 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Models Rival Diffusion Models at ANY-ORDER Generation
Jan 19, 2026Diffusion language models enable any-order generation and bidirectional conditioning, offering appealing flexibility for tasks such as infilling, rewriting, and self-correction. However, their formulation-predicting one part of a sequence from another within a single-step dependency-limits modeling depth and often yields lower sample quality and stability than autoregressive (AR) models. To address this, we revisit autoregressive modeling as a foundation and reformulate diffusion-style training into a structured multi-group prediction process. We propose Any-order Any-subset Autoregressive modeling (A3), a generalized framework that extends the standard AR factorization to arbitrary token groups and generation orders. A3 preserves the probabilistic rigor and multi-layer dependency modeling of AR while inheriting diffusion models' flexibility for parallel and bidirectional generation. We implement A3 through a two-stream attention architecture and a progressive adaptation strategy that transitions pretrained AR models toward any-order prediction. Experiments on question answering, commonsense reasoning, and story infilling demonstrate that A3 outperforms diffusion-based models while maintaining flexible decoding. This work offers a unified approach for a flexible, efficient, and novel language modeling paradigm.
Advancing LLM Safe Alignment with Safety Representation Ranking
May 21, 2025The rapid advancement of large language models (LLMs) has demonstrated milestone success in a variety of tasks, yet their potential for generating harmful content has raised significant safety concerns. Existing safety evaluation approaches typically operate directly on textual responses, overlooking the rich information embedded in the model's internal representations. In this paper, we propose Safety Representation Ranking (SRR), a listwise ranking framework that selects safe responses using hidden states from the LLM itself. SRR encodes both instructions and candidate completions using intermediate transformer representations and ranks candidates via a lightweight similarity-based scorer. Our approach directly leverages internal model states and supervision at the list level to capture subtle safety signals. Experiments across multiple benchmarks show that SRR significantly improves robustness to adversarial prompts. Our code will be available upon publication.
What is Wrong with Perplexity for Long-context Language Modeling?
Oct 31, 2024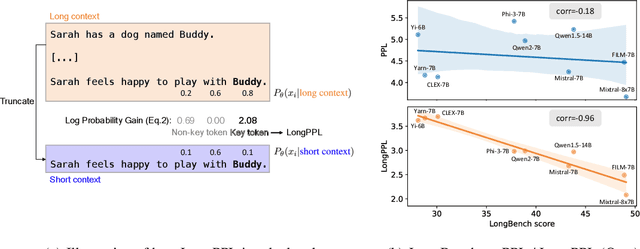

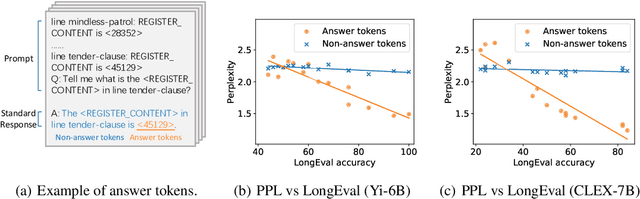
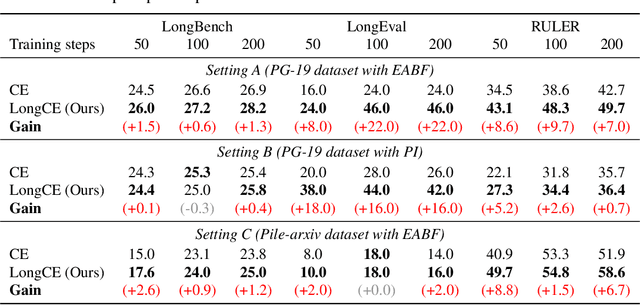
Handling long-context inputs is crucial for large language models (LLMs) in tasks such as extended conversations, document summarization, and many-shot in-context learning. While recent approaches have extended the context windows of LLMs and employed perplexity (PPL) as a standard evaluation metric, PPL has proven unreliable for assessing long-context capabilities. The underlying cause of this limitation has remained unclear. In this work, we provide a comprehensive explanation for this issue. We find that PPL overlooks key tokens, which are essential for long-context understanding, by averaging across all tokens and thereby obscuring the true performance of models in long-context scenarios. To address this, we propose \textbf{LongPPL}, a novel metric that focuses on key tokens by employing a long-short context contrastive method to identify them. Our experiments demonstrate that LongPPL strongly correlates with performance on various long-context benchmarks (e.g., Pearson correlation of -0.96), significantly outperforming traditional PPL in predictive accuracy. Additionally, we introduce \textbf{LongCE} (Long-context Cross-Entropy) loss, a re-weighting strategy for fine-tuning that prioritizes key tokens, leading to consistent improvements across diverse benchmarks. In summary, these contributions offer deeper insights into the limitations of PPL and present effective solutions for accurately evaluating and enhancing the long-context capabilities of LLMs. Code is available at https://github.com/PKU-ML/LongPPL.