 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Efficient DNN-Ensembles with Evolutionary Computation
Sep 18, 2020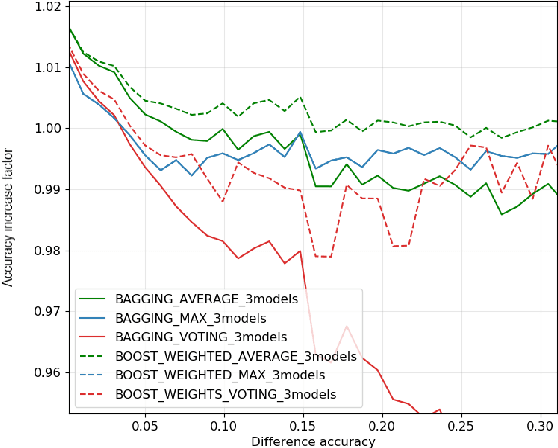
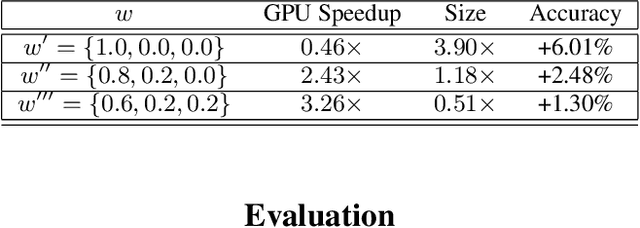
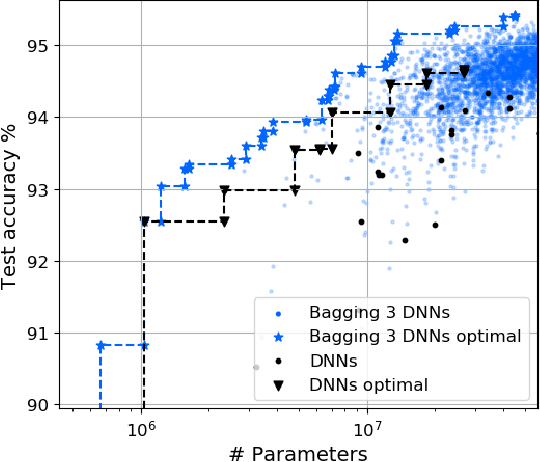
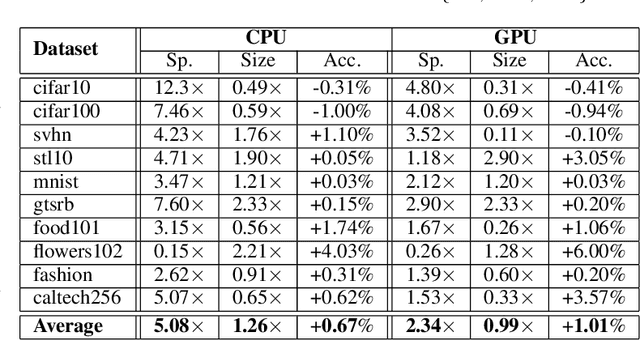
In this work, we leverage ensemble learning as a tool for the creation of faster, smaller, and more accurate deep learning models. We demonstrate that we can jointly optimize for accuracy, inference time, and the number of parameters by combining DNN classifiers. To achieve this, we combine multiple ensemble strategies: bagging, boosting, and an ordered chain of classifiers. To reduce the number of DNN ensemble evaluations during the search, we propose EARN, an evolutionary approach that optimizes the ensemble according to three objectives regarding the constraints specified by the user. We run EARN on 10 image classification datasets with an initial pool of 32 state-of-the-art DCNN on both CPU and GPU platforms, and we generate models with speedups up to $7.60\times$, reductions of parameters by $10\times$, or increases in accuracy up to $6.01\%$ regarding the best DNN in the pool. In addition, our method generates models that are $5.6\times$ faster than the state-of-the-art methods for automatic model generation.
A Closer Look at Art Mediums: The MAMe Image Classification Dataset
Jul 27, 2020
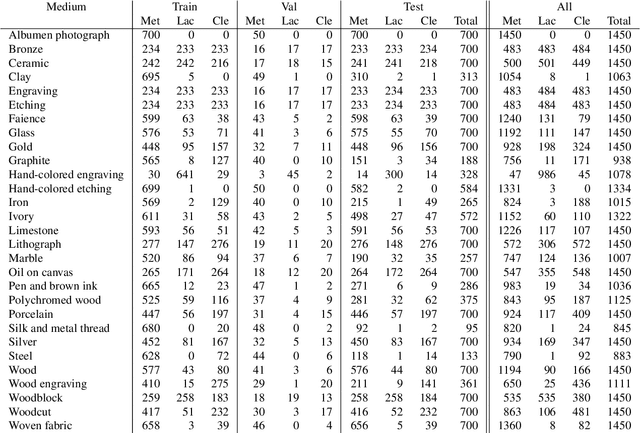
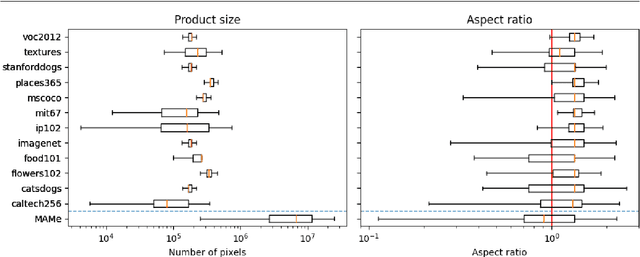
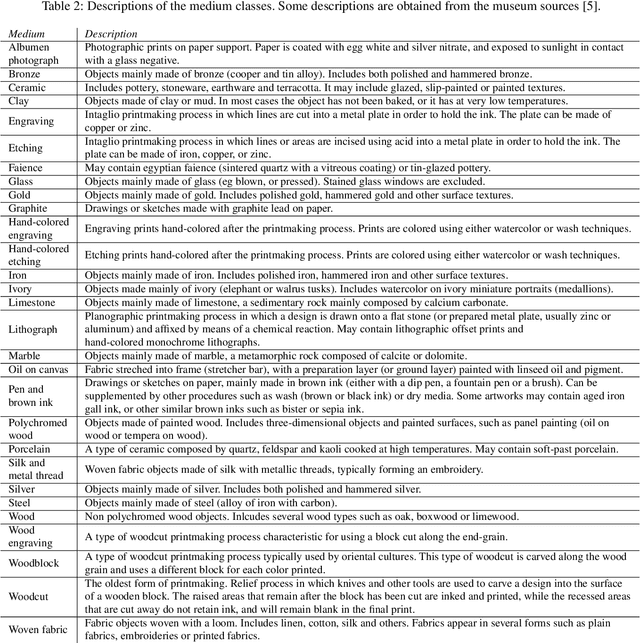
Art is an expression of human creativity, skill and technology. An exceptionally rich source of visual content. In the context of AI image processing systems, artworks represent one of the most challenging domains conceivable: Properly perceiving art requires attention to detail, a huge generalization capacity, and recognizing both simple and complex visual patterns. To challenge the AI community, this work introduces a novel image classification task focused on museum art mediums, the MAMe dataset. Data is gathered from three different museums, and aggregated by art experts into 29 classes of medium (i.e. materials and techniques). For each class, MAMe provides a minimum of 850 images (700 for training) of high-resolution and variable shape. The combination of volume, resolution and shape allows MAMe to fill a void in current image classification challenges, empowering research in aspects so far overseen by the research community. After reviewing the singularity of MAMe in the context of current image classification tasks, a thorough description of the task is provided, together with dataset statistics. Baseline experiments are conducted using well-known architectures, to highlight both the feasibility and complexity of the task proposed. Finally, these baselines are inspected using explainability methods and expert knowledge, to gain insight on the challenges that remain ahead.
MetH: A family of high-resolution and variable-shape image challenges
Nov 29, 2019


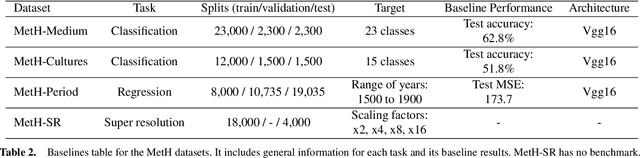
High-resolution and variable-shape images have not yet been properly addressed by the AI community. The approach of down-sampling data often used with convolutional neural networks is sub-optimal for many tasks, and has too many drawbacks to be considered a sustainable alternative. In sight of the increasing importance of problems that can benefit from exploiting high-resolution (HR) and variable-shape, and with the goal of promoting research in that direction, we introduce a new family of datasets (MetH). The four proposed problems include two image classification, one image regression and one super resolution task. Each of these datasets contains thousands of art pieces captured by HR and variable-shape images, labeled by experts at the Metropolitan Museum of Art. We perform an analysis, which shows how the proposed tasks go well beyond current public alternatives in both pixel size and aspect ratio variance. At the same time, the performance obtained by popular architectures on these tasks shows that there is ample room for improvement. To wrap up the relevance of the contribution we review the fields, both in AI and high-performance computing, that could benefit from the proposed challenges.
Random Forest as a Tumour Genetic Marker Extractor
Nov 26, 2019
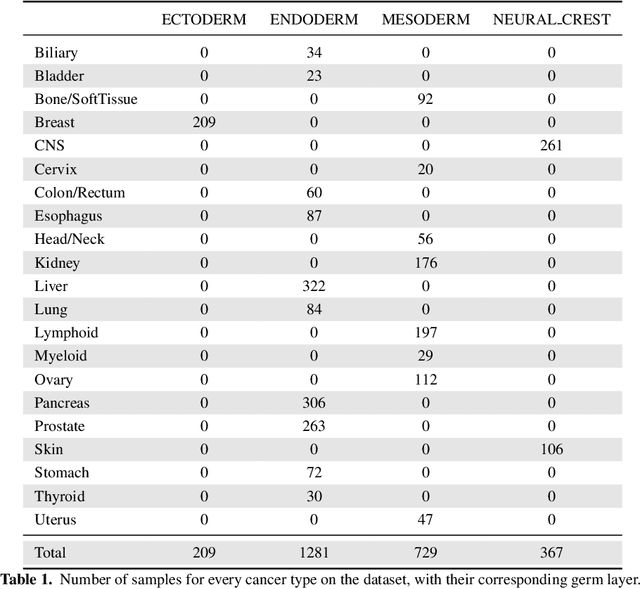
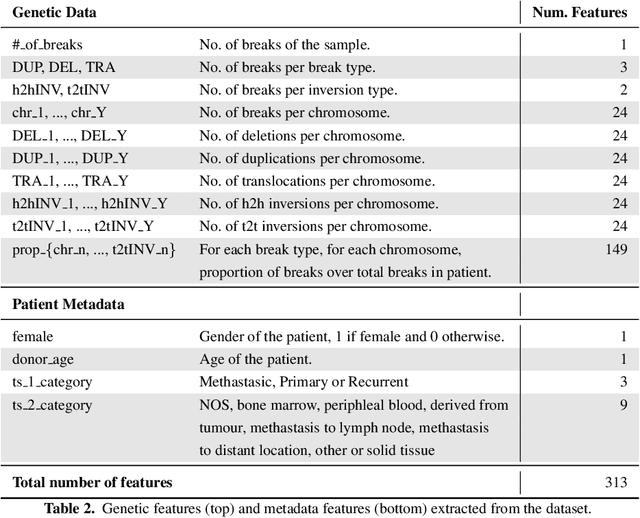

Finding tumour genetic markers is essential to biomedicine due to their relevance for cancer detection and therapy development. In this paper, we explore a recently released dataset of chromosome rearrangements in 2,586 cancer patients, where different sorts of alterations have been detected. Using a Random Forest classifier, we evaluate the relevance of several features (some directly available in the original data, some engineered by us) related to chromosome rearrangements. This evaluation results in a set of potential tumour genetic markers, some of which are validated in the bibliography, while others are potentially novel.
Feature discriminativity estimation in CNNs for transfer learning
Nov 08, 2019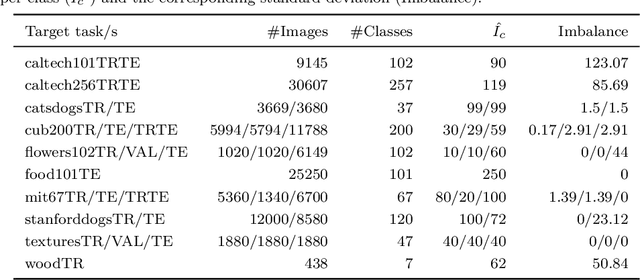
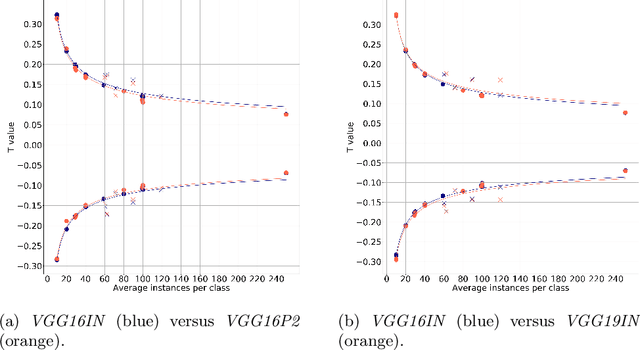
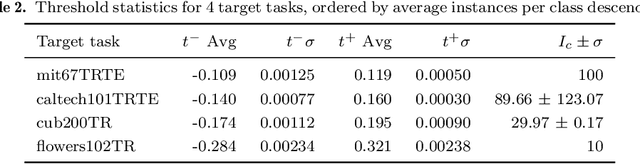
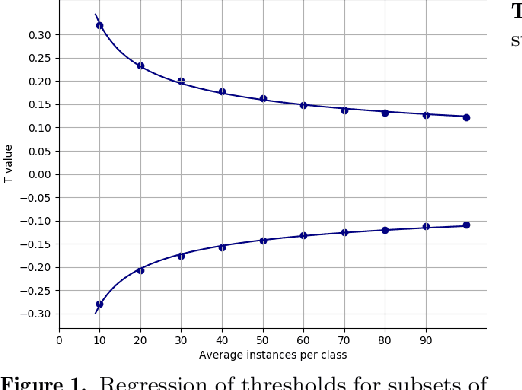
The purpose of feature extraction on convolutional neural networks is to reuse deep representations learnt for a pre-trained model to solve a new, potentially unrelated problem. However, raw feature extraction from all layers is unfeasible given the massive size of these networks. Recently, a supervised method using complexity reduction was proposed, resulting in significant improvements in performance for transfer learning tasks. This approach first computes the discriminative power of features, and then discretises them using thresholds computed for the task. In this paper, we analyse the behaviour of these thresholds, with the purpose of finding a methodology for their estimation. After a comprehensive study, we find a very strong correlation between problem size and threshold value, with coefficient of determination above 90%. These results allow us to propose a unified model for threshold estimation, with potential application to transfer learning tasks.
* Presented in the 22nd International Conference of the Catalan Association for Artificial Intelligence (CCIA 19)
Resource-aware Elastic Swap Random Forest for Evolving Data Streams
May 14, 2019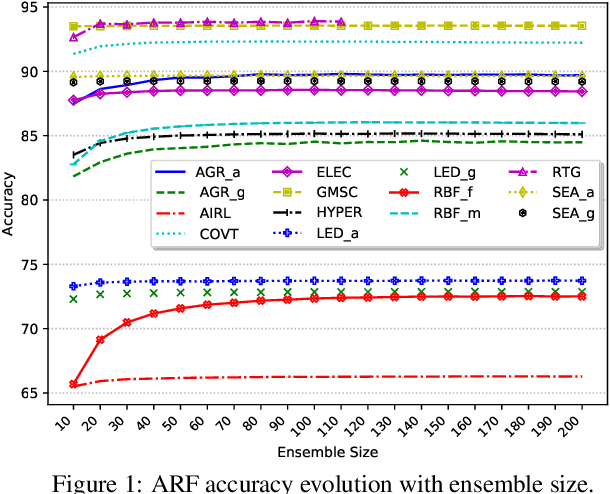
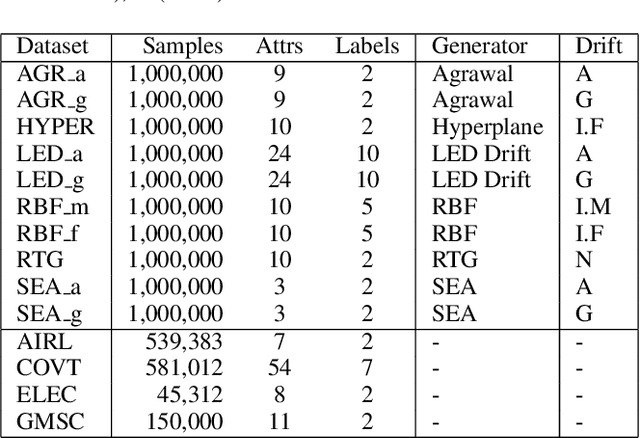
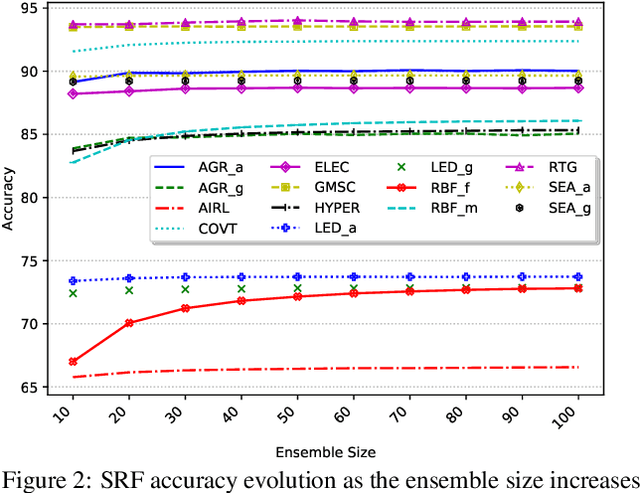
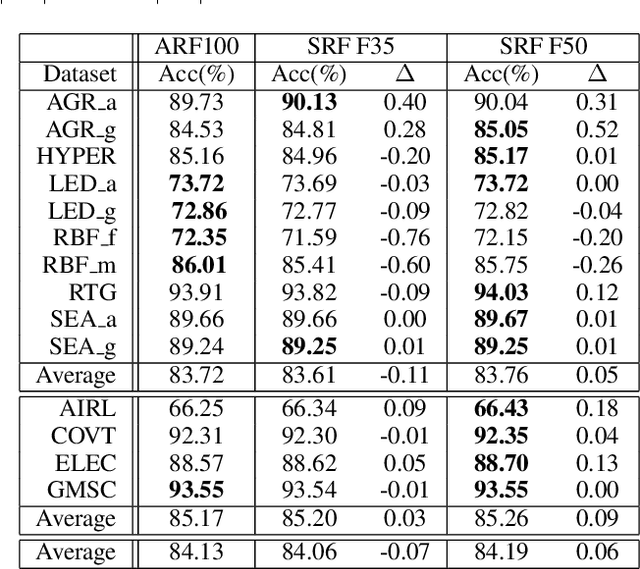
Continual learning based on data stream mining deals with ubiquitous sources of Big Data arriving at high-velocity and in real-time. Adaptive Random Forest ({\em ARF}) is a popular ensemble method used for continual learning due to its simplicity in combining adaptive leveraging bagging with fast random Hoeffding trees. While the default ARF size provides competitive accuracy, it is usually over-provisioned resulting in the use of additional classifiers that only contribute to increasing CPU and memory consumption with marginal impact in the overall accuracy. This paper presents Elastic Swap Random Forest ({\em ESRF}), a method for reducing the number of trees in the ARF ensemble while providing similar accuracy. {\em ESRF} extends {\em ARF} with two orthogonal components: 1) a swap component that splits learners into two sets based on their accuracy (only classifiers with the highest accuracy are used to make predictions); and 2) an elastic component for dynamically increasing or decreasing the number of classifiers in the ensemble. The experimental evaluation of {\em ESRF} and comparison with the original {\em ARF} shows how the two new components contribute to reducing the number of classifiers up to one third while providing almost the same accuracy, resulting in speed-ups in terms of per-sample execution time close to 3x.
A Visual Distance for WordNet
Apr 27, 2018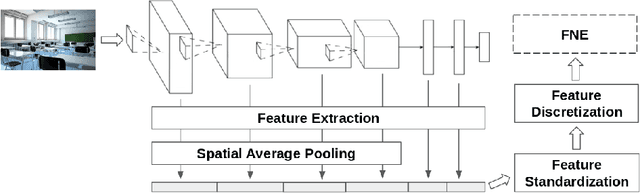
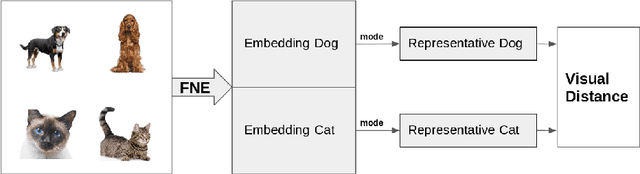
Measuring the distance between concepts is an important field of study of Natural Language Processing, as it can be used to improve tasks related to the interpretation of those same concepts. WordNet, which includes a wide variety of concepts associated with words (i.e., synsets), is often used as a source for computing those distances. In this paper, we explore a distance for WordNet synsets based on visual features, instead of lexical ones. For this purpose, we extract the graphic features generated within a deep convolutional neural networks trained with ImageNet and use those features to generate a representative of each synset. Based on those representatives, we define a distance measure of synsets, which complements the traditional lexical distances. Finally, we propose some experiments to evaluate its performance and compare it with the current state-of-the-art.
Low-Precision Floating-Point Schemes for Neural Network Training
Apr 14, 2018
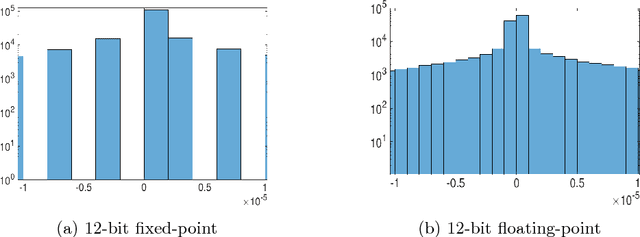
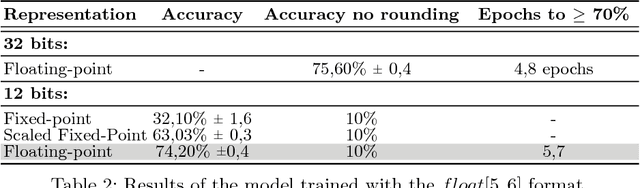
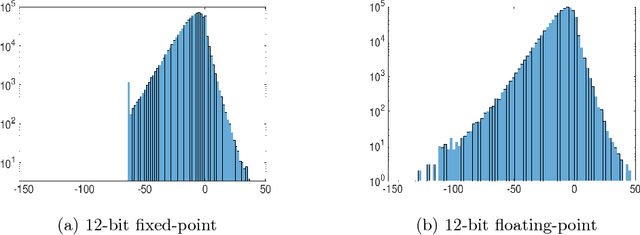
The use of low-precision fixed-point arithmetic along with stochastic rounding has been proposed as a promising alternative to the commonly used 32-bit floating point arithmetic to enhance training neural networks training in terms of performance and energy efficiency. In the first part of this paper, the behaviour of the 12-bit fixed-point arithmetic when training a convolutional neural network with the CIFAR-10 dataset is analysed, showing that such arithmetic is not the most appropriate for the training phase. After that, the paper presents and evaluates, under the same conditions, alternative low-precision arithmetics, starting with the 12-bit floating-point arithmetic. These two representations are then leveraged using local scaling in order to increase accuracy and get closer to the baseline 32-bit floating-point arithmetic. Finally, the paper introduces a simplified model in which both the outputs and the gradients of the neural networks are constrained to power-of-two values, just using 7 bits for their representation. The evaluation demonstrates a minimal loss in accuracy for the proposed Power-of-Two neural network, avoiding the use of multiplications and divisions and thereby, significantly reducing the training time as well as the energy consumption and memory requirements during the training and inference phases.
On the Behavior of Convolutional Nets for Feature Extraction
Jan 29, 2018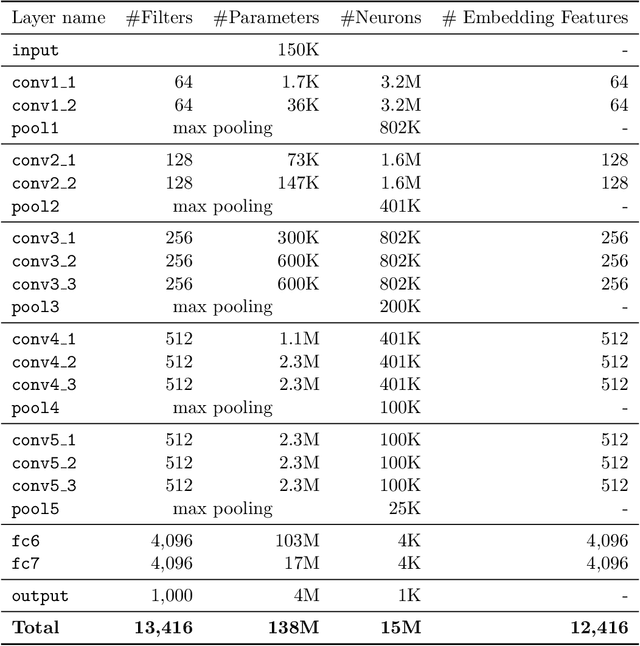
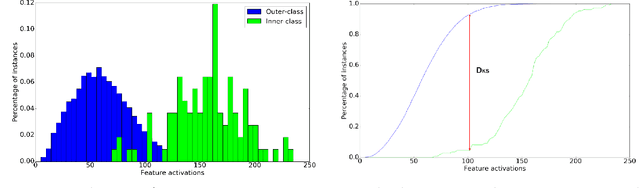
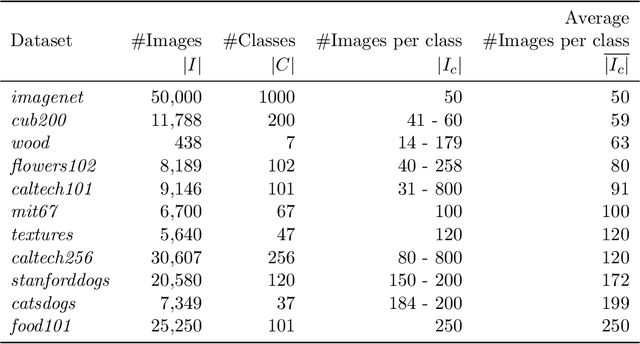

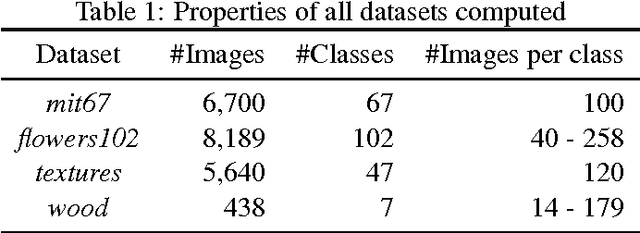
Deep neural networks are representation learning techniques. During training, a deep net is capable of generating a descriptive language of unprecedented size and detail in machine learning. Extracting the descriptive language coded within a trained CNN model (in the case of image data), and reusing it for other purposes is a field of interest, as it provides access to the visual descriptors previously learnt by the CNN after processing millions of images, without requiring an expensive training phase. Contributions to this field (commonly known as feature representation transfer or transfer learning) have been purely empirical so far, extracting all CNN features from a single layer close to the output and testing their performance by feeding them to a classifier. This approach has provided consistent results, although its relevance is limited to classification tasks. In a completely different approach, in this paper we statistically measure the discriminative power of every single feature found within a deep CNN, when used for characterizing every class of 11 datasets. We seek to provide new insights into the behavior of CNN features, particularly the ones from convolutional layers, as this can be relevant for their application to knowledge representation and reasoning. Our results confirm that low and middle level features may behave differently to high level features, but only under certain conditions. We find that all CNN features can be used for knowledge representation purposes both by their presence or by their absence, doubling the information a single CNN feature may provide. We also study how much noise these features may include, and propose a thresholding approach to discard most of it. All these insights have a direct application to the generation of CNN embedding spaces.
Building Graph Representations of Deep Vector Embeddings
Aug 09, 2017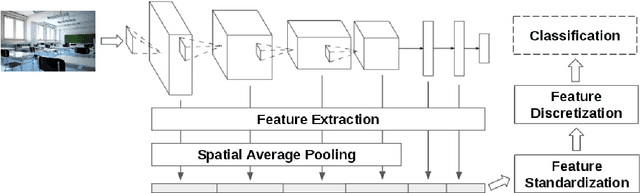
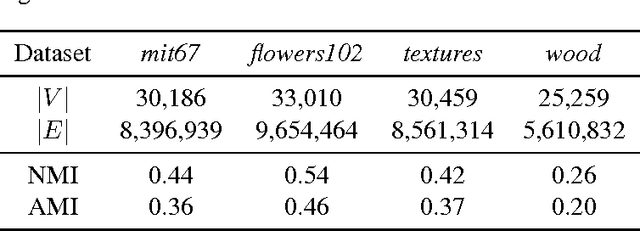
Patterns stored within pre-trained deep neural networks compose large and powerful descriptive languages that can be used for many different purposes. Typically, deep network representations are implemented within vector embedding spaces, which enables the use of traditional machine learning algorithms on top of them. In this short paper we propose the construction of a graph embedding space instead, introducing a methodology to transform the knowledge coded within a deep convolutional network into a topological space (i.e. a network). We outline how such graph can hold data instances, data features, relations between instances and features, and relations among features. Finally, we introduce some preliminary experiments to illustrate how the resultant graph embedding space can be exploited through graph analytics algorithms.