 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Integers and Rationals on Neuromorphic Computers using Virtual Neuron
Aug 15, 2022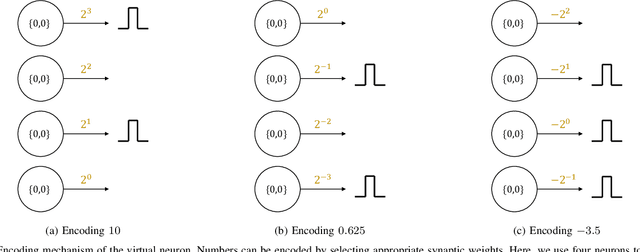
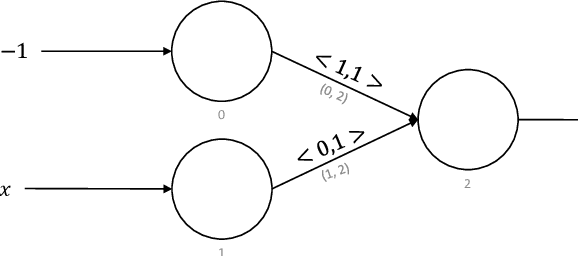
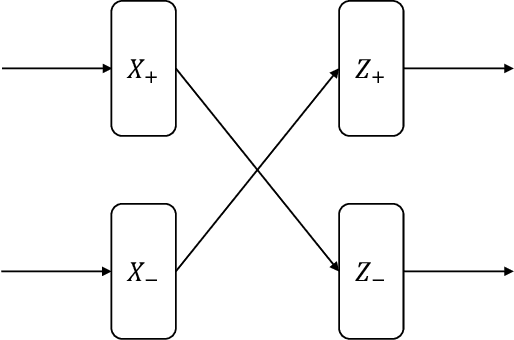
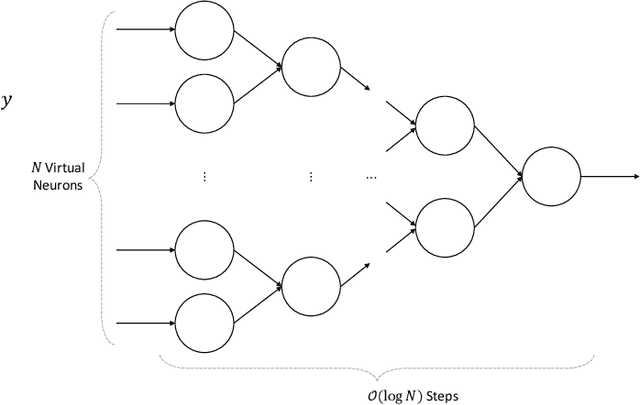
Neuromorphic computers perform computations by emulating the human brain, and use extremely low power. They are expected to be indispensable for energy-efficient computing in the future. While they are primarily used in spiking neural network-based machine learning applications, neuromorphic computers are known to be Turing-complete, and thus, capable of general-purpose computation. However, to fully realize their potential for general-purpose, energy-efficient computing, it is important to devise efficient mechanisms for encoding numbers. Current encoding approaches have limited applicability and may not be suitable for general-purpose computation. In this paper, we present the virtual neuron as an encoding mechanism for integers and rational numbers. We evaluate the performance of the virtual neuron on physical and simulated neuromorphic hardware and show that it can perform an addition operation using 23 nJ of energy on average using a mixed-signal memristor-based neuromorphic processor. We also demonstrate its utility by using it in some of the mu-recursive functions, which are the building blocks of general-purpose computation.
Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Training
Oct 21, 2018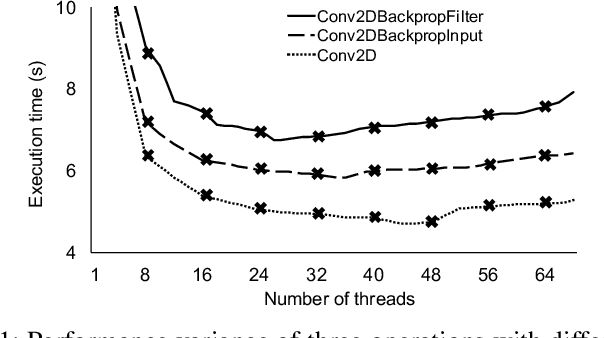
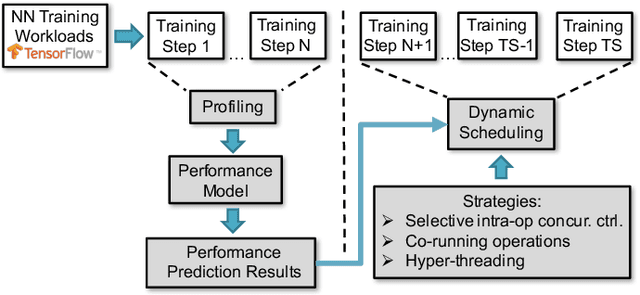

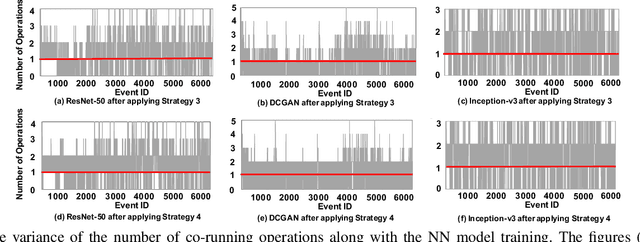
Training neural network often uses a machine learning framework such as TensorFlow and Caffe2. These frameworks employ a dataflow model where the NN training is modeled as a directed graph composed of a set of nodes. Operations in neural network training are typically implemented by the frameworks as primitives and represented as nodes in the dataflow graph. Training NN models in a dataflow-based machine learning framework involves a large number of fine-grained operations. Those operations have diverse memory access patterns and computation intensity. How to manage and schedule those operations is challenging, because we have to decide the number of threads to run each operation (concurrency control) and schedule those operations for good hardware utilization and system throughput. In this paper, we extend an existing runtime system (the TensorFlow runtime) to enable automatic concurrency control and scheduling of operations. We explore performance modeling to predict the performance of operations with various thread-level parallelism. Our performance model is highly accurate and lightweight. Leveraging the performance model, our runtime system employs a set of scheduling strategies that co-run operations to improve hardware utilization and system throughput. Our runtime system demonstrates a big performance benefit. Comparing with using the recommended configurations for concurrency control and operation scheduling in TensorFlow, our approach achieves 33% performance (execution time) improvement on average (up to 49%) for three neural network models, and achieves high performance closing to the optimal one manually obtained by the user.