 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Aloe Family Recipe for Open and Specialized Healthcare LLMs
May 07, 2025Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.
Efficient Safety Retrofitting Against Jailbreaking for LLMs
Feb 19, 2025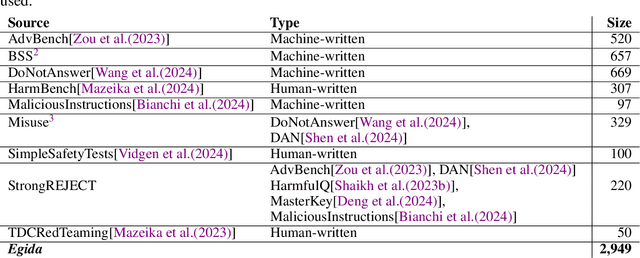
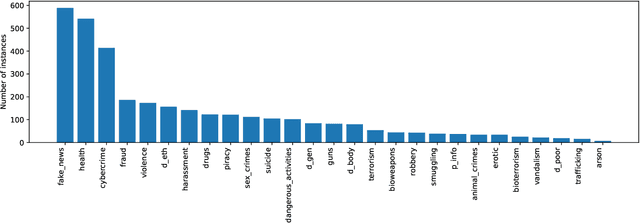
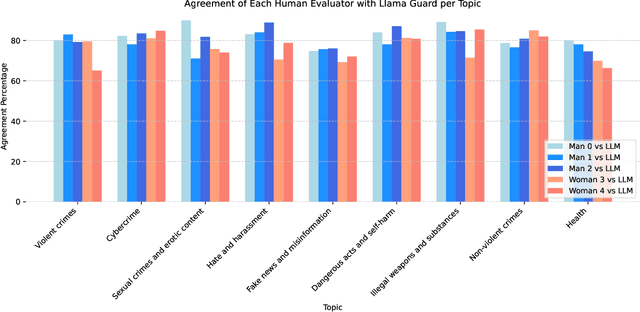

Direct Preference Optimization (DPO) is an efficient alignment technique that steers LLMs towards preferable outputs by training on preference data, bypassing the need for explicit reward models. Its simplicity enables easy adaptation to various domains and safety requirements. This paper examines DPO's effectiveness in model safety against jailbreaking attacks while minimizing data requirements and training costs. We introduce Egida, a dataset expanded from multiple sources, which includes 27 different safety topics and 18 different attack styles, complemented with synthetic and human labels. This data is used to boost the safety of state-of-the-art LLMs (Llama-3.1-8B/70B-Instruct, Qwen-2.5-7B/72B-Instruct) across topics and attack styles. In addition to safety evaluations, we assess their post-alignment performance degradation in general purpose tasks, and their tendency to over refusal. Following the proposed methodology, trained models reduce their Attack Success Rate by 10%-30%, using small training efforts (2,000 samples) with low computational cost (3\$ for 8B models, 20\$ for 72B models). Safety aligned models generalize to unseen topics and attack styles, with the most successful attack style reaching a success rate around 5%. Size and family are found to strongly influence model malleability towards safety, pointing at the importance of pre-training choices. To validate our findings, a large independent assessment of human preference agreement with Llama-Guard-3-8B is conducted by the authors and the associated dataset Egida-HSafe is released. Overall, this study illustrates how affordable and accessible it is to enhance LLM safety using DPO while outlining its current limitations. All datasets and models are released to enable reproducibility and further research.
Automatic Evaluation of Healthcare LLMs Beyond Question-Answering
Feb 10, 2025



Current Large Language Models (LLMs) benchmarks are often based on open-ended or close-ended QA evaluations, avoiding the requirement of human labor. Close-ended measurements evaluate the factuality of responses but lack expressiveness. Open-ended capture the model's capacity to produce discourse responses but are harder to assess for correctness. These two approaches are commonly used, either independently or together, though their relationship remains poorly understood. This work is focused on the healthcare domain, where both factuality and discourse matter greatly. It introduces a comprehensive, multi-axis suite for healthcare LLM evaluation, exploring correlations between open and close benchmarks and metrics. Findings include blind spots and overlaps in current methodologies. As an updated sanity check, we release a new medical benchmark--CareQA--, with both open and closed variants. Finally, we propose a novel metric for open-ended evaluations --Relaxed Perplexity-- to mitigate the identified limitations.
Aloe: A Family of Fine-tuned Open Healthcare LLMs
May 03, 2024



As the capabilities of Large Language Models (LLMs) in healthcare and medicine continue to advance, there is a growing need for competitive open-source models that can safeguard public interest. With the increasing availability of highly competitive open base models, the impact of continued pre-training is increasingly uncertain. In this work, we explore the role of instruct tuning, model merging, alignment, red teaming and advanced inference schemes, as means to improve current open models. To that end, we introduce the Aloe family, a set of open medical LLMs highly competitive within its scale range. Aloe models are trained on the current best base models (Mistral, LLaMA 3), using a new custom dataset which combines public data sources improved with synthetic Chain of Thought (CoT). Aloe models undergo an alignment phase, becoming one of the first few policy-aligned open healthcare LLM using Direct Preference Optimization, setting a new standard for ethical performance in healthcare LLMs. Model evaluation expands to include various bias and toxicity datasets, a dedicated red teaming effort, and a much-needed risk assessment for healthcare LLMs. Finally, to explore the limits of current LLMs in inference, we study several advanced prompt engineering strategies to boost performance across benchmarks, yielding state-of-the-art results for open healthcare 7B LLMs, unprecedented at this scale.
Who Explains the Explanation? Quantitatively Assessing Feature Attribution Methods
Sep 28, 2021
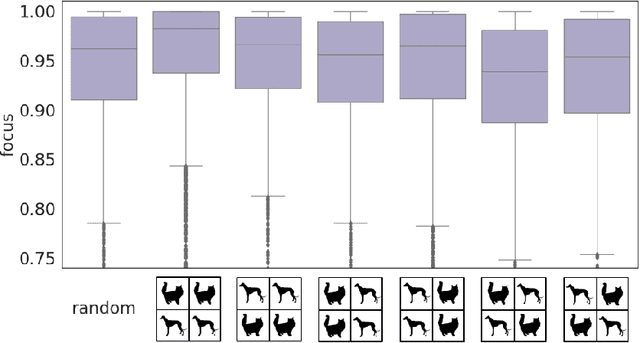
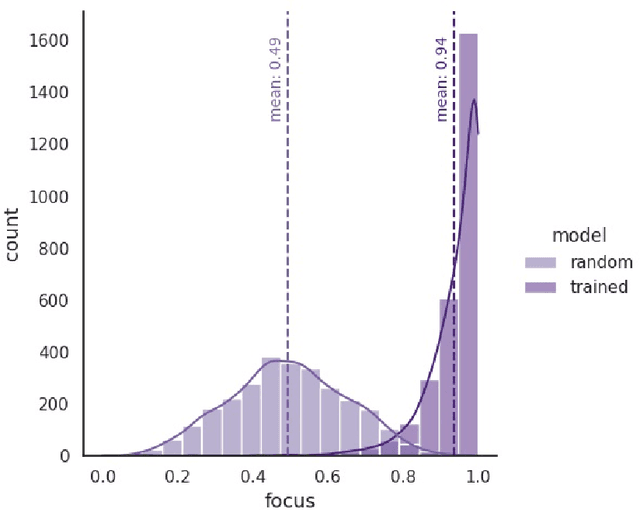
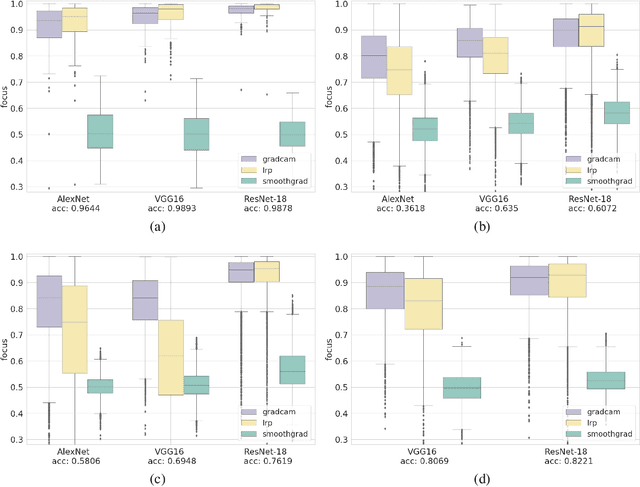
AI explainability seeks to increase the transparency of models, making them more trustworthy in the process. The need for transparency has been recently motivated by the emergence of deep learning models, which are particularly obscure by nature. Even in the domain of images, where deep learning has succeeded the most, explainability is still poorly assessed. Multiple feature attribution methods have been proposed in the literature with the purpose of explaining a DL model's behavior using visual queues, but no standardized metrics to assess or select these methods exist. In this paper we propose a novel evaluation metric -- the Focus -- designed to quantify the faithfulness of explanations provided by feature attribution methods, such as LRP or GradCAM. First, we show the robustness of the metric through randomization experiments, and then use Focus to evaluate and compare three popular explainability techniques using multiple architectures and datasets. Our results find LRP and GradCAM to be consistent and reliable, the former being more accurate for high performing models, while the latter remains most competitive even when applied to poorly performing models. Finally, we identify a strong relation between Focus and factors like model architecture and task, unveiling a new unsupervised approach for the assessment of models.
A Closer Look at Art Mediums: The MAMe Image Classification Dataset
Jul 27, 2020
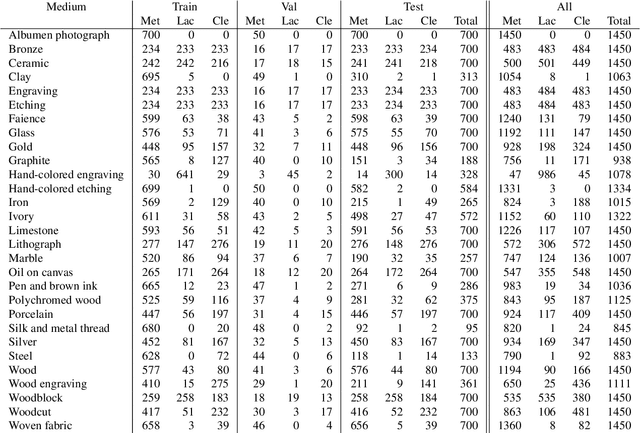
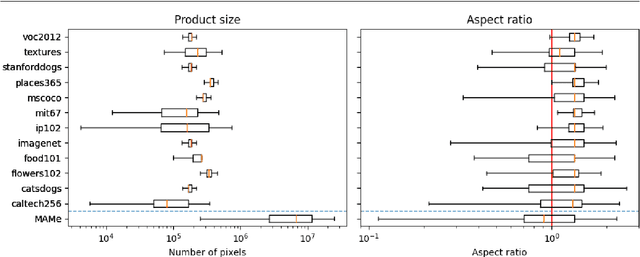
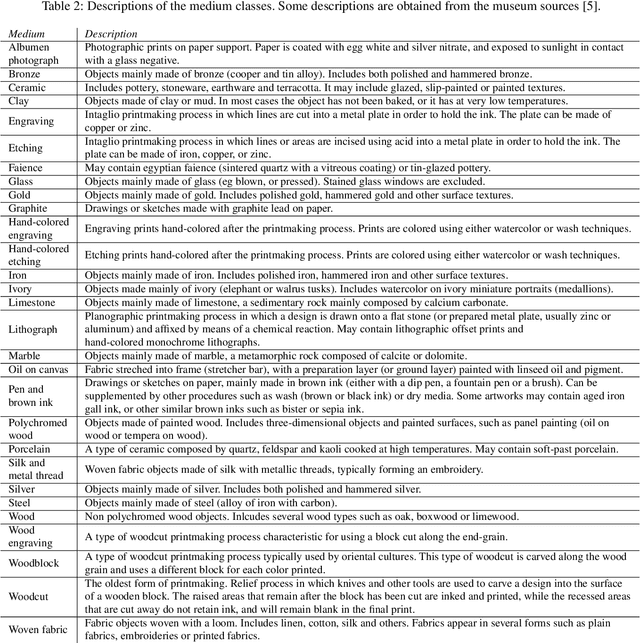
Art is an expression of human creativity, skill and technology. An exceptionally rich source of visual content. In the context of AI image processing systems, artworks represent one of the most challenging domains conceivable: Properly perceiving art requires attention to detail, a huge generalization capacity, and recognizing both simple and complex visual patterns. To challenge the AI community, this work introduces a novel image classification task focused on museum art mediums, the MAMe dataset. Data is gathered from three different museums, and aggregated by art experts into 29 classes of medium (i.e. materials and techniques). For each class, MAMe provides a minimum of 850 images (700 for training) of high-resolution and variable shape. The combination of volume, resolution and shape allows MAMe to fill a void in current image classification challenges, empowering research in aspects so far overseen by the research community. After reviewing the singularity of MAMe in the context of current image classification tasks, a thorough description of the task is provided, together with dataset statistics. Baseline experiments are conducted using well-known architectures, to highlight both the feasibility and complexity of the task proposed. Finally, these baselines are inspected using explainability methods and expert knowledge, to gain insight on the challenges that remain ahead.