 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotSoTiny: A Large, Living Benchmark for RTL Code Generation
Dec 23, 2025LLMs have shown early promise in generating RTL code, yet evaluating their capabilities in realistic setups remains a challenge. So far, RTL benchmarks have been limited in scale, skewed toward trivial designs, offering minimal verification rigor, and remaining vulnerable to data contamination. To overcome these limitations and to push the field forward, this paper introduces NotSoTiny, a benchmark that assesses LLM on the generation of structurally rich and context-aware RTL. Built from hundreds of actual hardware designs produced by the Tiny Tapeout community, our automated pipeline removes duplicates, verifies correctness and periodically incorporates new designs to mitigate contamination, matching Tiny Tapeout release schedule. Evaluation results show that NotSoTiny tasks are more challenging than prior benchmarks, emphasizing its effectiveness in overcoming current limitations of LLMs applied to hardware design, and in guiding the improvement of such promising technology.
TuRTLe: A Unified Evaluation of LLMs for RTL Generation
Mar 31, 2025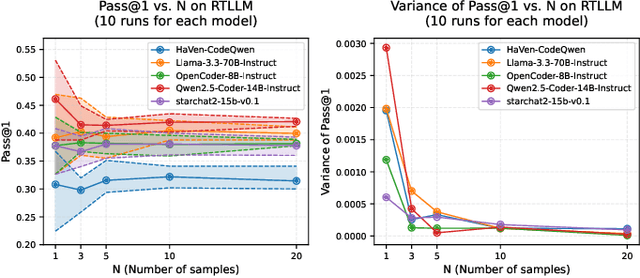
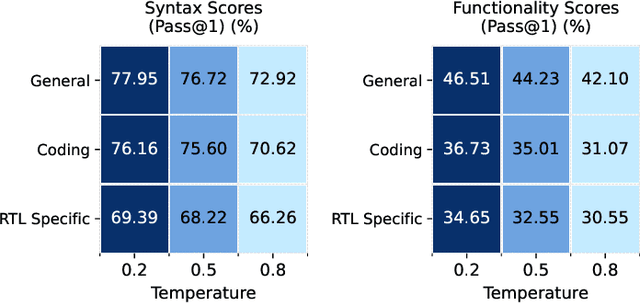
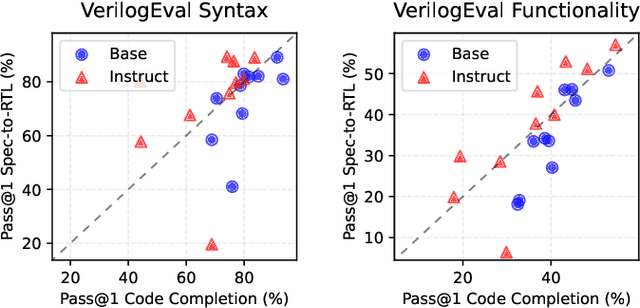
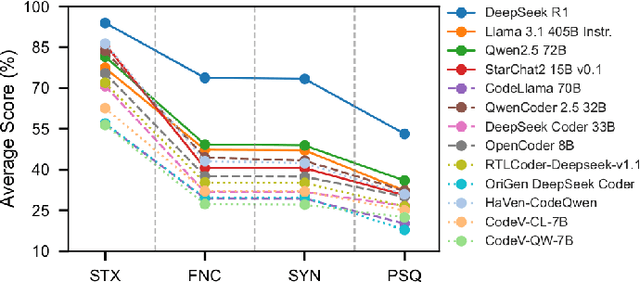
The rapid advancements in LLMs have driven the adoption of generative AI in various domains, including Electronic Design Automation (EDA). Unlike traditional software development, EDA presents unique challenges, as generated RTL code must not only be syntactically correct and functionally accurate but also synthesizable by hardware generators while meeting performance, power, and area constraints. These additional requirements introduce complexities that existing code-generation benchmarks often fail to capture, limiting their effectiveness in evaluating LLMs for RTL generation. To address this gap, we propose TuRTLe, a unified evaluation framework designed to systematically assess LLMs across key RTL generation tasks. TuRTLe integrates multiple existing benchmarks and automates the evaluation process, enabling a comprehensive assessment of LLM performance in syntax correctness, functional correctness, synthesis, PPA optimization, and exact line completion. Using this framework, we benchmark a diverse set of open LLMs and analyze their strengths and weaknesses in EDA-specific tasks. Our results show that reasoning-based models, such as DeepSeek R1, consistently outperform others across multiple evaluation criteria, but at the cost of increased computational overhead and inference latency. Additionally, base models are better suited in module completion tasks, while instruct-tuned models perform better in specification-to-RTL tasks.
Union: A Unified HW-SW Co-Design Ecosystem in MLIR for Evaluating Tensor Operations on Spatial Accelerators
Sep 17, 2021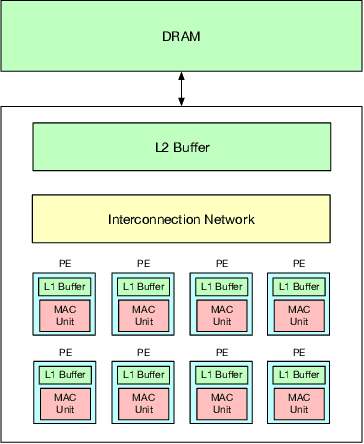
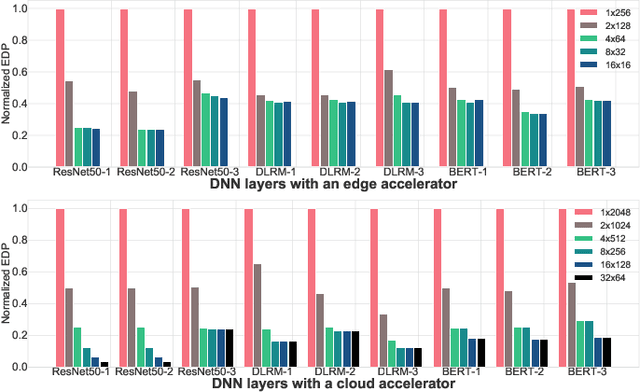
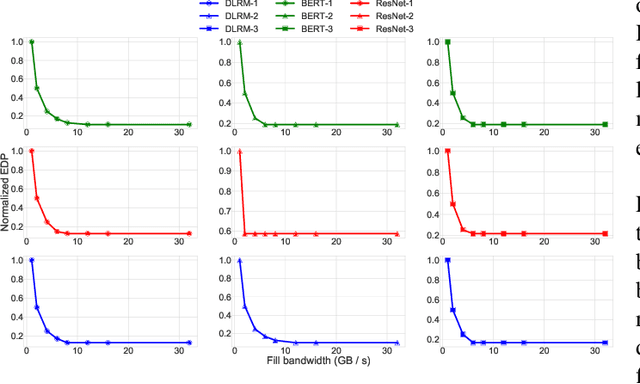
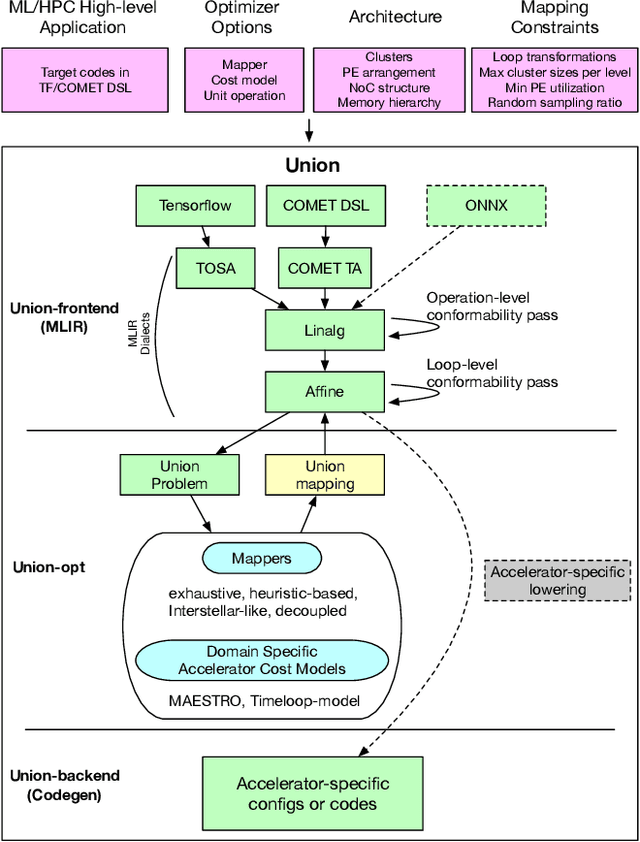
To meet the extreme compute demands for deep learning across commercial and scientific applications, dataflow accelerators are becoming increasingly popular. While these "domain-specific" accelerators are not fully programmable like CPUs and GPUs, they retain varying levels of flexibility with respect to data orchestration, i.e., dataflow and tiling optimizations to enhance efficiency. There are several challenges when designing new algorithms and mapping approaches to execute the algorithms for a target problem on new hardware. Previous works have addressed these challenges individually. To address this challenge as a whole, in this work, we present a HW-SW co-design ecosystem for spatial accelerators called Union within the popular MLIR compiler infrastructure. Our framework allows exploring different algorithms and their mappings on several accelerator cost models. Union also includes a plug-and-play library of accelerator cost models and mappers which can easily be extended. The algorithms and accelerator cost models are connected via a novel mapping abstraction that captures the map space of spatial accelerators which can be systematically pruned based on constraints from the hardware, workload, and mapper. We demonstrate the value of Union for the community with several case studies which examine offloading different tensor operations(CONV/GEMM/Tensor Contraction) on diverse accelerator architectures using different mapping schemes.
Smart-PGSim: Using Neural Network to Accelerate AC-OPF Power Grid Simulation
Aug 26, 2020

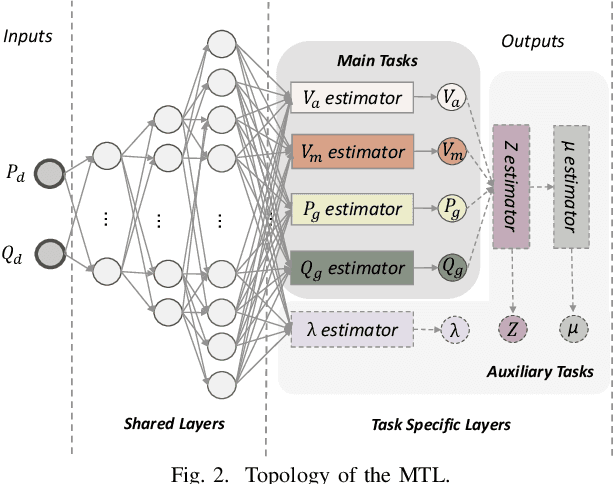
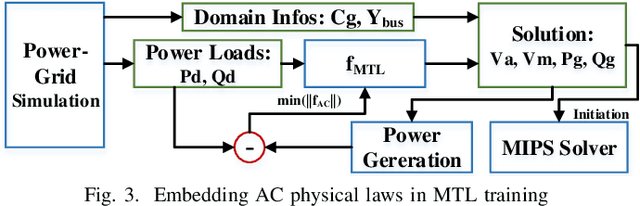
The optimal power flow (OPF) problem is one of the most important optimization problems for the operation of the power grid. It calculates the optimum scheduling of the committed generation units. In this paper, we develop a neural network approach to the problem of accelerating the current optimal power flow (AC-OPF) by generating an intelligent initial solution. The high quality of the initial solution and guidance of other outputs generated by the neural network enables faster convergence to the solution without losing optimality of final solution as computed by traditional methods. Smart-PGSim generates a novel multitask-learning neural network model to accelerate the AC-OPF simulation. Smart-PGSim also imposes the physical constraints of the simulation on the neural network automatically. Smart-PGSim brings an average of 49.2% performance improvement (up to 91%), computed over 10,000 problem simulations, with respect to the original AC-OPF implementation, without losing the optimality of the final solution.
Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Training
Oct 21, 2018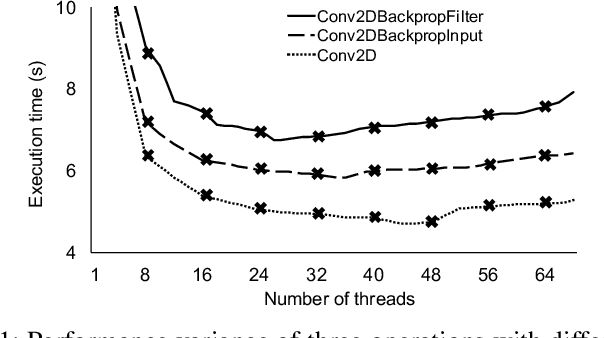
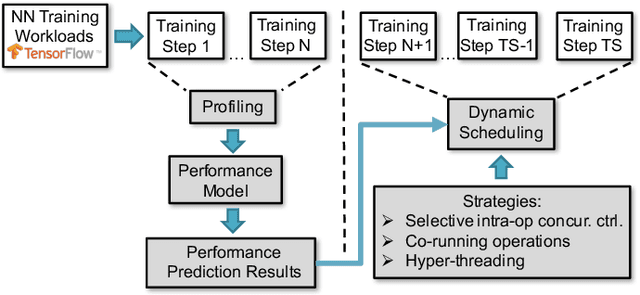

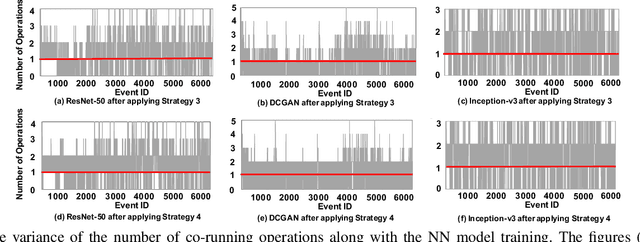
Training neural network often uses a machine learning framework such as TensorFlow and Caffe2. These frameworks employ a dataflow model where the NN training is modeled as a directed graph composed of a set of nodes. Operations in neural network training are typically implemented by the frameworks as primitives and represented as nodes in the dataflow graph. Training NN models in a dataflow-based machine learning framework involves a large number of fine-grained operations. Those operations have diverse memory access patterns and computation intensity. How to manage and schedule those operations is challenging, because we have to decide the number of threads to run each operation (concurrency control) and schedule those operations for good hardware utilization and system throughput. In this paper, we extend an existing runtime system (the TensorFlow runtime) to enable automatic concurrency control and scheduling of operations. We explore performance modeling to predict the performance of operations with various thread-level parallelism. Our performance model is highly accurate and lightweight. Leveraging the performance model, our runtime system employs a set of scheduling strategies that co-run operations to improve hardware utilization and system throughput. Our runtime system demonstrates a big performance benefit. Comparing with using the recommended configurations for concurrency control and operation scheduling in TensorFlow, our approach achieves 33% performance (execution time) improvement on average (up to 49%) for three neural network models, and achieves high performance closing to the optimal one manually obtained by the user.