 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
Dec 20, 2024The rapid advance of Large Language Models (LLMs) has catalyzed the development of Vision-Language Models (VLMs). Monolithic VLMs, which avoid modality-specific encoders, offer a promising alternative to the compositional ones but face the challenge of inferior performance. Most existing monolithic VLMs require tuning pre-trained LLMs to acquire vision abilities, which may degrade their language capabilities. To address this dilemma, this paper presents a novel high-performance monolithic VLM named HoVLE. We note that LLMs have been shown capable of interpreting images, when image embeddings are aligned with text embeddings. The challenge for current monolithic VLMs actually lies in the lack of a holistic embedding module for both vision and language inputs. Therefore, HoVLE introduces a holistic embedding module that converts visual and textual inputs into a shared space, allowing LLMs to process images in the same way as texts. Furthermore, a multi-stage training strategy is carefully designed to empower the holistic embedding module. It is first trained to distill visual features from a pre-trained vision encoder and text embeddings from the LLM, enabling large-scale training with unpaired random images and text tokens. The whole model further undergoes next-token prediction on multi-modal data to align the embeddings. Finally, an instruction-tuning stage is incorporated. Our experiments show that HoVLE achieves performance close to leading compositional models on various benchmarks, outperforming previous monolithic models by a large margin. Model available at https://huggingface.co/OpenGVLab/HoVLE.
MuLan: Adapting Multilingual Diffusion Models for Hundreds of Languages with Negligible Cost
Dec 02, 2024



In this work, we explore a cost-effective framework for multilingual image generation. We find that, unlike models tuned on high-quality images with multilingual annotations, leveraging text encoders pre-trained on widely available, noisy Internet image-text pairs significantly enhances data efficiency in text-to-image (T2I) generation across multiple languages. Based on this insight, we introduce MuLan, Multi-Language adapter, a lightweight language adapter with fewer than 20M parameters, trained alongside a frozen text encoder and image diffusion model. Compared to previous multilingual T2I models, this framework offers: (1) Cost efficiency. Using readily accessible English data and off-the-shelf multilingual text encoders minimizes the training cost; (2) High performance. Achieving comparable generation capabilities in over 110 languages with CLIP similarity scores nearly matching those in English (38.61 for English vs. 37.61 for other languages); and (3) Broad applicability. Seamlessly integrating with compatible community tools like LoRA, LCM, ControlNet, and IP-Adapter, expanding its potential use cases.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
PeerGPT: Probing the Roles of LLM-based Peer Agents as Team Moderators and Participants in Children's Collaborative Learning
Mar 21, 2024In children's collaborative learning, effective peer conversations can significantly enhance the quality of children's collaborative interactions. The integration of Large Language Model (LLM) agents into this setting explores their novel role as peers, assessing impacts as team moderators and participants. We invited two groups of participants to engage in a collaborative learning workshop, where they discussed and proposed conceptual solutions to a design problem. The peer conversation transcripts were analyzed using thematic analysis. We discovered that peer agents, while managing discussions effectively as team moderators, sometimes have their instructions disregarded. As participants, they foster children's creative thinking but may not consistently provide timely feedback. These findings highlight potential design improvements and considerations for peer agents in both roles.
Bilevel Scheduled Sampling for Dialogue Generation
Sep 05, 2023Exposure bias poses a common challenge in numerous natural language processing tasks, particularly in the dialog generation. In response to this issue, researchers have devised various techniques, among which scheduled sampling has proven to be an effective method for mitigating exposure bias. However, the existing state-of-the-art scheduled sampling methods solely consider the current sampling words' quality for threshold truncation sampling, which overlooks the importance of sentence-level information and the method of threshold truncation warrants further discussion. In this paper, we propose a bilevel scheduled sampling model that takes the sentence-level information into account and incorporates it with word-level quality. To enhance sampling diversity and improve the model's adaptability, we propose a smooth function that maps the combined result of sentence-level and word-level information to an appropriate range, and employ probabilistic sampling based on the mapped values instead of threshold truncation. Experiments conducted on the DailyDialog and PersonaChat datasets demonstrate the effectiveness of our proposed methods, which significantly alleviate the exposure bias problem and outperform state-of-the-art scheduled sampling methods.
FLAME: A Self-Adaptive Auto-labeling System for Heterogeneous Mobile Processors
Mar 03, 2020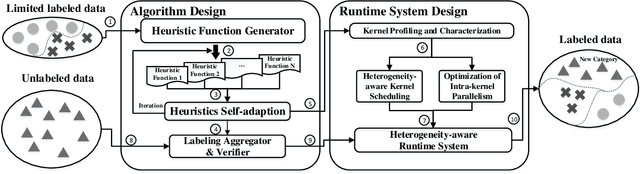
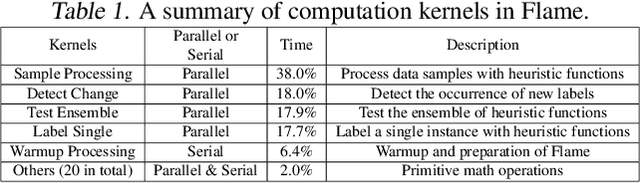
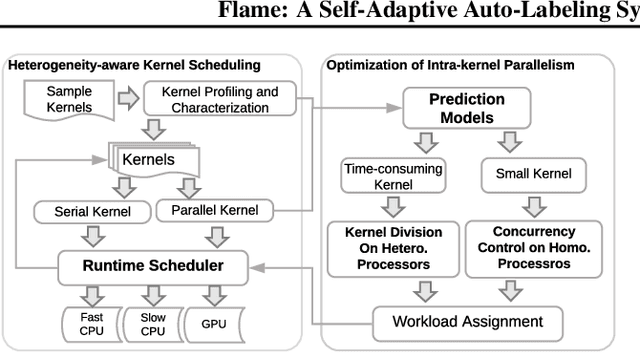
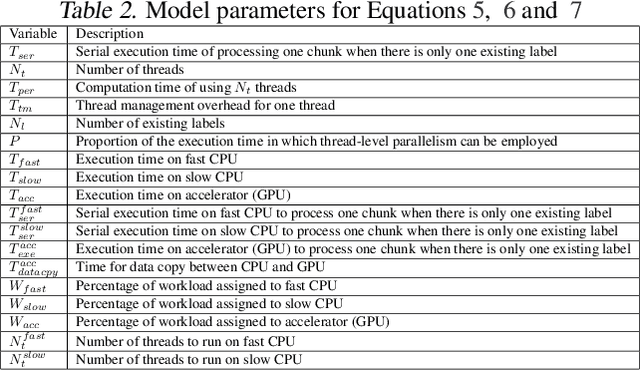
How to accurately and efficiently label data on a mobile device is critical for the success of training machine learning models on mobile devices. Auto-labeling data on mobile devices is challenging, because data is usually incrementally generated and there is possibility of having unknown labels. Furthermore, the rich hardware heterogeneity on mobile devices creates challenges on efficiently executing auto-labeling workloads. In this paper, we introduce Flame, an auto-labeling system that can label non-stationary data with unknown labels. Flame includes a runtime system that efficiently schedules and executes auto-labeling workloads on heterogeneous mobile processors. Evaluating Flame with eight datasets on a smartphone, we demonstrate that Flame enables auto-labeling with high labeling accuracy and high performance.
Performance Analysis and Characterization of Training Deep Learning Models on NVIDIA TX2
Jun 10, 2019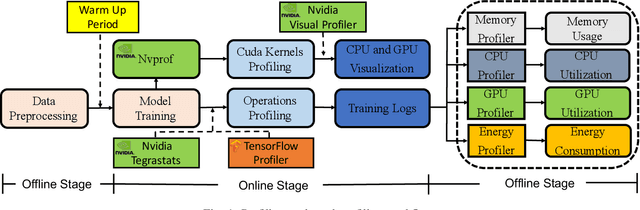
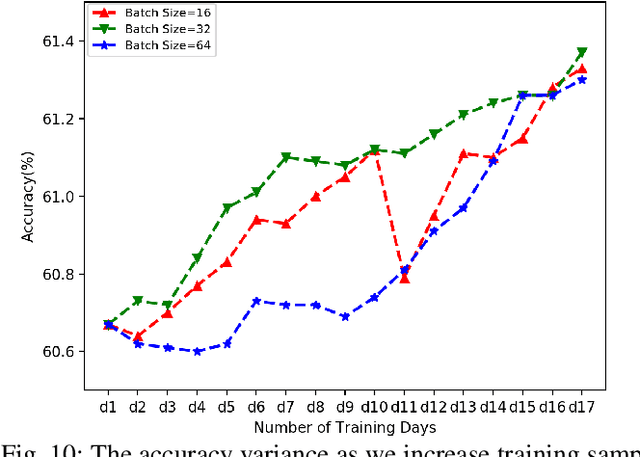
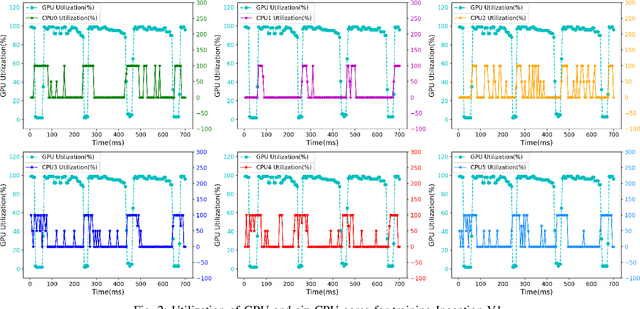
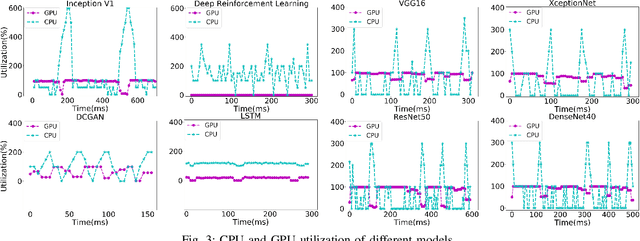
Training deep learning models on mobile devices recently becomes possible, because of increasing computation power on mobile hardware and the advantages of enabling high user experiences. Most of the existing work on machine learning at mobile devices is focused on the inference of deep learning models (particularly convolutional neural network and recurrent neural network), but not training. The performance characterization of training deep learning models on mobile devices is largely unexplored, although understanding the performance characterization is critical for designing and implementing deep learning models on mobile devices. In this paper, we perform a variety of experiments on a representative mobile device (the NVIDIA TX2) to study the performance of training deep learning models. We introduce a benchmark suite and tools to study performance of training deep learning models on mobile devices, from the perspectives of memory consumption, hardware utilization, and power consumption. The tools can correlate performance results with fine-grained operations in deep learning models, providing capabilities to capture performance variance and problems at a fine granularity. We reveal interesting performance problems and opportunities, including under-utilization of heterogeneous hardware, large energy consumption of the memory, and high predictability of workload characterization. Based on the performance analysis, we suggest interesting research directions.
Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Training
Oct 21, 2018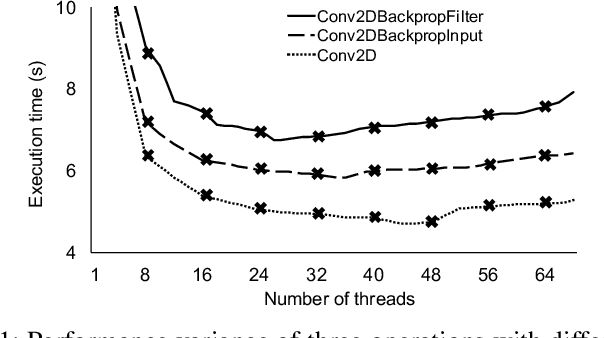
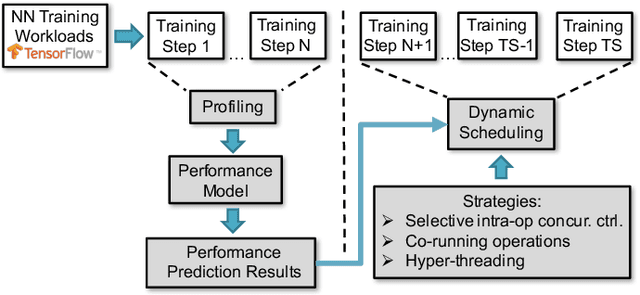

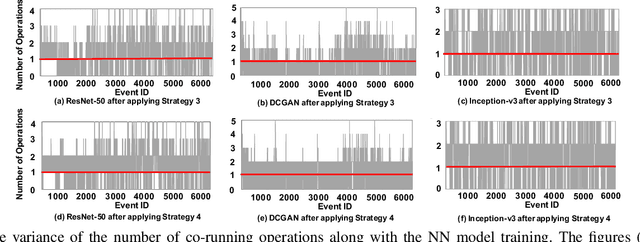
Training neural network often uses a machine learning framework such as TensorFlow and Caffe2. These frameworks employ a dataflow model where the NN training is modeled as a directed graph composed of a set of nodes. Operations in neural network training are typically implemented by the frameworks as primitives and represented as nodes in the dataflow graph. Training NN models in a dataflow-based machine learning framework involves a large number of fine-grained operations. Those operations have diverse memory access patterns and computation intensity. How to manage and schedule those operations is challenging, because we have to decide the number of threads to run each operation (concurrency control) and schedule those operations for good hardware utilization and system throughput. In this paper, we extend an existing runtime system (the TensorFlow runtime) to enable automatic concurrency control and scheduling of operations. We explore performance modeling to predict the performance of operations with various thread-level parallelism. Our performance model is highly accurate and lightweight. Leveraging the performance model, our runtime system employs a set of scheduling strategies that co-run operations to improve hardware utilization and system throughput. Our runtime system demonstrates a big performance benefit. Comparing with using the recommended configurations for concurrency control and operation scheduling in TensorFlow, our approach achieves 33% performance (execution time) improvement on average (up to 49%) for three neural network models, and achieves high performance closing to the optimal one manually obtained by the user.