 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
Jun 10, 2026Few-step diffusion distillation has become increasingly mature for 4-8-step generation, yet pushing further to 2 steps remains challenging. In this work, we introduce Z-Image Turbo++, a high-quality 2-step image generation model distilled from the 8-step Z-Image Turbo teacher. Our method addresses the central bottlenecks of increased task difficulty and limited model capacity in 2-step generation through three simple but effective design choices tailored to this regime. First, we propose Distribution-Aligned Adversarial Learning, which uses teacher-generated images rather than external real images as real samples for GAN training, providing a more attainable and informative adversarial target. Second, we adopt Step-Decoupled Parameterization, assigning independent model parameters to the two denoising steps to better match their distinct capacity demands. Third, we perform End-to-End Training with Iterative Regularization, allowing the first step to receive gradients from final image quality while preserving a meaningful intermediate generation through an explicit step-1 loss. Together, these designs substantially narrow the quality gap between 2-step and 8-step generation in both qualitative and quantitative evaluations, highlighting the potential of carefully tailored distillation strategies for improving the quality-efficiency trade-off in few-step generation.
Joint Deblurring and 3D Reconstruction for Macrophotography
Oct 02, 2025
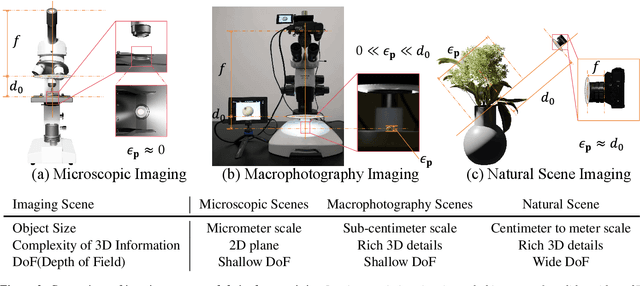
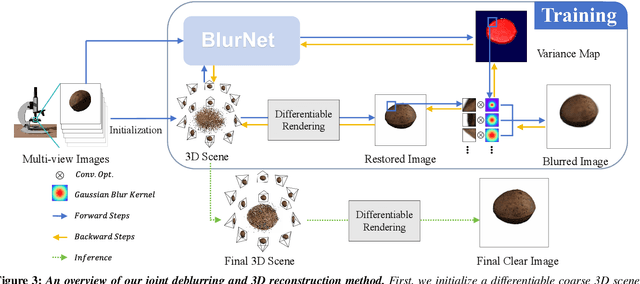

Macro lens has the advantages of high resolution and large magnification, and 3D modeling of small and detailed objects can provide richer information. However, defocus blur in macrophotography is a long-standing problem that heavily hinders the clear imaging of the captured objects and high-quality 3D reconstruction of them. Traditional image deblurring methods require a large number of images and annotations, and there is currently no multi-view 3D reconstruction method for macrophotography. In this work, we propose a joint deblurring and 3D reconstruction method for macrophotography. Starting from multi-view blurry images captured, we jointly optimize the clear 3D model of the object and the defocus blur kernel of each pixel. The entire framework adopts a differentiable rendering method to self-supervise the optimization of the 3D model and the defocus blur kernel. Extensive experiments show that from a small number of multi-view images, our proposed method can not only achieve high-quality image deblurring but also recover high-fidelity 3D appearance.
ReasoningV: Efficient Verilog Code Generation with Adaptive Hybrid Reasoning Model
Apr 20, 2025



Large Language Models (LLMs) have advanced Verilog code generation significantly, yet face challenges in data quality, reasoning capabilities, and computational efficiency. This paper presents ReasoningV, a novel model employing a hybrid reasoning strategy that integrates trained intrinsic capabilities with dynamic inference adaptation for Verilog code generation. Our framework introduces three complementary innovations: (1) ReasoningV-5K, a high-quality dataset of 5,000 functionally verified instances with reasoning paths created through multi-dimensional filtering of PyraNet samples; (2) a two-stage training approach combining parameter-efficient fine-tuning for foundational knowledge with full-parameter optimization for enhanced reasoning; and (3) an adaptive reasoning mechanism that dynamically adjusts reasoning depth based on problem complexity, reducing token consumption by up to 75\% while preserving performance. Experimental results demonstrate ReasoningV's effectiveness with a pass@1 accuracy of 57.8\% on VerilogEval-human, achieving performance competitive with leading commercial models like Gemini-2.0-flash (59.5\%) and exceeding the previous best open-source model by 10.4 percentage points. ReasoningV offers a more reliable and accessible pathway for advancing AI-driven hardware design automation, with our model, data, and code available at https://github.com/BUAA-CLab/ReasoningV.
MuLan: Adapting Multilingual Diffusion Models for Hundreds of Languages with Negligible Cost
Dec 02, 2024



In this work, we explore a cost-effective framework for multilingual image generation. We find that, unlike models tuned on high-quality images with multilingual annotations, leveraging text encoders pre-trained on widely available, noisy Internet image-text pairs significantly enhances data efficiency in text-to-image (T2I) generation across multiple languages. Based on this insight, we introduce MuLan, Multi-Language adapter, a lightweight language adapter with fewer than 20M parameters, trained alongside a frozen text encoder and image diffusion model. Compared to previous multilingual T2I models, this framework offers: (1) Cost efficiency. Using readily accessible English data and off-the-shelf multilingual text encoders minimizes the training cost; (2) High performance. Achieving comparable generation capabilities in over 110 languages with CLIP similarity scores nearly matching those in English (38.61 for English vs. 37.61 for other languages); and (3) Broad applicability. Seamlessly integrating with compatible community tools like LoRA, LCM, ControlNet, and IP-Adapter, expanding its potential use cases.
Bidirectional Consistency Models
Mar 30, 2024
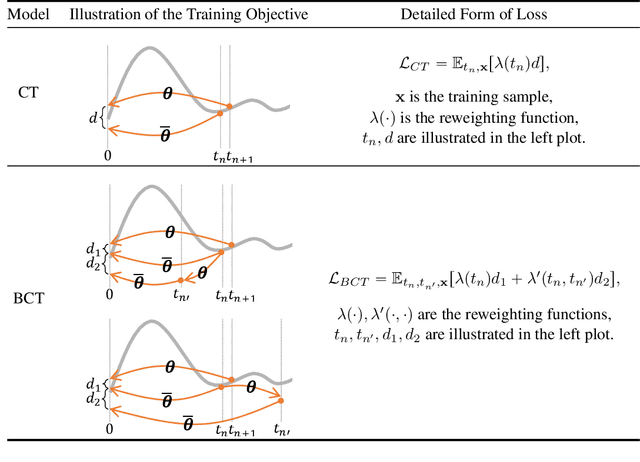

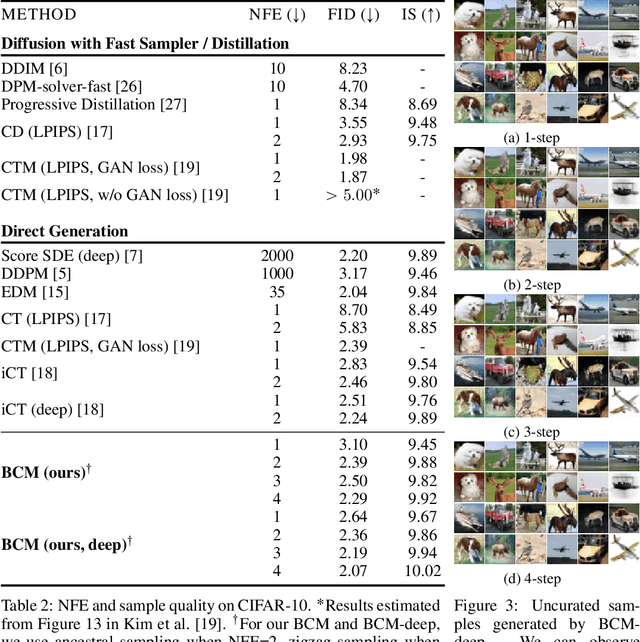
Diffusion models (DMs) are capable of generating remarkably high-quality samples by iteratively denoising a random vector, a process that corresponds to moving along the probability flow ordinary differential equation (PF ODE). Interestingly, DMs can also invert an input image to noise by moving backward along the PF ODE, a key operation for downstream tasks such as interpolation and image editing. However, the iterative nature of this process restricts its speed, hindering its broader application. Recently, Consistency Models (CMs) have emerged to address this challenge by approximating the integral of the PF ODE, largely reducing the number of iterations. Yet, the absence of an explicit ODE solver complicates the inversion process. To resolve this, we introduce the Bidirectional Consistency Model (BCM), which learns a single neural network that enables both forward and backward traversal along the PF ODE, efficiently unifying generation and inversion tasks within one framework. Notably, our proposed method enables one-step generation and inversion while also allowing the use of additional steps to enhance generation quality or reduce reconstruction error. Furthermore, by leveraging our model's bidirectional consistency, we introduce a sampling strategy that can enhance FID while preserving the generated image content. We further showcase our model's capabilities in several downstream tasks, such as interpolation and inpainting, and present demonstrations of potential applications, including blind restoration of compressed images and defending black-box adversarial attacks.
$L_0$-Sampler: An $L_{0}$ Model Guided Volume Sampling for NeRF
Nov 13, 2023Since being proposed, Neural Radiance Fields (NeRF) have achieved great success in related tasks, mainly adopting the hierarchical volume sampling (HVS) strategy for volume rendering. However, the HVS of NeRF approximates distributions using piecewise constant functions, which provides a relatively rough estimation. Based on the observation that a well-trained weight function $w(t)$ and the $L_0$ distance between points and the surface have very high similarity, we propose $L_0$-Sampler by incorporating the $L_0$ model into $w(t)$ to guide the sampling process. Specifically, we propose to use piecewise exponential functions rather than piecewise constant functions for interpolation, which can not only approximate quasi-$L_0$ weight distributions along rays quite well but also can be easily implemented with few lines of code without additional computational burden. Stable performance improvements can be achieved by applying $L_0$-Sampler to NeRF and its related tasks like 3D reconstruction. Code is available at https://ustc3dv.github.io/L0-Sampler/ .
Balance, Imbalance, and Rebalance: Understanding Robust Overfitting from a Minimax Game Perspective
Oct 30, 2023Adversarial Training (AT) has become arguably the state-of-the-art algorithm for extracting robust features. However, researchers recently notice that AT suffers from severe robust overfitting problems, particularly after learning rate (LR) decay. In this paper, we explain this phenomenon by viewing adversarial training as a dynamic minimax game between the model trainer and the attacker. Specifically, we analyze how LR decay breaks the balance between the minimax game by empowering the trainer with a stronger memorization ability, and show such imbalance induces robust overfitting as a result of memorizing non-robust features. We validate this understanding with extensive experiments, and provide a holistic view of robust overfitting from the dynamics of both the two game players. This understanding further inspires us to alleviate robust overfitting by rebalancing the two players by either regularizing the trainer's capacity or improving the attack strength. Experiments show that the proposed ReBalanced Adversarial Training (ReBAT) can attain good robustness and does not suffer from robust overfitting even after very long training. Code is available at https://github.com/PKU-ML/ReBAT.