 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Models Rival Diffusion Models at ANY-ORDER Generation
Jan 19, 2026Diffusion language models enable any-order generation and bidirectional conditioning, offering appealing flexibility for tasks such as infilling, rewriting, and self-correction. However, their formulation-predicting one part of a sequence from another within a single-step dependency-limits modeling depth and often yields lower sample quality and stability than autoregressive (AR) models. To address this, we revisit autoregressive modeling as a foundation and reformulate diffusion-style training into a structured multi-group prediction process. We propose Any-order Any-subset Autoregressive modeling (A3), a generalized framework that extends the standard AR factorization to arbitrary token groups and generation orders. A3 preserves the probabilistic rigor and multi-layer dependency modeling of AR while inheriting diffusion models' flexibility for parallel and bidirectional generation. We implement A3 through a two-stream attention architecture and a progressive adaptation strategy that transitions pretrained AR models toward any-order prediction. Experiments on question answering, commonsense reasoning, and story infilling demonstrate that A3 outperforms diffusion-based models while maintaining flexible decoding. This work offers a unified approach for a flexible, efficient, and novel language modeling paradigm.
Long-Short Alignment for Effective Long-Context Modeling in LLMs
Jun 13, 2025Large language models (LLMs) have exhibited impressive performance and surprising emergent properties. However, their effectiveness remains limited by the fixed context window of the transformer architecture, posing challenges for long-context modeling. Among these challenges, length generalization -- the ability to generalize to sequences longer than those seen during training -- is a classical and fundamental problem. In this work, we propose a fresh perspective on length generalization, shifting the focus from the conventional emphasis on input features such as positional encodings or data structures to the output distribution of the model. Specifically, through case studies on synthetic tasks, we highlight the critical role of \textbf{long-short alignment} -- the consistency of output distributions across sequences of varying lengths. Extending this insight to natural language tasks, we propose a metric called Long-Short Misalignment to quantify this phenomenon, uncovering a strong correlation between the metric and length generalization performance. Building on these findings, we develop a regularization term that promotes long-short alignment during training. Extensive experiments validate the effectiveness of our approach, offering new insights for achieving more effective long-context modeling in LLMs. Code is available at https://github.com/PKU-ML/LongShortAlignment.
Advancing LLM Safe Alignment with Safety Representation Ranking
May 21, 2025The rapid advancement of large language models (LLMs) has demonstrated milestone success in a variety of tasks, yet their potential for generating harmful content has raised significant safety concerns. Existing safety evaluation approaches typically operate directly on textual responses, overlooking the rich information embedded in the model's internal representations. In this paper, we propose Safety Representation Ranking (SRR), a listwise ranking framework that selects safe responses using hidden states from the LLM itself. SRR encodes both instructions and candidate completions using intermediate transformer representations and ranks candidates via a lightweight similarity-based scorer. Our approach directly leverages internal model states and supervision at the list level to capture subtle safety signals. Experiments across multiple benchmarks show that SRR significantly improves robustness to adversarial prompts. Our code will be available upon publication.
When More is Less: Understanding Chain-of-Thought Length in LLMs
Feb 11, 2025



Chain-of-thought (CoT) reasoning enhances the multi-step reasoning capabilities of large language models (LLMs) by breaking complex tasks into smaller, manageable sub-tasks. Researchers have been exploring ways to guide models to generate more complex CoT processes to improve the reasoning ability of LLMs, such as long CoT and the test-time scaling law. However, for most models and tasks, does an increase in CoT length consistently lead to improved reasoning accuracy? In this paper, we observe a nuanced relationship: as the number of reasoning steps increases, performance initially improves but eventually decreases. To understand this phenomenon, we provide a piece of evidence that longer reasoning processes are increasingly susceptible to noise. We theoretically prove the existence of an optimal CoT length and derive a scaling law for this optimal length based on model capability and task difficulty. Inspired by our theory, we conduct experiments on both synthetic and real world datasets and propose Length-filtered Vote to alleviate the effects of excessively long or short CoTs. Our findings highlight the critical need to calibrate CoT length to align with model capabilities and task demands, offering a principled framework for optimizing multi-step reasoning in LLMs.
On the Role of Discrete Tokenization in Visual Representation Learning
Jul 12, 2024In the realm of self-supervised learning (SSL), masked image modeling (MIM) has gained popularity alongside contrastive learning methods. MIM involves reconstructing masked regions of input images using their unmasked portions. A notable subset of MIM methodologies employs discrete tokens as the reconstruction target, but the theoretical underpinnings of this choice remain underexplored. In this paper, we explore the role of these discrete tokens, aiming to unravel their benefits and limitations. Building upon the connection between MIM and contrastive learning, we provide a comprehensive theoretical understanding on how discrete tokenization affects the model's generalization capabilities. Furthermore, we propose a novel metric named TCAS, which is specifically designed to assess the effectiveness of discrete tokens within the MIM framework. Inspired by this metric, we contribute an innovative tokenizer design and propose a corresponding MIM method named ClusterMIM. It demonstrates superior performance on a variety of benchmark datasets and ViT backbones. Code is available at https://github.com/PKU-ML/ClusterMIM.
Look Ahead or Look Around? A Theoretical Comparison Between Autoregressive and Masked Pretraining
Jul 01, 2024


In recent years, the rise of generative self-supervised learning (SSL) paradigms has exhibited impressive performance across visual, language, and multi-modal domains. While the varied designs of generative SSL objectives lead to distinct properties in downstream tasks, a theoretical understanding of these differences remains largely unexplored. In this paper, we establish the first theoretical comparisons between two leading generative SSL paradigms: autoregressive SSL and masked SSL. Through establishing theoretical frameworks, we elucidate the strengths and limitations of autoregressive and masked SSL within the primary evaluation tasks of classification and content generation. Our findings demonstrate that in classification tasks, the flexibility of targeted tokens in masked SSL fosters more inter-sample connections compared to the fixed position of target tokens in autoregressive SSL, which yields superior clustering performance. In content generation tasks, the misalignment between the flexible lengths of test samples and the fixed length of unmasked texts in masked SSL (vs. flexible lengths of conditional texts in autoregressive SSL) hinders its generation performance. To leverage each other's strengths and mitigate weaknesses, we propose diversity-enhanced autoregressive and variable-length masked objectives, which substantially improve the classification performance of autoregressive SSL and the generation performance of masked SSL. Code is available at https://github.com/PKU-ML/LookAheadLookAround.
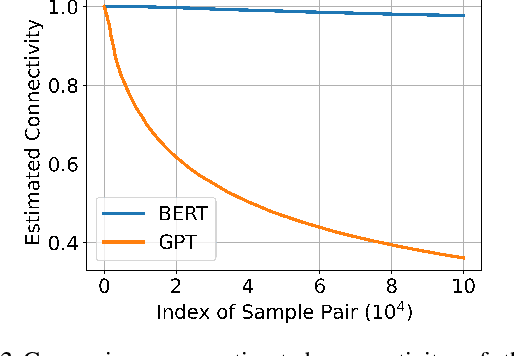
ContraNorm: A Contrastive Learning Perspective on Oversmoothing and Beyond
Mar 12, 2023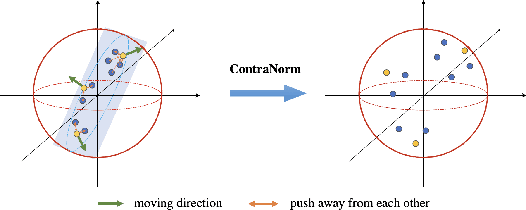
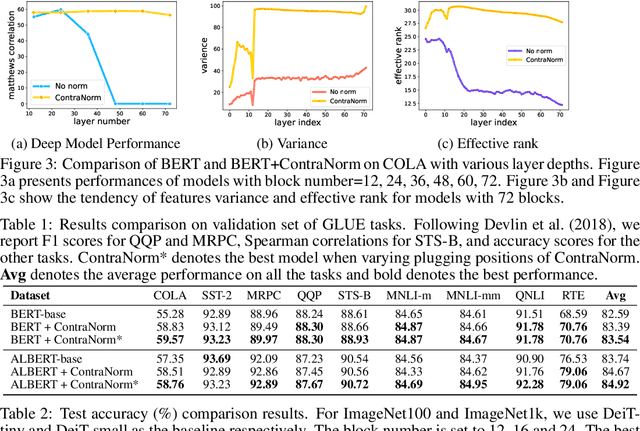
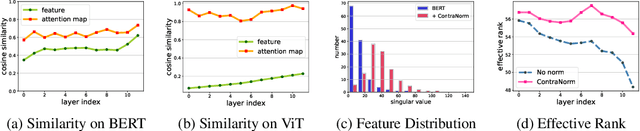
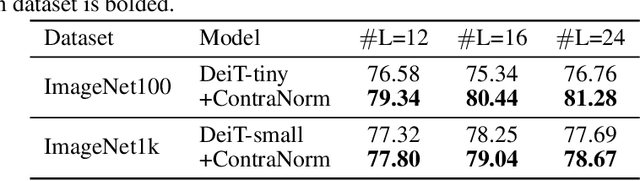
Oversmoothing is a common phenomenon in a wide range of Graph Neural Networks (GNNs) and Transformers, where performance worsens as the number of layers increases. Instead of characterizing oversmoothing from the view of complete collapse in which representations converge to a single point, we dive into a more general perspective of dimensional collapse in which representations lie in a narrow cone. Accordingly, inspired by the effectiveness of contrastive learning in preventing dimensional collapse, we propose a novel normalization layer called ContraNorm. Intuitively, ContraNorm implicitly shatters representations in the embedding space, leading to a more uniform distribution and a slighter dimensional collapse. On the theoretical analysis, we prove that ContraNorm can alleviate both complete collapse and dimensional collapse under certain conditions. Our proposed normalization layer can be easily integrated into GNNs and Transformers with negligible parameter overhead. Experiments on various real-world datasets demonstrate the effectiveness of our proposed ContraNorm. Our implementation is available at https://github.com/PKU-ML/ContraNorm.
A Message Passing Perspective on Learning Dynamics of Contrastive Learning
Mar 08, 2023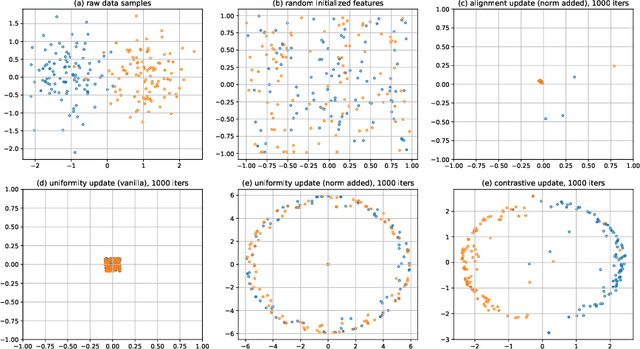

In recent years, contrastive learning achieves impressive results on self-supervised visual representation learning, but there still lacks a rigorous understanding of its learning dynamics. In this paper, we show that if we cast a contrastive objective equivalently into the feature space, then its learning dynamics admits an interpretable form. Specifically, we show that its gradient descent corresponds to a specific message passing scheme on the corresponding augmentation graph. Based on this perspective, we theoretically characterize how contrastive learning gradually learns discriminative features with the alignment update and the uniformity update. Meanwhile, this perspective also establishes an intriguing connection between contrastive learning and Message Passing Graph Neural Networks (MP-GNNs). This connection not only provides a unified understanding of many techniques independently developed in each community, but also enables us to borrow techniques from MP-GNNs to design new contrastive learning variants, such as graph attention, graph rewiring, jumpy knowledge techniques, etc. We believe that our message passing perspective not only provides a new theoretical understanding of contrastive learning dynamics, but also bridges the two seemingly independent areas together, which could inspire more interleaving studies to benefit from each other. The code is available at https://github.com/PKU-ML/Message-Passing-Contrastive-Learning.
ArCL: Enhancing Contrastive Learning with Augmentation-Robust Representations
Mar 02, 2023



Self-Supervised Learning (SSL) is a paradigm that leverages unlabeled data for model training. Empirical studies show that SSL can achieve promising performance in distribution shift scenarios, where the downstream and training distributions differ. However, the theoretical understanding of its transferability remains limited. In this paper, we develop a theoretical framework to analyze the transferability of self-supervised contrastive learning, by investigating the impact of data augmentation on it. Our results reveal that the downstream performance of contrastive learning depends largely on the choice of data augmentation. Moreover, we show that contrastive learning fails to learn domain-invariant features, which limits its transferability. Based on these theoretical insights, we propose a novel method called Augmentation-robust Contrastive Learning (ArCL), which guarantees to learn domain-invariant features and can be easily integrated with existing contrastive learning algorithms. We conduct experiments on several datasets and show that ArCL significantly improves the transferability of contrastive learning.