 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Distributional Temporal Difference Learning with Linear Function Approximation
Nov 16, 2025
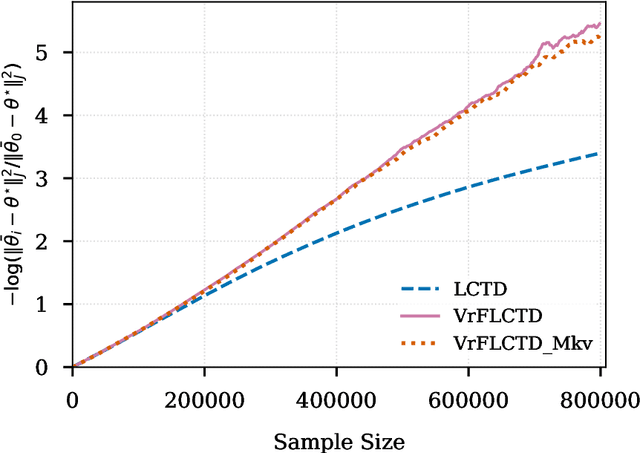
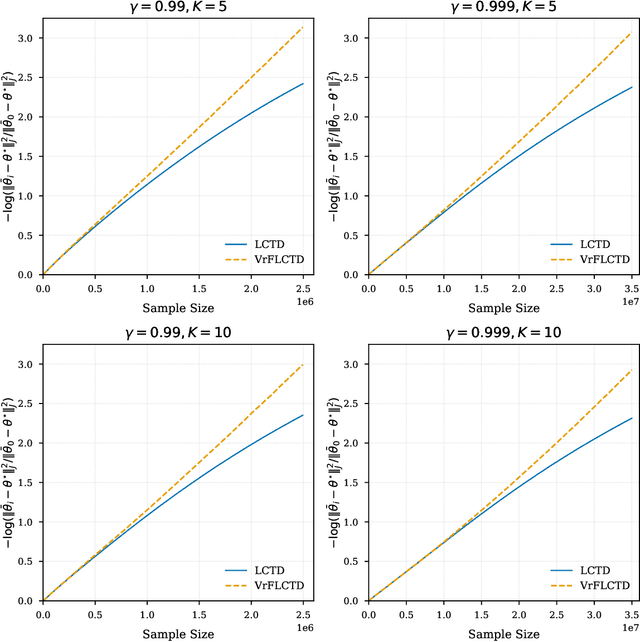
In this paper, we study the finite-sample statistical rates of distributional temporal difference (TD) learning with linear function approximation. The purpose of distributional TD learning is to estimate the return distribution of a discounted Markov decision process for a given policy. Previous works on statistical analysis of distributional TD learning focus mainly on the tabular case. We first consider the linear function approximation setting and conduct a fine-grained analysis of the linear-categorical Bellman equation. Building on this analysis, we further incorporate variance reduction techniques in our new algorithms to establish tight sample complexity bounds independent of the support size $K$ when $K$ is large. Our theoretical results imply that, when employing distributional TD learning with linear function approximation, learning the full distribution of the return function from streaming data is no more difficult than learning its expectation. This work provide new insights into the statistical efficiency of distributional reinforcement learning algorithms.
Random Feature Models with Learnable Activation Functions
Nov 29, 2024Current random feature models typically rely on fixed activation functions, limiting their ability to capture diverse patterns in data. To address this, we introduce the Random Feature model with Learnable Activation Functions (RFLAF), a novel model that significantly enhances the expressivity and interpretability of traditional random feature (RF) models. We begin by studying the RF model with a single radial basis function, where we discover a new kernel and provide the first theoretical analysis on it. By integrating the basis functions with learnable weights, we show that RFLAF can represent a broad class of random feature models whose activation functions belong in $C_c(\mathbb{R})$. Theoretically, we prove that the model requires only about twice the parameter number compared to a traditional RF model to achieve the significant leap in expressivity. Experimentally, RFLAF demonstrates two key advantages: (1) it performs better across various tasks compared to traditional RF model with the same number of parameters, and (2) the optimized weights offer interpretability, as the learned activation function can be directly inferred from these weights. Our model paves the way for developing more expressive and interpretable frameworks within random feature models.
Balance, Imbalance, and Rebalance: Understanding Robust Overfitting from a Minimax Game Perspective
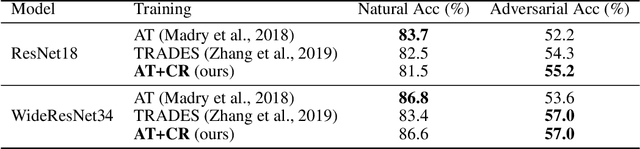
Oct 30, 2023Adversarial Training (AT) has become arguably the state-of-the-art algorithm for extracting robust features. However, researchers recently notice that AT suffers from severe robust overfitting problems, particularly after learning rate (LR) decay. In this paper, we explain this phenomenon by viewing adversarial training as a dynamic minimax game between the model trainer and the attacker. Specifically, we analyze how LR decay breaks the balance between the minimax game by empowering the trainer with a stronger memorization ability, and show such imbalance induces robust overfitting as a result of memorizing non-robust features. We validate this understanding with extensive experiments, and provide a holistic view of robust overfitting from the dynamics of both the two game players. This understanding further inspires us to alleviate robust overfitting by rebalancing the two players by either regularizing the trainer's capacity or improving the attack strength. Experiments show that the proposed ReBalanced Adversarial Training (ReBAT) can attain good robustness and does not suffer from robust overfitting even after very long training. Code is available at https://github.com/PKU-ML/ReBAT.
A Message Passing Perspective on Learning Dynamics of Contrastive Learning
Mar 08, 2023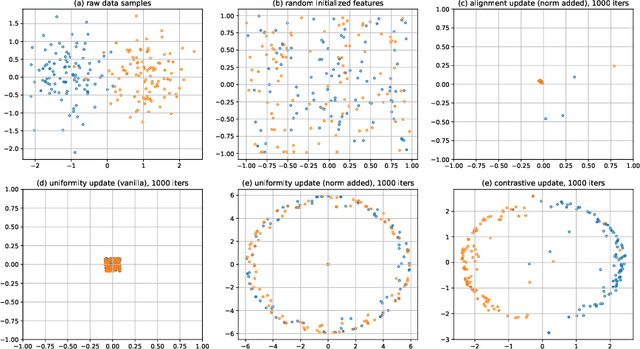

In recent years, contrastive learning achieves impressive results on self-supervised visual representation learning, but there still lacks a rigorous understanding of its learning dynamics. In this paper, we show that if we cast a contrastive objective equivalently into the feature space, then its learning dynamics admits an interpretable form. Specifically, we show that its gradient descent corresponds to a specific message passing scheme on the corresponding augmentation graph. Based on this perspective, we theoretically characterize how contrastive learning gradually learns discriminative features with the alignment update and the uniformity update. Meanwhile, this perspective also establishes an intriguing connection between contrastive learning and Message Passing Graph Neural Networks (MP-GNNs). This connection not only provides a unified understanding of many techniques independently developed in each community, but also enables us to borrow techniques from MP-GNNs to design new contrastive learning variants, such as graph attention, graph rewiring, jumpy knowledge techniques, etc. We believe that our message passing perspective not only provides a new theoretical understanding of contrastive learning dynamics, but also bridges the two seemingly independent areas together, which could inspire more interleaving studies to benefit from each other. The code is available at https://github.com/PKU-ML/Message-Passing-Contrastive-Learning.
Optimization-Induced Graph Implicit Nonlinear Diffusion
Jun 29, 2022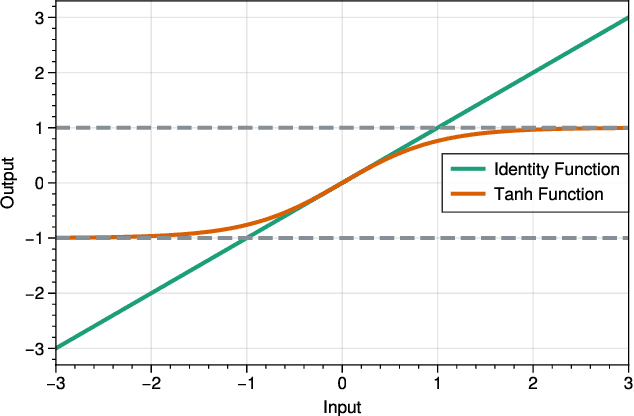
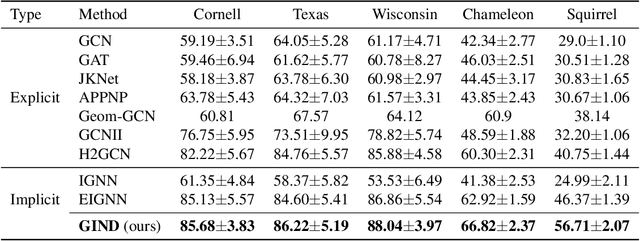
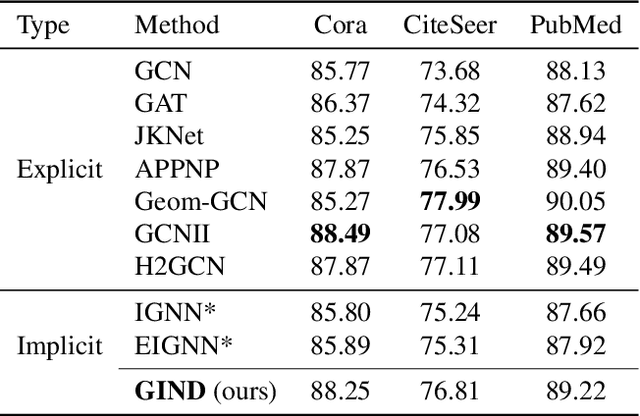
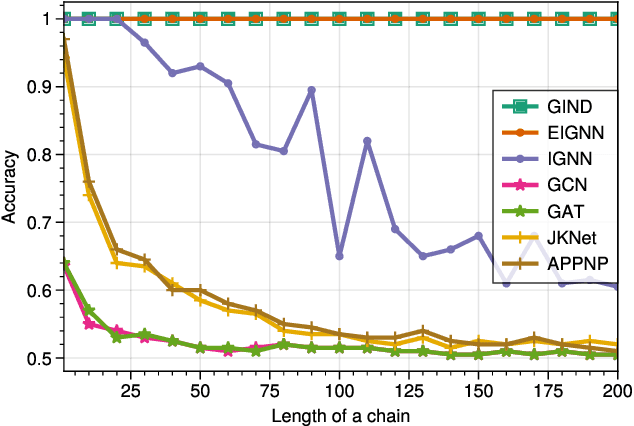
Due to the over-smoothing issue, most existing graph neural networks can only capture limited dependencies with their inherently finite aggregation layers. To overcome this limitation, we propose a new kind of graph convolution, called Graph Implicit Nonlinear Diffusion (GIND), which implicitly has access to infinite hops of neighbors while adaptively aggregating features with nonlinear diffusion to prevent over-smoothing. Notably, we show that the learned representation can be formalized as the minimizer of an explicit convex optimization objective. With this property, we can theoretically characterize the equilibrium of our GIND from an optimization perspective. More interestingly, we can induce new structural variants by modifying the corresponding optimization objective. To be specific, we can embed prior properties to the equilibrium, as well as introducing skip connections to promote training stability. Extensive experiments show that GIND is good at capturing long-range dependencies, and performs well on both homophilic and heterophilic graphs with nonlinear diffusion. Moreover, we show that the optimization-induced variants of our models can boost the performance and improve training stability and efficiency as well. As a result, our GIND obtains significant improvements on both node-level and graph-level tasks.
Chaos is a Ladder: A New Theoretical Understanding of Contrastive Learning via Augmentation Overlap
Mar 25, 2022
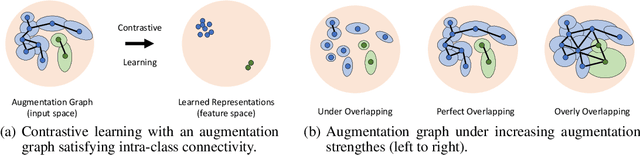
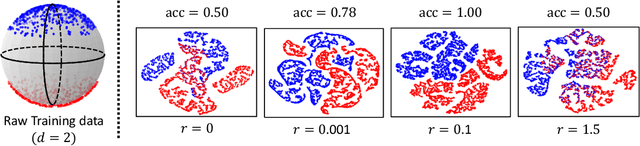
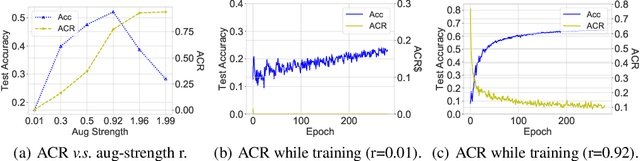
Recently, contrastive learning has risen to be a promising approach for large-scale self-supervised learning. However, theoretical understanding of how it works is still unclear. In this paper, we propose a new guarantee on the downstream performance without resorting to the conditional independence assumption that is widely adopted in previous work but hardly holds in practice. Our new theory hinges on the insight that the support of different intra-class samples will become more overlapped under aggressive data augmentations, thus simply aligning the positive samples (augmented views of the same sample) could make contrastive learning cluster intra-class samples together. Based on this augmentation overlap perspective, theoretically, we obtain asymptotically closed bounds for downstream performance under weaker assumptions, and empirically, we propose an unsupervised model selection metric ARC that aligns well with downstream accuracy. Our theory suggests an alternative understanding of contrastive learning: the role of aligning positive samples is more like a surrogate task than an ultimate goal, and the overlapped augmented views (i.e., the chaos) create a ladder for contrastive learning to gradually learn class-separated representations. The code for computing ARC is available at https://github.com/zhangq327/ARC.
A Unified Contrastive Energy-based Model for Understanding the Generative Ability of Adversarial Training
Mar 25, 2022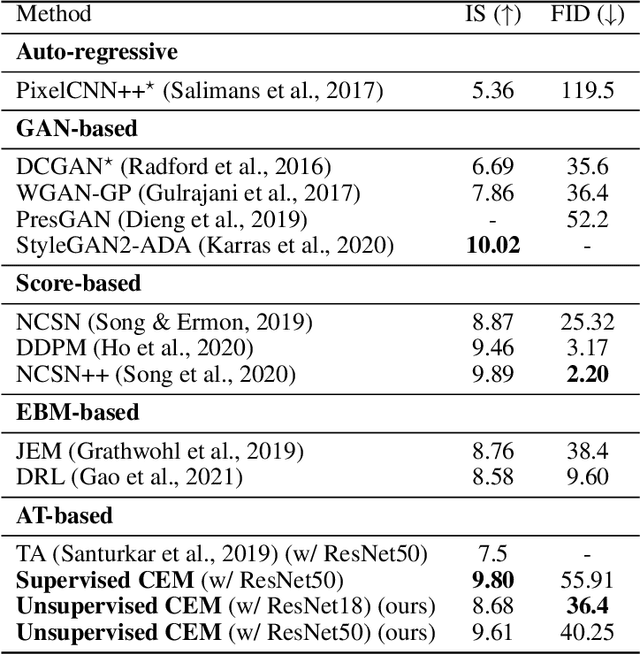
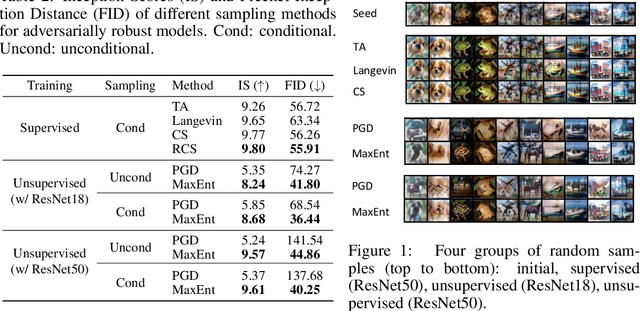
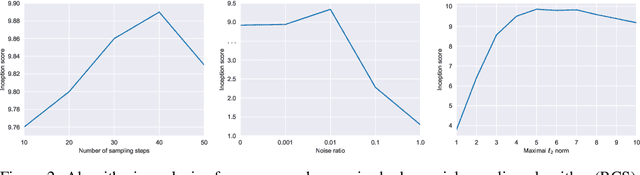
Adversarial Training (AT) is known as an effective approach to enhance the robustness of deep neural networks. Recently researchers notice that robust models with AT have good generative ability and can synthesize realistic images, while the reason behind it is yet under-explored. In this paper, we demystify this phenomenon by developing a unified probabilistic framework, called Contrastive Energy-based Models (CEM). On the one hand, we provide the first probabilistic characterization of AT through a unified understanding of robustness and generative ability. On the other hand, our unified framework can be extended to the unsupervised scenario, which interprets unsupervised contrastive learning as an important sampling of CEM. Based on these, we propose a principled method to develop adversarial learning and sampling methods. Experiments show that the sampling methods derived from our framework improve the sample quality in both supervised and unsupervised learning. Notably, our unsupervised adversarial sampling method achieves an Inception score of 9.61 on CIFAR-10, which is superior to previous energy-based models and comparable to state-of-the-art generative models.
Residual Relaxation for Multi-view Representation Learning
Oct 28, 2021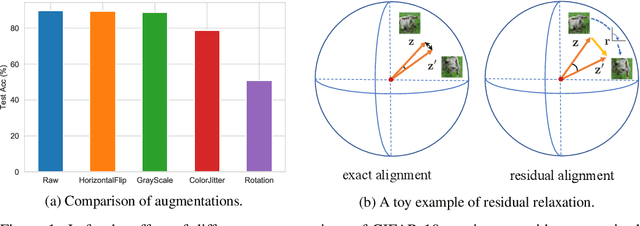
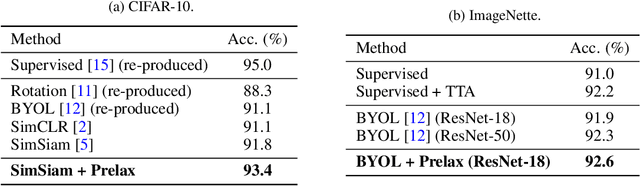
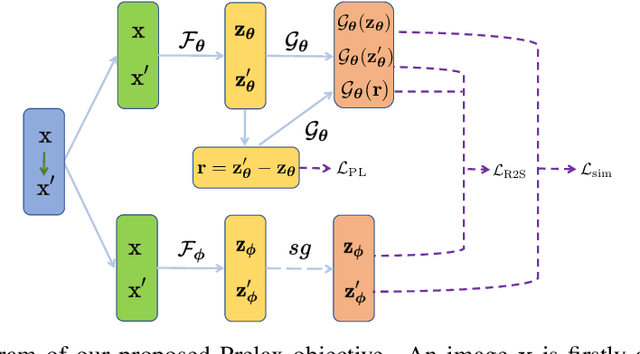
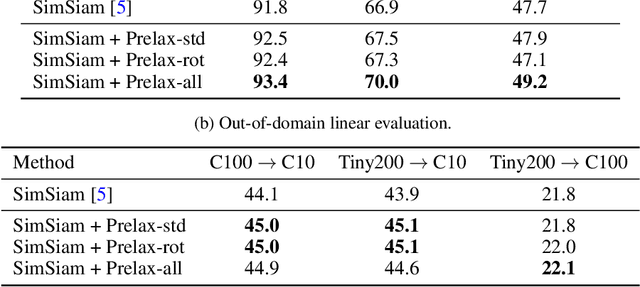
Multi-view methods learn representations by aligning multiple views of the same image and their performance largely depends on the choice of data augmentation. In this paper, we notice that some other useful augmentations, such as image rotation, are harmful for multi-view methods because they cause a semantic shift that is too large to be aligned well. This observation motivates us to relax the exact alignment objective to better cultivate stronger augmentations. Taking image rotation as a case study, we develop a generic approach, Pretext-aware Residual Relaxation (Prelax), that relaxes the exact alignment by allowing an adaptive residual vector between different views and encoding the semantic shift through pretext-aware learning. Extensive experiments on different backbones show that our method can not only improve multi-view methods with existing augmentations, but also benefit from stronger image augmentations like rotation.
Reparameterized Sampling for Generative Adversarial Networks
Jul 01, 2021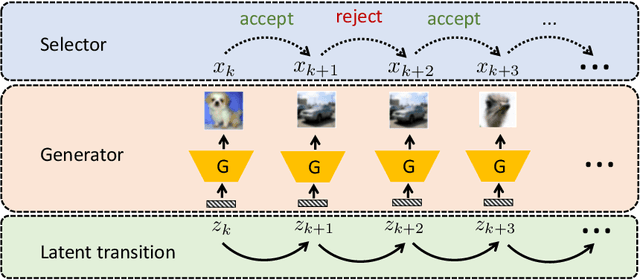
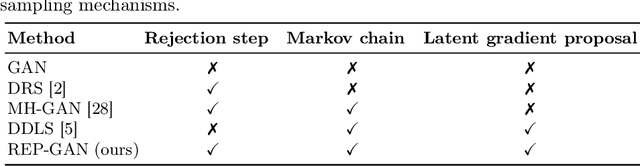
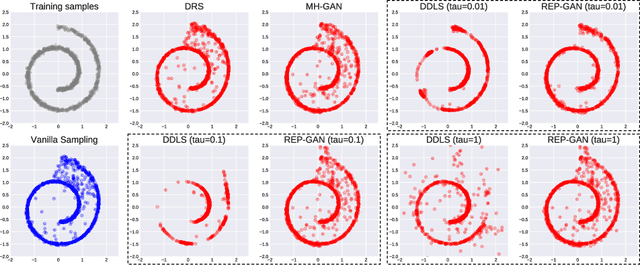
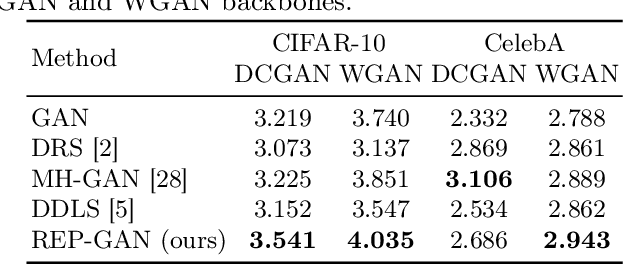
Recently, sampling methods have been successfully applied to enhance the sample quality of Generative Adversarial Networks (GANs). However, in practice, they typically have poor sample efficiency because of the independent proposal sampling from the generator. In this work, we propose REP-GAN, a novel sampling method that allows general dependent proposals by REParameterizing the Markov chains into the latent space of the generator. Theoretically, we show that our reparameterized proposal admits a closed-form Metropolis-Hastings acceptance ratio. Empirically, extensive experiments on synthetic and real datasets demonstrate that our REP-GAN largely improves the sample efficiency and obtains better sample quality simultaneously.
Dissecting the Diffusion Process in Linear Graph Convolutional Networks
Feb 22, 2021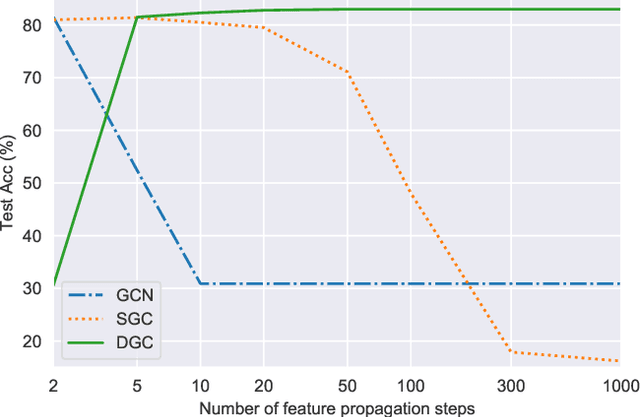
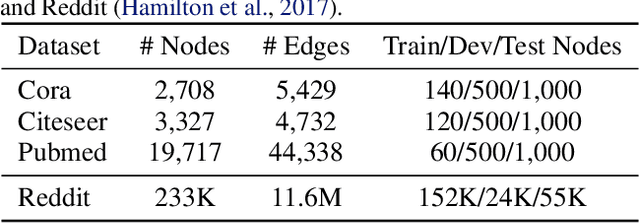
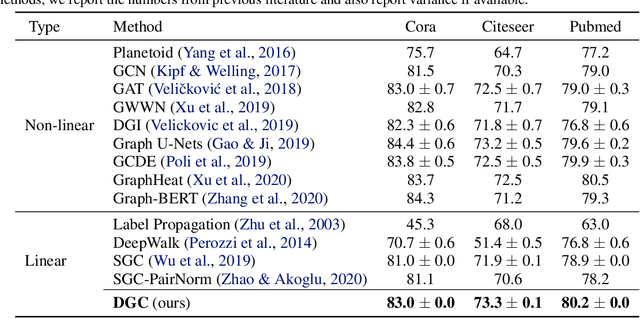
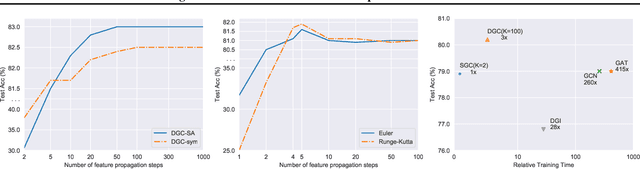
Graph Convolutional Networks (GCNs) have attracted more and more attentions in recent years. A typical GCN layer consists of a linear feature propagation step and a nonlinear transformation step. Recent works show that a linear GCN can achieve comparable performance to the original non-linear GCN while being much more computationally efficient. In this paper, we dissect the feature propagation steps of linear GCNs from a perspective of continuous graph diffusion, and analyze why linear GCNs fail to benefit from more propagation steps. Following that, we propose Decoupled Graph Convolution (DGC) that decouples the terminal time and the feature propagation steps, making it more flexible and capable of exploiting a very large number of feature propagation steps. Experiments demonstrate that our proposed DGC improves linear GCNs by a large margin and makes them competitive with many modern variants of non-linear GCNs.