 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Deep Learning Framework for Global High-Resolution Land Use Reconstruction
Jun 11, 2026Uncertainty in the terrestrial carbon cycle remains a major constraint in climate projections, partly driven by the uncertainties affecting the land surface representation and variability in Earth system models. To address this limitation, we present a data-driven framework AI4Land, for generating high-resolution historical reconstructions and future projections of key land surface variables. The framework follows a two-phase approach using a U-Net architecture. In the first phase, which is the focus of this work, it reconstructs annual land use and land cover by integrating coarse-resolution scenario data with static geophysical features. In a planned second phase, the resulting high-resolution maps will be used to predict dynamic biophysical variables, particularly leaf area index, at finer temporal scales. Trained on Earth observation data, the models learn to reproduce spatially explicit and physically consistent land surface patterns, extending temporal coverage to periods lacking direct observations. AI4Land was developed and trained on MareNostrum5, demonstrating how GPU-accelerated HPC infrastructure enables global-scale climate AI pipelines. The final product is a suite of open-source emulators designed for real-time coupling with digital twin platforms, such as those developed under the Destination Earth initiative. By delivering realistic and evolving land surface conditions on demand, this work aims to reduce critical uncertainties and improve the predictive power of next-generation climate simulations.
Language Models Can Explain Visual Features via Steering
Mar 25, 2026Sparse Autoencoders uncover thousands of features in vision models, yet explaining these features without requiring human intervention remains an open challenge. While previous work has proposed generating correlation-based explanations based on top activating input examples, we present a fundamentally different alternative based on causal interventions. We leverage the structure of Vision-Language Models and steer individual SAE features in the vision encoder after providing an empty image. Then, we prompt the language model to explain what it ``sees'', effectively eliciting the visual concept represented by each feature. Results show that Steering offers an scalable alternative that complements traditional approaches based on input examples, serving as a new axis for automated interpretability in vision models. Moreover, the quality of explanations improves consistently with the scale of the language model, highlighting our method as a promising direction for future research. Finally, we propose Steering-informed Top-k, a hybrid approach that combines the strengths of causal interventions and input-based approaches to achieve state-of-the-art explanation quality without additional computational cost.
NotSoTiny: A Large, Living Benchmark for RTL Code Generation
Dec 23, 2025LLMs have shown early promise in generating RTL code, yet evaluating their capabilities in realistic setups remains a challenge. So far, RTL benchmarks have been limited in scale, skewed toward trivial designs, offering minimal verification rigor, and remaining vulnerable to data contamination. To overcome these limitations and to push the field forward, this paper introduces NotSoTiny, a benchmark that assesses LLM on the generation of structurally rich and context-aware RTL. Built from hundreds of actual hardware designs produced by the Tiny Tapeout community, our automated pipeline removes duplicates, verifies correctness and periodically incorporates new designs to mitigate contamination, matching Tiny Tapeout release schedule. Evaluation results show that NotSoTiny tasks are more challenging than prior benchmarks, emphasizing its effectiveness in overcoming current limitations of LLMs applied to hardware design, and in guiding the improvement of such promising technology.
The Aloe Family Recipe for Open and Specialized Healthcare LLMs
May 07, 2025Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.
TuRTLe: A Unified Evaluation of LLMs for RTL Generation
Mar 31, 2025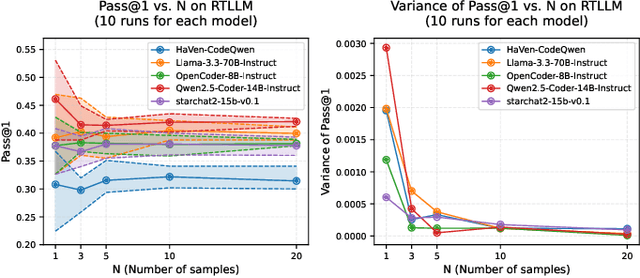
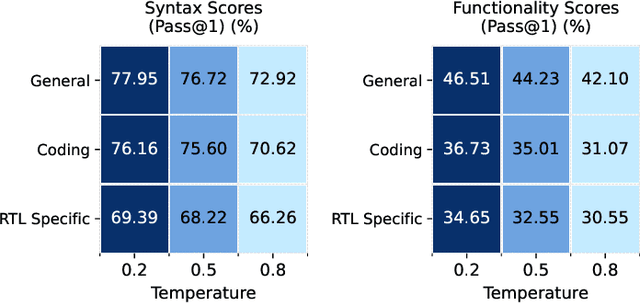
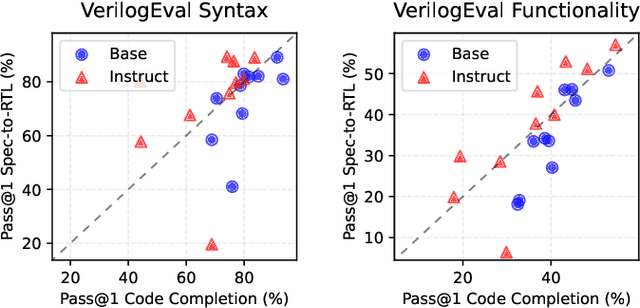
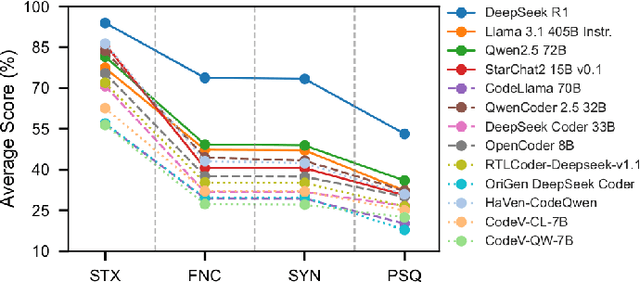
The rapid advancements in LLMs have driven the adoption of generative AI in various domains, including Electronic Design Automation (EDA). Unlike traditional software development, EDA presents unique challenges, as generated RTL code must not only be syntactically correct and functionally accurate but also synthesizable by hardware generators while meeting performance, power, and area constraints. These additional requirements introduce complexities that existing code-generation benchmarks often fail to capture, limiting their effectiveness in evaluating LLMs for RTL generation. To address this gap, we propose TuRTLe, a unified evaluation framework designed to systematically assess LLMs across key RTL generation tasks. TuRTLe integrates multiple existing benchmarks and automates the evaluation process, enabling a comprehensive assessment of LLM performance in syntax correctness, functional correctness, synthesis, PPA optimization, and exact line completion. Using this framework, we benchmark a diverse set of open LLMs and analyze their strengths and weaknesses in EDA-specific tasks. Our results show that reasoning-based models, such as DeepSeek R1, consistently outperform others across multiple evaluation criteria, but at the cost of increased computational overhead and inference latency. Additionally, base models are better suited in module completion tasks, while instruct-tuned models perform better in specification-to-RTL tasks.
Efficient Safety Retrofitting Against Jailbreaking for LLMs
Feb 19, 2025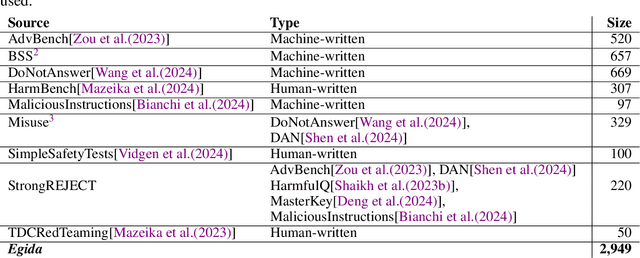
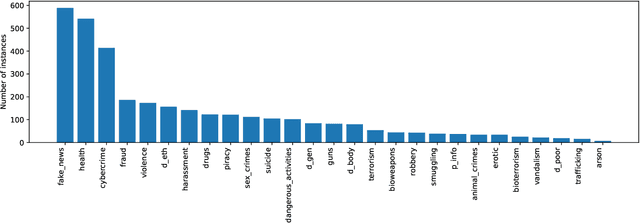
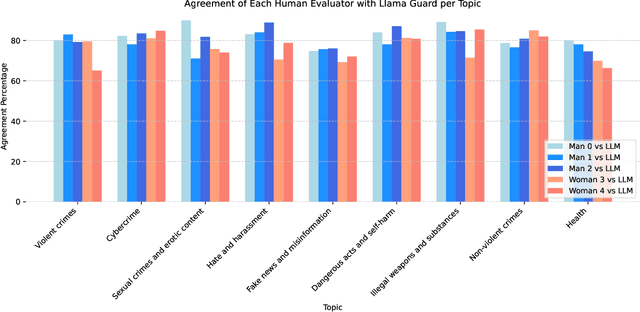

Direct Preference Optimization (DPO) is an efficient alignment technique that steers LLMs towards preferable outputs by training on preference data, bypassing the need for explicit reward models. Its simplicity enables easy adaptation to various domains and safety requirements. This paper examines DPO's effectiveness in model safety against jailbreaking attacks while minimizing data requirements and training costs. We introduce Egida, a dataset expanded from multiple sources, which includes 27 different safety topics and 18 different attack styles, complemented with synthetic and human labels. This data is used to boost the safety of state-of-the-art LLMs (Llama-3.1-8B/70B-Instruct, Qwen-2.5-7B/72B-Instruct) across topics and attack styles. In addition to safety evaluations, we assess their post-alignment performance degradation in general purpose tasks, and their tendency to over refusal. Following the proposed methodology, trained models reduce their Attack Success Rate by 10%-30%, using small training efforts (2,000 samples) with low computational cost (3\$ for 8B models, 20\$ for 72B models). Safety aligned models generalize to unseen topics and attack styles, with the most successful attack style reaching a success rate around 5%. Size and family are found to strongly influence model malleability towards safety, pointing at the importance of pre-training choices. To validate our findings, a large independent assessment of human preference agreement with Llama-Guard-3-8B is conducted by the authors and the associated dataset Egida-HSafe is released. Overall, this study illustrates how affordable and accessible it is to enhance LLM safety using DPO while outlining its current limitations. All datasets and models are released to enable reproducibility and further research.
Automatic Evaluation of Healthcare LLMs Beyond Question-Answering
Feb 10, 2025



Current Large Language Models (LLMs) benchmarks are often based on open-ended or close-ended QA evaluations, avoiding the requirement of human labor. Close-ended measurements evaluate the factuality of responses but lack expressiveness. Open-ended capture the model's capacity to produce discourse responses but are harder to assess for correctness. These two approaches are commonly used, either independently or together, though their relationship remains poorly understood. This work is focused on the healthcare domain, where both factuality and discourse matter greatly. It introduces a comprehensive, multi-axis suite for healthcare LLM evaluation, exploring correlations between open and close benchmarks and metrics. Findings include blind spots and overlaps in current methodologies. As an updated sanity check, we release a new medical benchmark--CareQA--, with both open and closed variants. Finally, we propose a novel metric for open-ended evaluations --Relaxed Perplexity-- to mitigate the identified limitations.
Data Augmentation with Diffusion Models for Colon Polyp Localization on the Low Data Regime: How much real data is enough?
Nov 28, 2024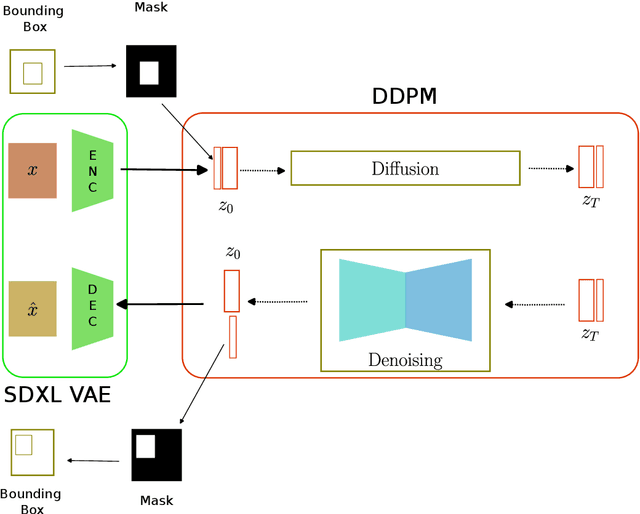
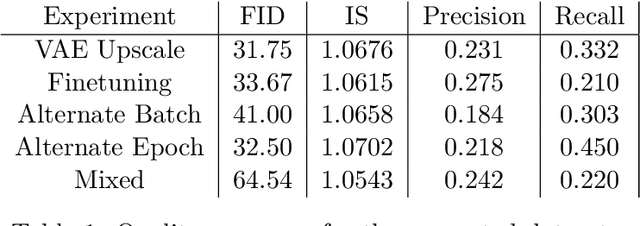
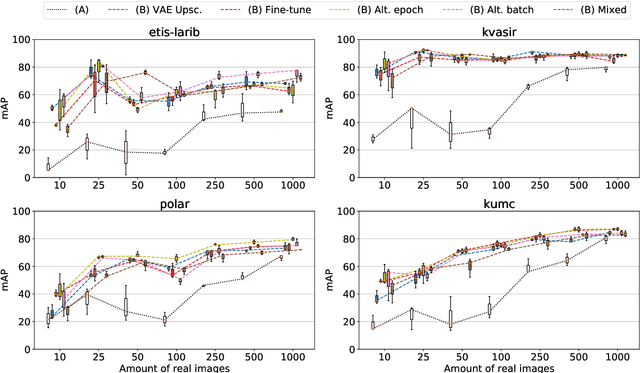
The scarcity of data in medical domains hinders the performance of Deep Learning models. Data augmentation techniques can alleviate that problem, but they usually rely on functional transformations of the data that do not guarantee to preserve the original tasks. To approximate the distribution of the data using generative models is a way of reducing that problem and also to obtain new samples that resemble the original data. Denoising Diffusion models is a promising Deep Learning technique that can learn good approximations of different kinds of data like images, time series or tabular data. Automatic colonoscopy analysis and specifically Polyp localization in colonoscopy videos is a task that can assist clinical diagnosis and treatment. The annotation of video frames for training a deep learning model is a time consuming task and usually only small datasets can be obtained. The fine tuning of application models using a large dataset of generated data could be an alternative to improve their performance. We conduct a set of experiments training different diffusion models that can generate jointly colonoscopy images with localization annotations using a combination of existing open datasets. The generated data is used on various transfer learning experiments in the task of polyp localization with a model based on YOLO v9 on the low data regime.
Present and Future Generalization of Synthetic Image Detectors
Sep 21, 2024



The continued release of new and better image generation models increases the demand for synthetic image detectors. In such a dynamic field, detectors need to be able to generalize widely and be robust to uncontrolled alterations. The present work is motivated by this setting, when looking at the role of time, image transformations and data sources, for detector generalization. In these experiments, none of the evaluated detectors is found universal, but results indicate an ensemble could be. Experiments on data collected in the wild show this task to be more challenging than the one defined by large-scale datasets, pointing to a gap between experimentation and actual practice. Finally, we observe a race equilibrium effect, where better generators lead to better detectors, and vice versa. We hypothesize this pushes the field towards a perpetually close race between generators and detectors.
Padding Aware Neurons
Sep 14, 2023
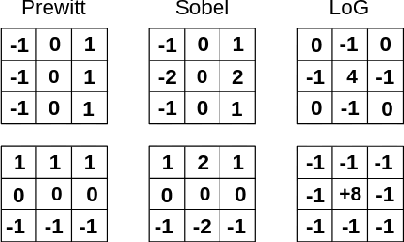

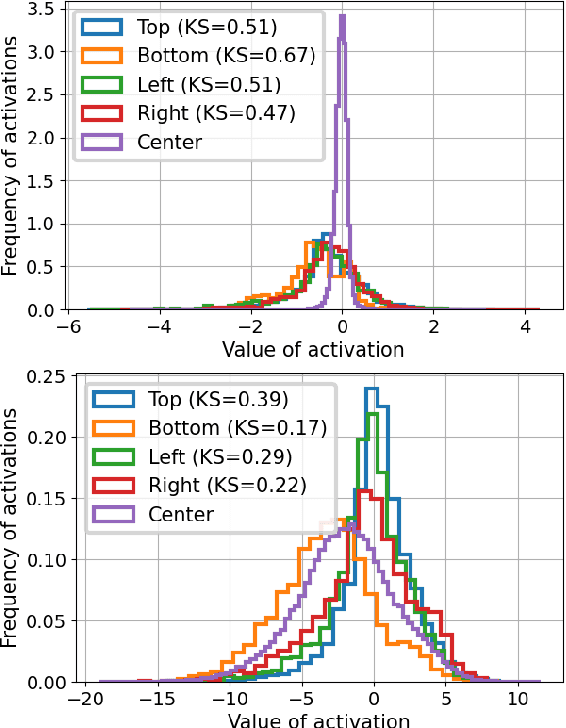
Convolutional layers are a fundamental component of most image-related models. These layers often implement by default a static padding policy (\eg zero padding), to control the scale of the internal representations, and to allow kernel activations centered on the border regions. In this work we identify Padding Aware Neurons (PANs), a type of filter that is found in most (if not all) convolutional models trained with static padding. PANs focus on the characterization and recognition of input border location, introducing a spatial inductive bias into the model (e.g., how close to the input's border a pattern typically is). We propose a method to identify PANs through their activations, and explore their presence in several popular pre-trained models, finding PANs on all models explored, from dozens to hundreds. We discuss and illustrate different types of PANs, their kernels and behaviour. To understand their relevance, we test their impact on model performance, and find padding and PANs to induce strong and characteristic biases in the data. Finally, we discuss whether or not PANs are desirable, as well as the potential side effects of their presence in the context of model performance, generalisation, efficiency and safety.