 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Aloe Family Recipe for Open and Specialized Healthcare LLMs
May 07, 2025Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.
Efficient Safety Retrofitting Against Jailbreaking for LLMs
Feb 19, 2025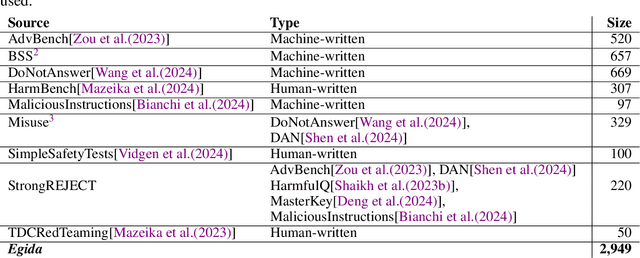
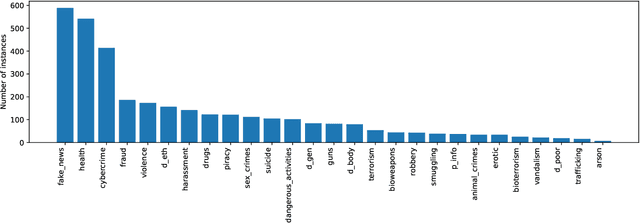
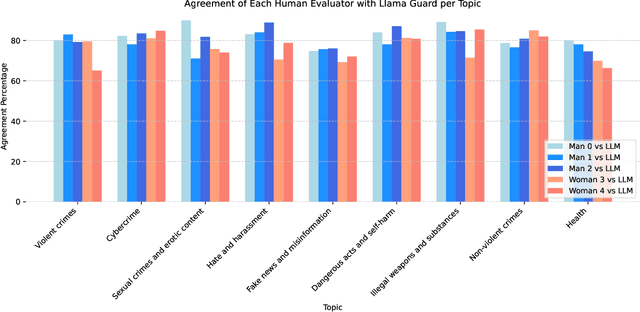

Direct Preference Optimization (DPO) is an efficient alignment technique that steers LLMs towards preferable outputs by training on preference data, bypassing the need for explicit reward models. Its simplicity enables easy adaptation to various domains and safety requirements. This paper examines DPO's effectiveness in model safety against jailbreaking attacks while minimizing data requirements and training costs. We introduce Egida, a dataset expanded from multiple sources, which includes 27 different safety topics and 18 different attack styles, complemented with synthetic and human labels. This data is used to boost the safety of state-of-the-art LLMs (Llama-3.1-8B/70B-Instruct, Qwen-2.5-7B/72B-Instruct) across topics and attack styles. In addition to safety evaluations, we assess their post-alignment performance degradation in general purpose tasks, and their tendency to over refusal. Following the proposed methodology, trained models reduce their Attack Success Rate by 10%-30%, using small training efforts (2,000 samples) with low computational cost (3\$ for 8B models, 20\$ for 72B models). Safety aligned models generalize to unseen topics and attack styles, with the most successful attack style reaching a success rate around 5%. Size and family are found to strongly influence model malleability towards safety, pointing at the importance of pre-training choices. To validate our findings, a large independent assessment of human preference agreement with Llama-Guard-3-8B is conducted by the authors and the associated dataset Egida-HSafe is released. Overall, this study illustrates how affordable and accessible it is to enhance LLM safety using DPO while outlining its current limitations. All datasets and models are released to enable reproducibility and further research.
Data Augmentation with Diffusion Models for Colon Polyp Localization on the Low Data Regime: How much real data is enough?
Nov 28, 2024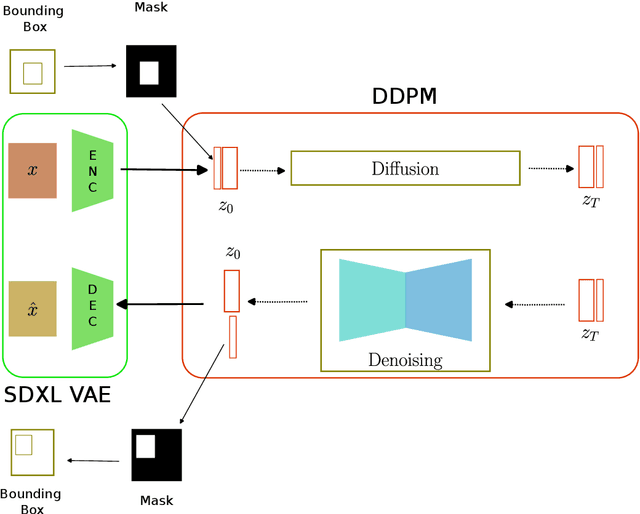
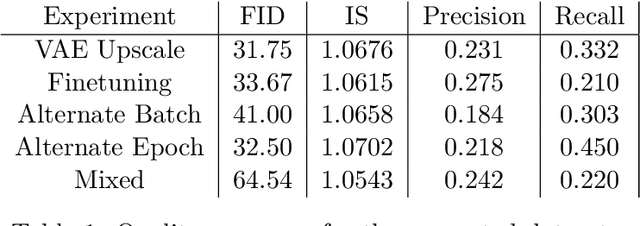
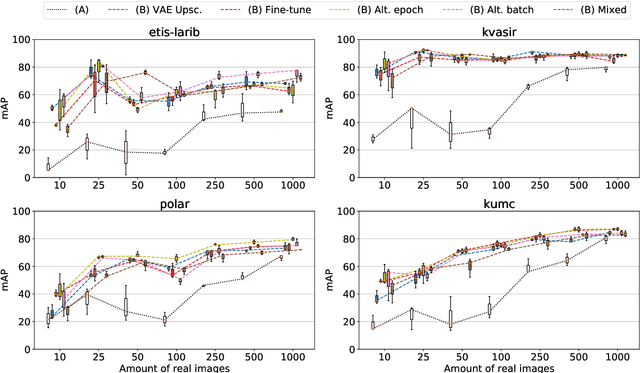
The scarcity of data in medical domains hinders the performance of Deep Learning models. Data augmentation techniques can alleviate that problem, but they usually rely on functional transformations of the data that do not guarantee to preserve the original tasks. To approximate the distribution of the data using generative models is a way of reducing that problem and also to obtain new samples that resemble the original data. Denoising Diffusion models is a promising Deep Learning technique that can learn good approximations of different kinds of data like images, time series or tabular data. Automatic colonoscopy analysis and specifically Polyp localization in colonoscopy videos is a task that can assist clinical diagnosis and treatment. The annotation of video frames for training a deep learning model is a time consuming task and usually only small datasets can be obtained. The fine tuning of application models using a large dataset of generated data could be an alternative to improve their performance. We conduct a set of experiments training different diffusion models that can generate jointly colonoscopy images with localization annotations using a combination of existing open datasets. The generated data is used on various transfer learning experiments in the task of polyp localization with a model based on YOLO v9 on the low data regime.
Intention-aware policy graphs: answering what, how, and why in opaque agents
Sep 27, 2024



Agents are a special kind of AI-based software in that they interact in complex environments and have increased potential for emergent behaviour. Explaining such emergent behaviour is key to deploying trustworthy AI, but the increasing complexity and opaque nature of many agent implementations makes this hard. In this work, we propose a Probabilistic Graphical Model along with a pipeline for designing such model -- by which the behaviour of an agent can be deliberated about -- and for computing a robust numerical value for the intentions the agent has at any moment. We contribute measurements that evaluate the interpretability and reliability of explanations provided, and enables explainability questions such as `what do you want to do now?' (e.g. deliver soup) `how do you plan to do it?' (e.g. returning a plan that considers its skills and the world), and `why would you take this action at this state?' (e.g. explaining how that furthers or hinders its own goals). This model can be constructed by taking partial observations of the agent's actions and world states, and we provide an iterative workflow for increasing the proposed measurements through better design and/or pointing out irrational agent behaviour.
Aloe: A Family of Fine-tuned Open Healthcare LLMs
May 03, 2024



As the capabilities of Large Language Models (LLMs) in healthcare and medicine continue to advance, there is a growing need for competitive open-source models that can safeguard public interest. With the increasing availability of highly competitive open base models, the impact of continued pre-training is increasingly uncertain. In this work, we explore the role of instruct tuning, model merging, alignment, red teaming and advanced inference schemes, as means to improve current open models. To that end, we introduce the Aloe family, a set of open medical LLMs highly competitive within its scale range. Aloe models are trained on the current best base models (Mistral, LLaMA 3), using a new custom dataset which combines public data sources improved with synthetic Chain of Thought (CoT). Aloe models undergo an alignment phase, becoming one of the first few policy-aligned open healthcare LLM using Direct Preference Optimization, setting a new standard for ethical performance in healthcare LLMs. Model evaluation expands to include various bias and toxicity datasets, a dedicated red teaming effort, and a much-needed risk assessment for healthcare LLMs. Finally, to explore the limits of current LLMs in inference, we study several advanced prompt engineering strategies to boost performance across benchmarks, yielding state-of-the-art results for open healthcare 7B LLMs, unprecedented at this scale.
When & How to Transfer with Transfer Learning
Nov 08, 2022



In deep learning, transfer learning (TL) has become the de facto approach when dealing with image related tasks. Visual features learnt for one task have been shown to be reusable for other tasks, improving performance significantly. By reusing deep representations, TL enables the use of deep models in domains with limited data availability, limited computational resources and/or limited access to human experts. Domains which include the vast majority of real-life applications. This paper conducts an experimental evaluation of TL, exploring its trade-offs with respect to performance, environmental footprint, human hours and computational requirements. Results highlight the cases were a cheap feature extraction approach is preferable, and the situations where an expensive fine-tuning effort may be worth the added cost. Finally, a set of guidelines on the use of TL are proposed.