Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder-free Robustness Disentanglement without (Additional) Supervision
Paper and Code
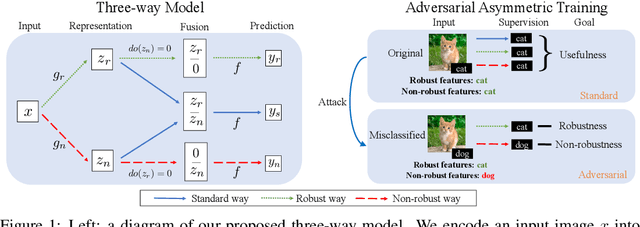
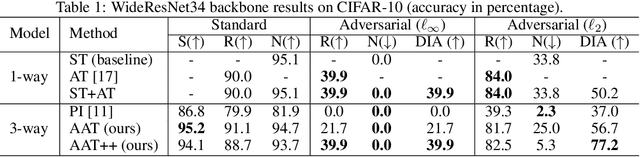
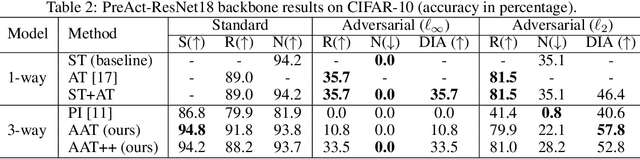
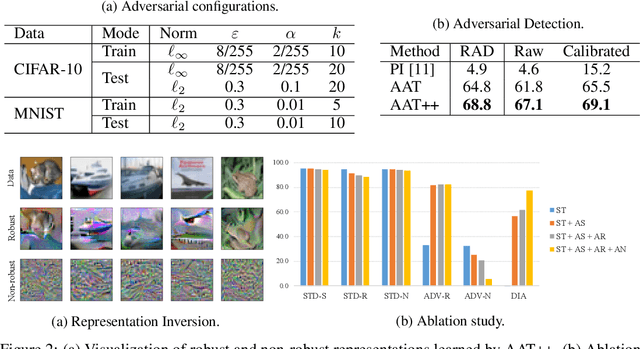
Adversarial Training (AT) is proposed to alleviate the adversarial vulnerability of machine learning models by extracting only robust features from the input, which, however, inevitably leads to severe accuracy reduction as it discards the non-robust yet useful features. This motivates us to preserve both robust and non-robust features and separate them with disentangled representation learning. Our proposed Adversarial Asymmetric Training (AAT) algorithm can reliably disentangle robust and non-robust representations without additional supervision on robustness. Empirical results show our method does not only successfully preserve accuracy by combining two representations, but also achieve much better disentanglement than previous work.
View paper on