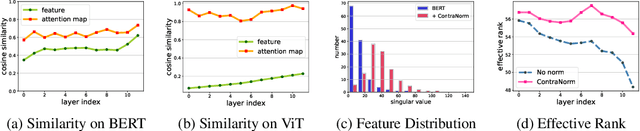
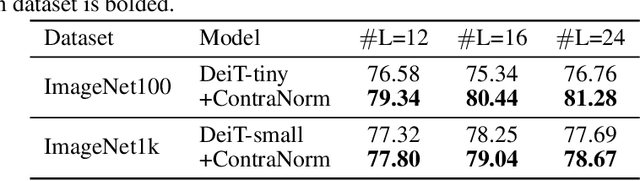
Oversmoothing is a common phenomenon in a wide range of Graph Neural Networks (GNNs) and Transformers, where performance worsens as the number of layers increases. Instead of characterizing oversmoothing from the view of complete collapse in which representations converge to a single point, we dive into a more general perspective of dimensional collapse in which representations lie in a narrow cone. Accordingly, inspired by the effectiveness of contrastive learning in preventing dimensional collapse, we propose a novel normalization layer called ContraNorm. Intuitively, ContraNorm implicitly shatters representations in the embedding space, leading to a more uniform distribution and a slighter dimensional collapse. On the theoretical analysis, we prove that ContraNorm can alleviate both complete collapse and dimensional collapse under certain conditions. Our proposed normalization layer can be easily integrated into GNNs and Transformers with negligible parameter overhead. Experiments on various real-world datasets demonstrate the effectiveness of our proposed ContraNorm. Our implementation is available at https://github.com/PKU-ML/ContraNorm.