 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Autonomous Vehicles with Intention-aware Policy Graphs
May 13, 2025



The potential to improve road safety, reduce human driving error, and promote environmental sustainability have enabled the field of autonomous driving to progress rapidly over recent decades. The performance of autonomous vehicles has significantly improved thanks to advancements in Artificial Intelligence, particularly Deep Learning. Nevertheless, the opacity of their decision-making, rooted in the use of accurate yet complex AI models, has created barriers to their societal trust and regulatory acceptance, raising the need for explainability. We propose a post-hoc, model-agnostic solution to provide teleological explanations for the behaviour of an autonomous vehicle in urban environments. Building on Intention-aware Policy Graphs, our approach enables the extraction of interpretable and reliable explanations of vehicle behaviour in the nuScenes dataset from global and local perspectives. We demonstrate the potential of these explanations to assess whether the vehicle operates within acceptable legal boundaries and to identify possible vulnerabilities in autonomous driving datasets and models.
The Aloe Family Recipe for Open and Specialized Healthcare LLMs
May 07, 2025Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.
Automatic Evaluation of Healthcare LLMs Beyond Question-Answering
Feb 10, 2025



Current Large Language Models (LLMs) benchmarks are often based on open-ended or close-ended QA evaluations, avoiding the requirement of human labor. Close-ended measurements evaluate the factuality of responses but lack expressiveness. Open-ended capture the model's capacity to produce discourse responses but are harder to assess for correctness. These two approaches are commonly used, either independently or together, though their relationship remains poorly understood. This work is focused on the healthcare domain, where both factuality and discourse matter greatly. It introduces a comprehensive, multi-axis suite for healthcare LLM evaluation, exploring correlations between open and close benchmarks and metrics. Findings include blind spots and overlaps in current methodologies. As an updated sanity check, we release a new medical benchmark--CareQA--, with both open and closed variants. Finally, we propose a novel metric for open-ended evaluations --Relaxed Perplexity-- to mitigate the identified limitations.
Intention-aware policy graphs: answering what, how, and why in opaque agents
Sep 27, 2024



Agents are a special kind of AI-based software in that they interact in complex environments and have increased potential for emergent behaviour. Explaining such emergent behaviour is key to deploying trustworthy AI, but the increasing complexity and opaque nature of many agent implementations makes this hard. In this work, we propose a Probabilistic Graphical Model along with a pipeline for designing such model -- by which the behaviour of an agent can be deliberated about -- and for computing a robust numerical value for the intentions the agent has at any moment. We contribute measurements that evaluate the interpretability and reliability of explanations provided, and enables explainability questions such as `what do you want to do now?' (e.g. deliver soup) `how do you plan to do it?' (e.g. returning a plan that considers its skills and the world), and `why would you take this action at this state?' (e.g. explaining how that furthers or hinders its own goals). This model can be constructed by taking partial observations of the agent's actions and world states, and we provide an iterative workflow for increasing the proposed measurements through better design and/or pointing out irrational agent behaviour.
Aloe: A Family of Fine-tuned Open Healthcare LLMs
May 03, 2024



As the capabilities of Large Language Models (LLMs) in healthcare and medicine continue to advance, there is a growing need for competitive open-source models that can safeguard public interest. With the increasing availability of highly competitive open base models, the impact of continued pre-training is increasingly uncertain. In this work, we explore the role of instruct tuning, model merging, alignment, red teaming and advanced inference schemes, as means to improve current open models. To that end, we introduce the Aloe family, a set of open medical LLMs highly competitive within its scale range. Aloe models are trained on the current best base models (Mistral, LLaMA 3), using a new custom dataset which combines public data sources improved with synthetic Chain of Thought (CoT). Aloe models undergo an alignment phase, becoming one of the first few policy-aligned open healthcare LLM using Direct Preference Optimization, setting a new standard for ethical performance in healthcare LLMs. Model evaluation expands to include various bias and toxicity datasets, a dedicated red teaming effort, and a much-needed risk assessment for healthcare LLMs. Finally, to explore the limits of current LLMs in inference, we study several advanced prompt engineering strategies to boost performance across benchmarks, yielding state-of-the-art results for open healthcare 7B LLMs, unprecedented at this scale.
When & How to Transfer with Transfer Learning
Nov 08, 2022



In deep learning, transfer learning (TL) has become the de facto approach when dealing with image related tasks. Visual features learnt for one task have been shown to be reusable for other tasks, improving performance significantly. By reusing deep representations, TL enables the use of deep models in domains with limited data availability, limited computational resources and/or limited access to human experts. Domains which include the vast majority of real-life applications. This paper conducts an experimental evaluation of TL, exploring its trade-offs with respect to performance, environmental footprint, human hours and computational requirements. Results highlight the cases were a cheap feature extraction approach is preferable, and the situations where an expensive fine-tuning effort may be worth the added cost. Finally, a set of guidelines on the use of TL are proposed.
Healthy Twitter discussions? Time will tell
Mar 21, 2022



Studying misinformation and how to deal with unhealthy behaviours within online discussions has recently become an important field of research within social studies. With the rapid development of social media, and the increasing amount of available information and sources, rigorous manual analysis of such discourses has become unfeasible. Many approaches tackle the issue by studying the semantic and syntactic properties of discussions following a supervised approach, for example using natural language processing on a dataset labeled for abusive, fake or bot-generated content. Solutions based on the existence of a ground truth are limited to those domains which may have ground truth. However, within the context of misinformation, it may be difficult or even impossible to assign labels to instances. In this context, we consider the use of temporal dynamic patterns as an indicator of discussion health. Working in a domain for which ground truth was unavailable at the time (early COVID-19 pandemic discussions) we explore the characterization of discussions based on the the volume and time of contributions. First we explore the types of discussions in an unsupervised manner, and then characterize these types using the concept of ephemerality, which we formalize. In the end, we discuss the potential use of our ephemerality definition for labeling online discourses based on how desirable, healthy and constructive they are.
What are We Depressed about When We Talk about COVID19: Mental Health Analysis on Tweets Using Natural Language Processing
Apr 29, 2020
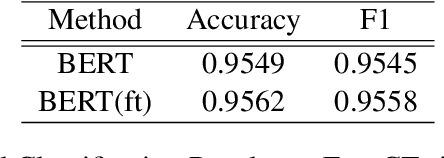

The outbreak of coronavirus disease 2019 (COVID-19) recently has affected human life to a great extent. Besides direct physical and economic threats, the pandemic also indirectly impact people's mental health conditions, which can be overwhelming but difficult to measure. The problem may come from various reasons such as unemployment status, stay-at-home policy, fear for the virus, and so forth. In this work, we focus on applying natural language processing (NLP) techniques to analyze tweets in terms of mental health. We trained deep models that classify each tweet into the following emotions: anger, anticipation, disgust, fear, joy, sadness, surprise and trust. We build the EmoCT (Emotion-Covid19-Tweet) dataset for the training purpose by manually labeling 1,000 English tweets. Furthermore, we propose and compare two methods to find out the reasons that are causing sadness and fear.
Obstruction level detection of sewer videos using convolutional neural networks
Feb 04, 2020
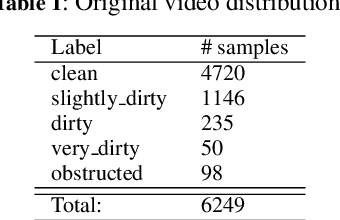
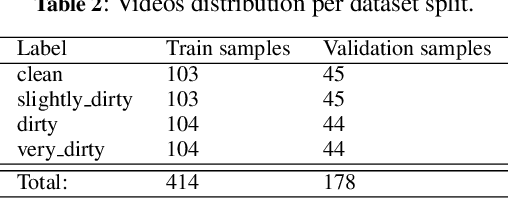
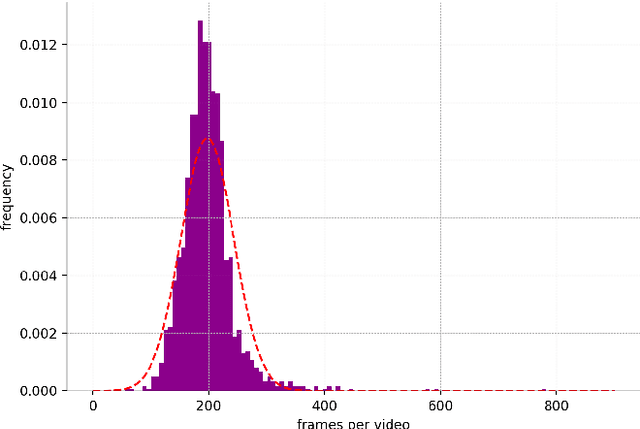
Worldwide, sewer networks are designed to transport wastewater to a centralized treatment plant to be treated and returned to the environment. This process is critical for the current society, preventing waterborne illnesses, providing safe drinking water and enhancing general sanitation. To keep a sewer network perfectly operational, sampling inspections are performed constantly to identify obstructions. Typically, a Closed-Circuit Television system is used to record the inside of pipes and report the obstruction level, which may trigger a cleaning operative. Currently, the obstruction level assessment is done manually, which is time-consuming and inconsistent. In this work, we design a methodology to train a Convolutional Neural Network for identifying the level of obstruction in pipes, thus reducing the human effort required on such a frequent and repetitive task. We gathered a database of videos that are explored and adapted to generate useful frames to fed into the model. Our resulting classifier obtains deployment ready performances. To validate the consistency of the approach and its industrial applicability, we integrate the Layer-wise Relevance Propagation explainability technique, which enables us to further understand the behavior of the neural network for this task. In the end, the proposed system can provide higher speed, accuracy, and consistency in the process of sewer examination. Our analysis also uncovers some guidelines on how to further improve the quality of the data gathering methodology.