 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Preserving Transformation: Generating Diverse and Transferable Adversarial Examples
Paper and Code
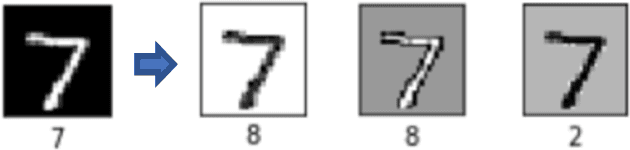
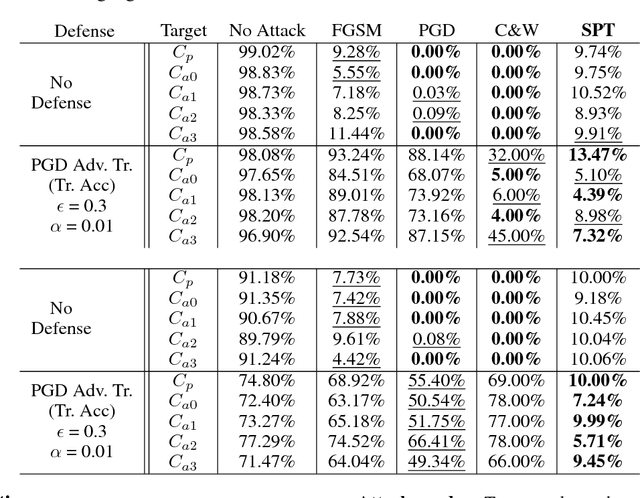

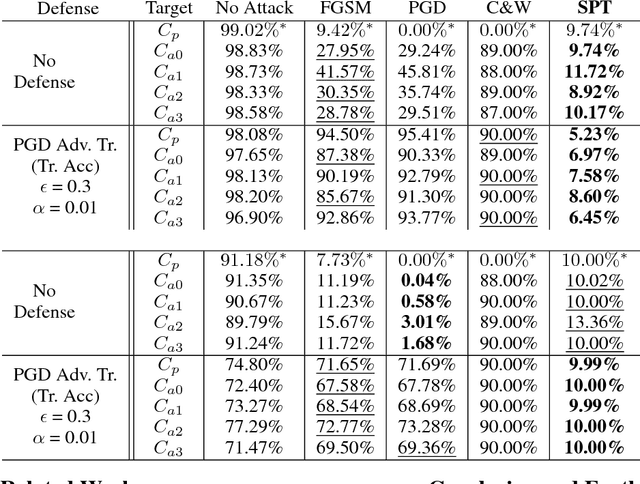
Adversarial examples are perturbed inputs designed to fool machine learning models. Most recent works on adversarial examples for image classification focus on directly modifying pixels with minor perturbations. A common requirement in all these works is that the malicious perturbations should be small enough (measured by an $L_p$ norm for some $p$) so that they are imperceptible to humans. However, small perturbations can be unnecessarily restrictive and limit the diversity of adversarial examples generated. Further, an $L_p$ norm based distance metric ignores important structure patterns hidden in images that are important to human perception. Consequently, even the minor perturbation introduced in recent works often makes the adversarial examples less natural to humans. More importantly, they often do not transfer well and are therefore less effective when attacking black-box models especially for those protected by a defense mechanism. In this paper, we propose a structure-preserving transformation (SPT) for generating natural and diverse adversarial examples with extremely high transferability. The key idea of our approach is to allow perceptible deviation in adversarial examples while keeping structure patterns that are central to a human classifier. Empirical results on the MNIST and the fashion-MNIST datasets show that adversarial examples generated by our approach can easily bypass strong adversarial training. Further, they transfer well to other target models with no loss or little loss of successful attack rate.