 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Efficient DNN-Ensembles with Evolutionary Computation
Sep 18, 2020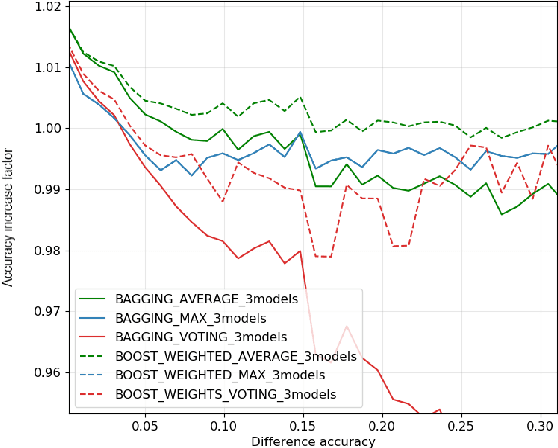
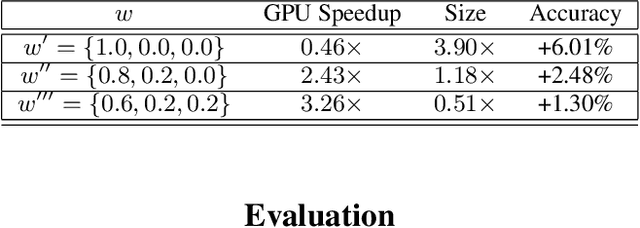
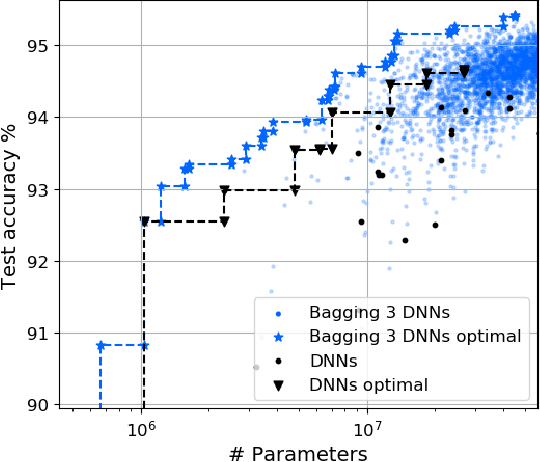
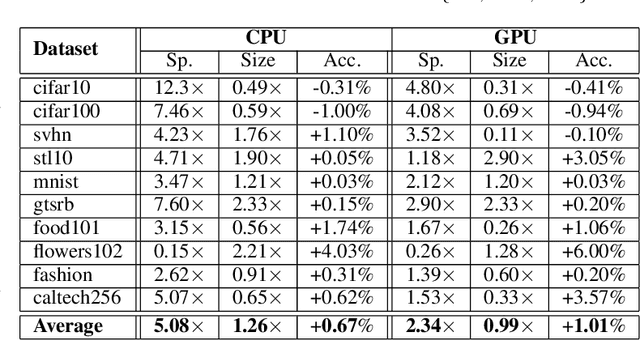
In this work, we leverage ensemble learning as a tool for the creation of faster, smaller, and more accurate deep learning models. We demonstrate that we can jointly optimize for accuracy, inference time, and the number of parameters by combining DNN classifiers. To achieve this, we combine multiple ensemble strategies: bagging, boosting, and an ordered chain of classifiers. To reduce the number of DNN ensemble evaluations during the search, we propose EARN, an evolutionary approach that optimizes the ensemble according to three objectives regarding the constraints specified by the user. We run EARN on 10 image classification datasets with an initial pool of 32 state-of-the-art DCNN on both CPU and GPU platforms, and we generate models with speedups up to $7.60\times$, reductions of parameters by $10\times$, or increases in accuracy up to $6.01\%$ regarding the best DNN in the pool. In addition, our method generates models that are $5.6\times$ faster than the state-of-the-art methods for automatic model generation.
Low-Precision Floating-Point Schemes for Neural Network Training
Apr 14, 2018
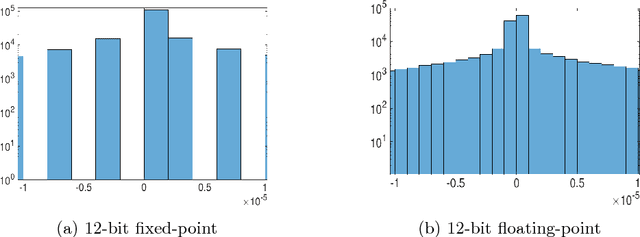
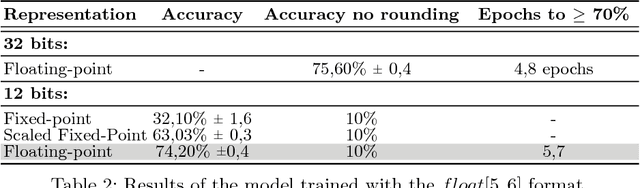
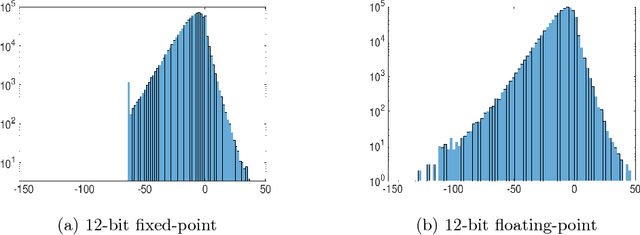
The use of low-precision fixed-point arithmetic along with stochastic rounding has been proposed as a promising alternative to the commonly used 32-bit floating point arithmetic to enhance training neural networks training in terms of performance and energy efficiency. In the first part of this paper, the behaviour of the 12-bit fixed-point arithmetic when training a convolutional neural network with the CIFAR-10 dataset is analysed, showing that such arithmetic is not the most appropriate for the training phase. After that, the paper presents and evaluates, under the same conditions, alternative low-precision arithmetics, starting with the 12-bit floating-point arithmetic. These two representations are then leveraged using local scaling in order to increase accuracy and get closer to the baseline 32-bit floating-point arithmetic. Finally, the paper introduces a simplified model in which both the outputs and the gradients of the neural networks are constrained to power-of-two values, just using 7 bits for their representation. The evaluation demonstrates a minimal loss in accuracy for the proposed Power-of-Two neural network, avoiding the use of multiplications and divisions and thereby, significantly reducing the training time as well as the energy consumption and memory requirements during the training and inference phases.