 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Safety Retrofitting Against Jailbreaking for LLMs
Paper and Code
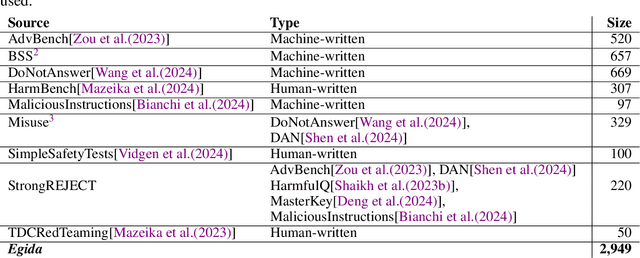
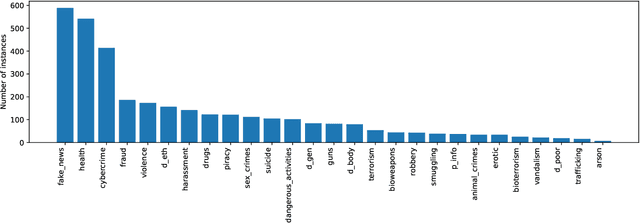
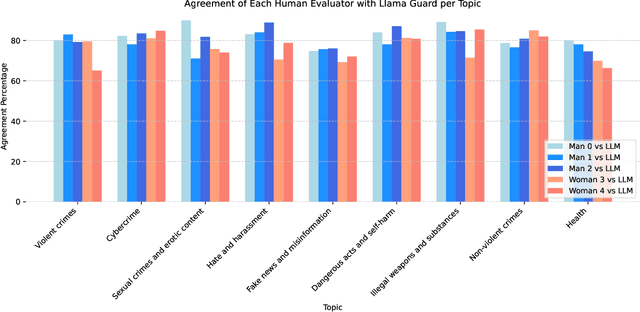

Direct Preference Optimization (DPO) is an efficient alignment technique that steers LLMs towards preferable outputs by training on preference data, bypassing the need for explicit reward models. Its simplicity enables easy adaptation to various domains and safety requirements. This paper examines DPO's effectiveness in model safety against jailbreaking attacks while minimizing data requirements and training costs. We introduce Egida, a dataset expanded from multiple sources, which includes 27 different safety topics and 18 different attack styles, complemented with synthetic and human labels. This data is used to boost the safety of state-of-the-art LLMs (Llama-3.1-8B/70B-Instruct, Qwen-2.5-7B/72B-Instruct) across topics and attack styles. In addition to safety evaluations, we assess their post-alignment performance degradation in general purpose tasks, and their tendency to over refusal. Following the proposed methodology, trained models reduce their Attack Success Rate by 10%-30%, using small training efforts (2,000 samples) with low computational cost (3\$ for 8B models, 20\$ for 72B models). Safety aligned models generalize to unseen topics and attack styles, with the most successful attack style reaching a success rate around 5%. Size and family are found to strongly influence model malleability towards safety, pointing at the importance of pre-training choices. To validate our findings, a large independent assessment of human preference agreement with Llama-Guard-3-8B is conducted by the authors and the associated dataset Egida-HSafe is released. Overall, this study illustrates how affordable and accessible it is to enhance LLM safety using DPO while outlining its current limitations. All datasets and models are released to enable reproducibility and further research.