 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Prefilling for Long-Context LLMs via Sparse Pattern Sharing
May 26, 2025Sparse attention methods exploit the inherent sparsity in attention to speed up the prefilling phase of long-context inference, mitigating the quadratic complexity of full attention computation. While existing sparse attention methods rely on predefined patterns or inaccurate estimations to approximate attention behavior, they often fail to fully capture the true dynamics of attention, resulting in reduced efficiency and compromised accuracy. Instead, we propose a highly accurate sparse attention mechanism that shares similar yet precise attention patterns across heads, enabling a more realistic capture of the dynamic behavior of attention. Our approach is grounded in two key observations: (1) attention patterns demonstrate strong inter-head similarity, and (2) this similarity remains remarkably consistent across diverse inputs. By strategically sharing computed accurate patterns across attention heads, our method effectively captures actual patterns while requiring full attention computation for only a small subset of heads. Comprehensive evaluations demonstrate that our approach achieves superior or comparable speedup relative to state-of-the-art methods while delivering the best overall accuracy.
PocketLLM: Enabling On-Device Fine-Tuning for Personalized LLMs
Jul 01, 2024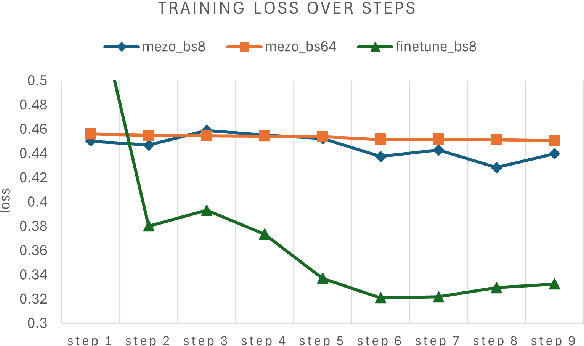
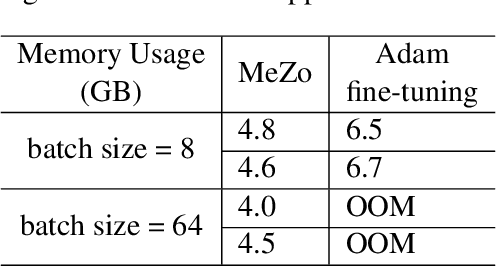
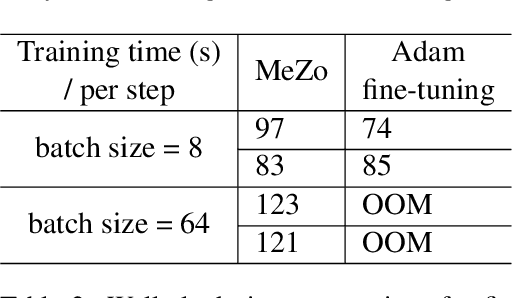
Recent advancements in large language models (LLMs) have indeed showcased their impressive capabilities. On mobile devices, the wealth of valuable, non-public data generated daily holds great promise for locally fine-tuning personalized LLMs, while maintaining privacy through on-device processing. However, the constraints of mobile device resources pose challenges to direct on-device LLM fine-tuning, mainly due to the memory-intensive nature of derivative-based optimization required for saving gradients and optimizer states. To tackle this, we propose employing derivative-free optimization techniques to enable on-device fine-tuning of LLM, even on memory-limited mobile devices. Empirical results demonstrate that the RoBERTa-large model and OPT-1.3B can be fine-tuned locally on the OPPO Reno 6 smartphone using around 4GB and 6.5GB of memory respectively, using derivative-free optimization techniques. This highlights the feasibility of on-device LLM fine-tuning on mobile devices, paving the way for personalized LLMs on resource-constrained devices while safeguarding data privacy.
Probing Negative Sampling Strategies to Learn GraphRepresentations via Unsupervised Contrastive Learning
Apr 13, 2021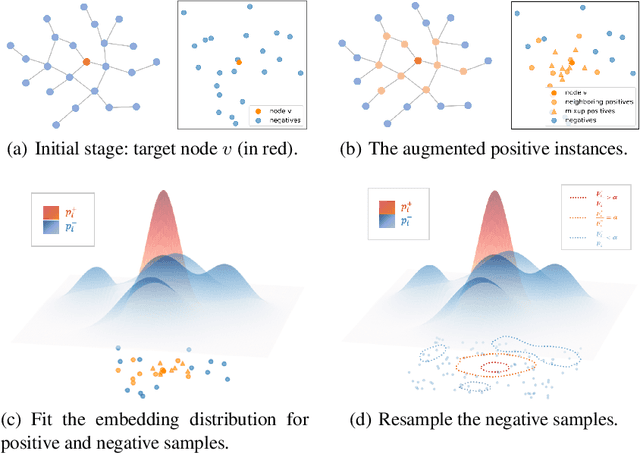

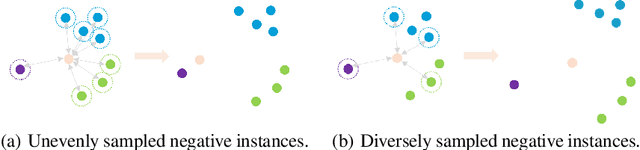
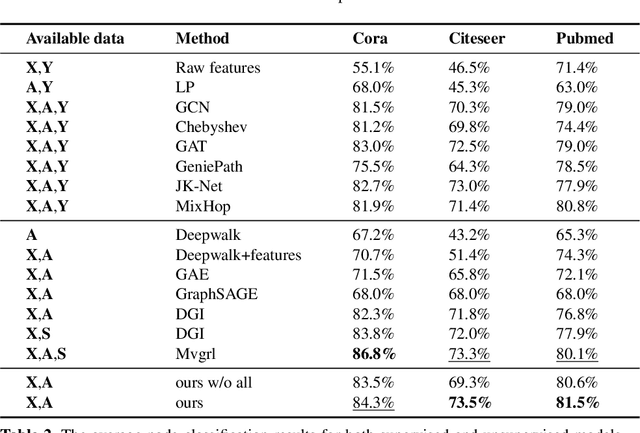
Graph representation learning has long been an important yet challenging task for various real-world applications. However, their downstream tasks are mainly performed in the settings of supervised or semi-supervised learning. Inspired by recent advances in unsupervised contrastive learning, this paper is thus motivated to investigate how the node-wise contrastive learning could be performed. Particularly, we respectively resolve the class collision issue and the imbalanced negative data distribution issue. Extensive experiments are performed on three real-world datasets and the proposed approach achieves the SOTA model performance.
Decoder-free Robustness Disentanglement without (Additional) Supervision
Jul 02, 2020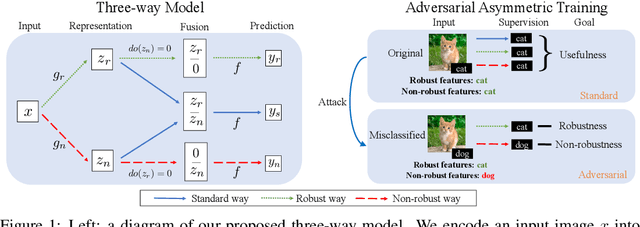
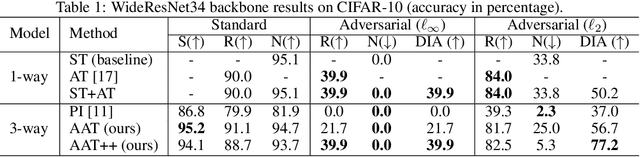
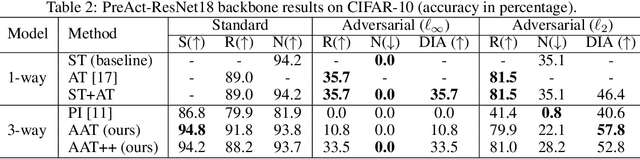
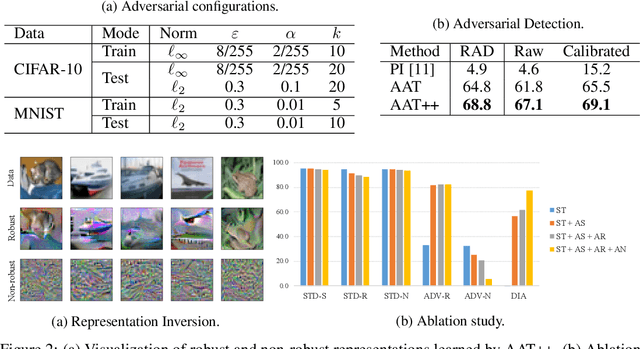
Adversarial Training (AT) is proposed to alleviate the adversarial vulnerability of machine learning models by extracting only robust features from the input, which, however, inevitably leads to severe accuracy reduction as it discards the non-robust yet useful features. This motivates us to preserve both robust and non-robust features and separate them with disentangled representation learning. Our proposed Adversarial Asymmetric Training (AAT) algorithm can reliably disentangle robust and non-robust representations without additional supervision on robustness. Empirical results show our method does not only successfully preserve accuracy by combining two representations, but also achieve much better disentanglement than previous work.
Structure Matters: Towards Generating Transferable Adversarial Images
Nov 20, 2019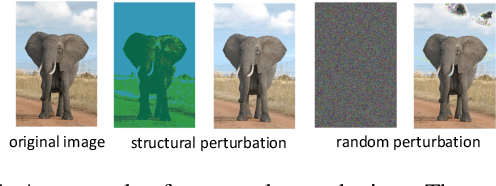
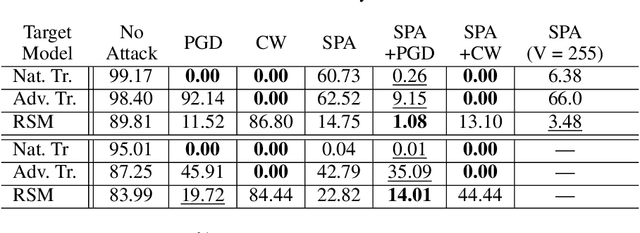
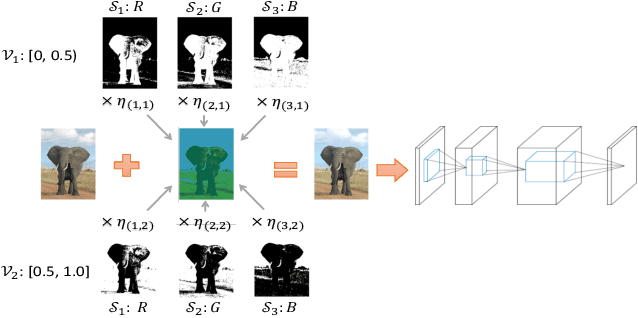
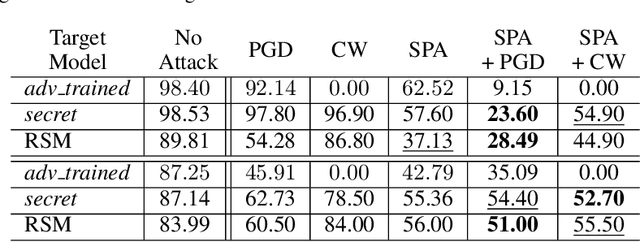
Recent works on adversarial examples for image classification focus on directly modifying pixels with minor perturbations. The small perturbation requirement is imposed to ensure the generated adversarial examples being natural and realistic to humans, which, however, puts a curb on the attack space thus limiting the attack ability and transferability especially for systems protected by a defense mechanism. In this paper, we propose the novel concepts of structure patterns and structure-aware perturbations that relax the small perturbation constraint while still keeping images natural. The key idea of our approach is to allow perceptible deviation in adversarial examples while keeping structure patterns that are central to a human classifier. Built upon these concepts, we propose a \emph{structure-preserving attack (SPA)} for generating natural adversarial examples with extremely high transferability. Empirical results on the MNIST and the CIFAR10 datasets show that SPA exhibits strong attack ability in both the white-box and black-box setting even defenses are applied. Moreover, with the integration of PGD or CW attack, its attack ability escalates sharply under the white-box setting, without losing the outstanding transferability inherited from SPA.
Structure-Preserving Transformation: Generating Diverse and Transferable Adversarial Examples
Sep 08, 2018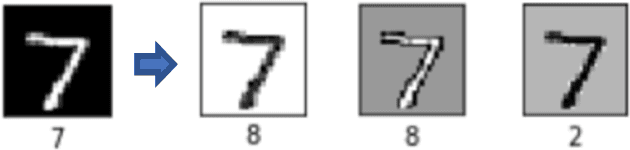
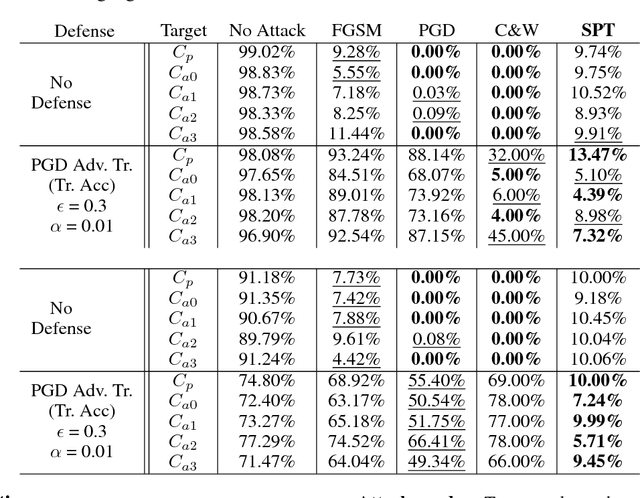

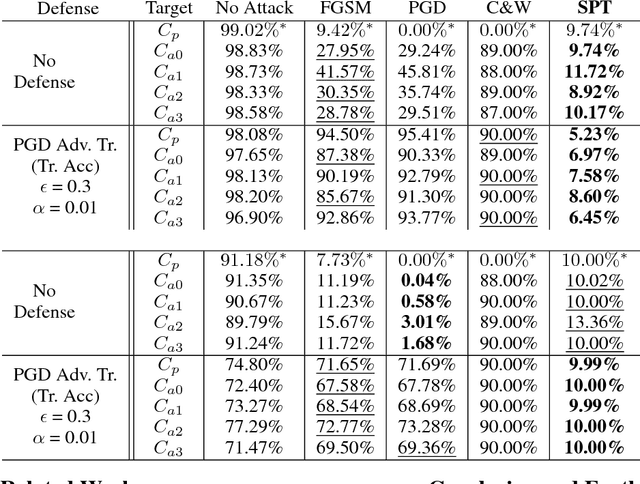
Adversarial examples are perturbed inputs designed to fool machine learning models. Most recent works on adversarial examples for image classification focus on directly modifying pixels with minor perturbations. A common requirement in all these works is that the malicious perturbations should be small enough (measured by an $L_p$ norm for some $p$) so that they are imperceptible to humans. However, small perturbations can be unnecessarily restrictive and limit the diversity of adversarial examples generated. Further, an $L_p$ norm based distance metric ignores important structure patterns hidden in images that are important to human perception. Consequently, even the minor perturbation introduced in recent works often makes the adversarial examples less natural to humans. More importantly, they often do not transfer well and are therefore less effective when attacking black-box models especially for those protected by a defense mechanism. In this paper, we propose a structure-preserving transformation (SPT) for generating natural and diverse adversarial examples with extremely high transferability. The key idea of our approach is to allow perceptible deviation in adversarial examples while keeping structure patterns that are central to a human classifier. Empirical results on the MNIST and the fashion-MNIST datasets show that adversarial examples generated by our approach can easily bypass strong adversarial training. Further, they transfer well to other target models with no loss or little loss of successful attack rate.