 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIANT - Global Path Integration and Attentive Graph Networks for Multi-Agent Trajectory Planning
Mar 04, 2026This paper presents a novel approach to multi-robot collision avoidance that integrates global path planning with local navigation strategies, utilizing attentive graph neural networks to manage dynamic interactions among agents. We introduce a local navigation model that leverages pre-planned global paths, allowing robots to adhere to optimal routes while dynamically adjusting to environmental changes. The models robustness is enhanced through the introduction of noise during training, resulting in superior performance in complex, dynamic environments. Our approach is evaluated against established baselines, including NH-ORCA, DRL-NAV, and GA3C-CADRL, across various structurally diverse simulated scenarios. The results demonstrate that our model achieves consistently higher success rates, lower collision rates, and more efficient navigation, particularly in challenging scenarios where baseline models struggle. This work offers an advancement in multi-robot navigation, with implications for robust performance in complex, dynamic environments with varying degrees of complexity, such as those encountered in logistics, where adaptability is essential for accommodating unforeseen obstacles and unpredictable changes.
NewsReX: A More Efficient Approach to News Recommendation with Keras 3 and JAX
Aug 29, 2025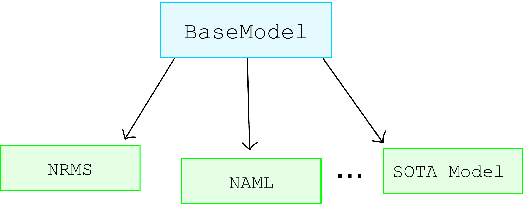
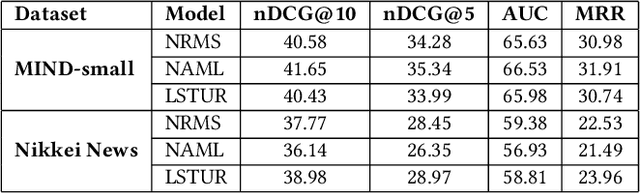
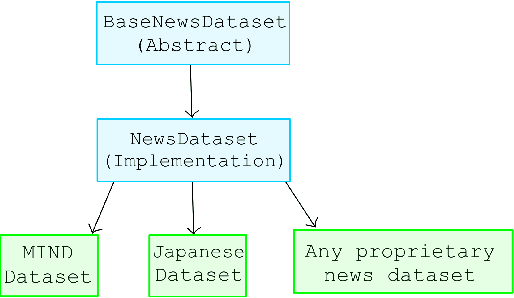
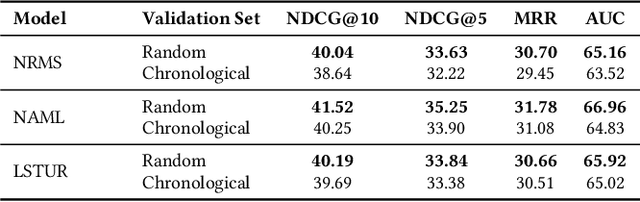
Reproducing and comparing results in news recommendation research has become increasingly difficult. This is due to a fragmented ecosystem of diverse codebases, varied configurations, and mainly due to resource-intensive models. We introduce NewsReX, an open-source library designed to streamline this process. Our key contribution is a modern implementation built on Keras 3 and JAX, which provides an increase in computational efficiency. Experiments show that NewsReX is faster than current implementations. To support broader research, we provide a straightforward guide and scripts for training models on custom datasets. We validated this functionality using a proprietary Japanese news dataset from Nikkei News, a leading Japanese media corporation renowned for its comprehensive coverage of business, economic, and financial news. NewsReX makes reproducing complex experiments faster and more accessible to a wider range of hardware making sure the speed up it also achieved for less powerful GPUs, like an 8GB RTX 3060 Ti. Beyond the library, this paper offers an analysis of key training parameters often overlooked in the literature, including the effect of different negative sampling strategies, the varying number of epochs, the impact of random batching, and more. This supplementary analysis serves as a valuable reference for future research, aiming to reduce redundant computation when comparing baselines and guide best practices. Code available at https://github.com/igor17400/NewsReX.
LLM-Augmented Graph Neural Recommenders: Integrating User Reviews
Apr 03, 2025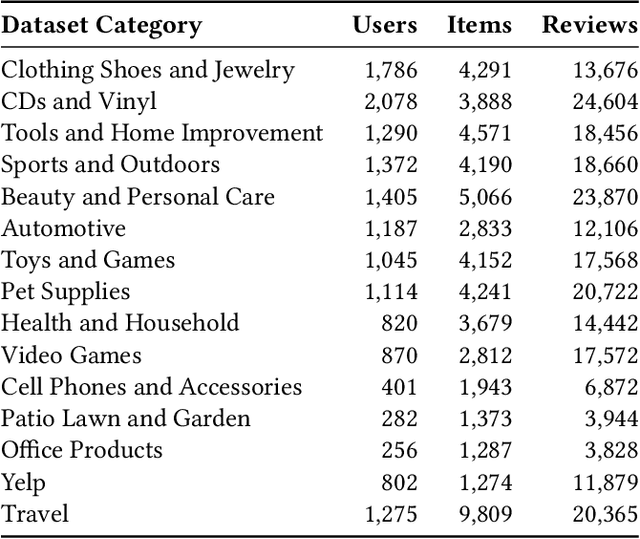
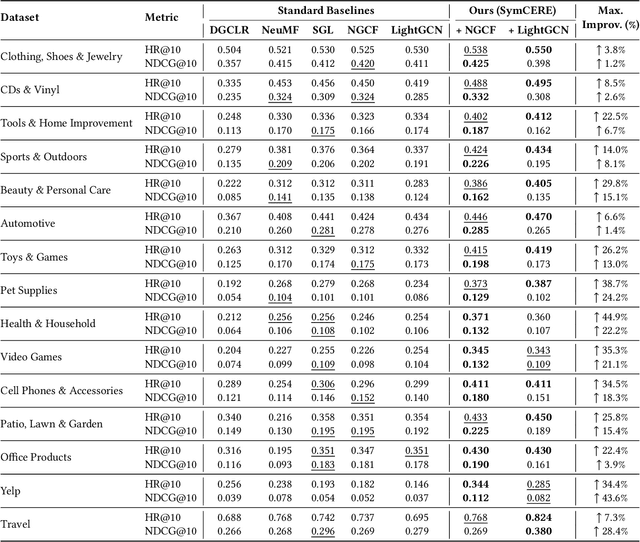
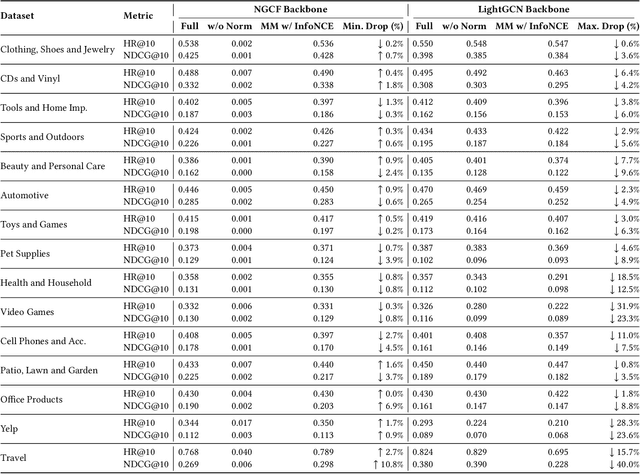

Recommender systems increasingly aim to combine signals from both user reviews and purchase (or other interaction) behaviors. While user-written comments provide explicit insights about preferences, merging these textual representations from large language models (LLMs) with graph-based embeddings of user actions remains a challenging task. In this work, we propose a framework that employs both a Graph Neural Network (GNN)-based model and an LLM to produce review-aware representations, preserving review semantics while mitigating textual noise. Our approach utilizes a hybrid objective that balances user-item interactions against text-derived features, ensuring that user's both behavioral and linguistic signals are effectively captured. We evaluate this method on multiple datasets from diverse application domains, demonstrating consistent improvements over a baseline GNN-based recommender model. Notably, our model achieves significant gains in recommendation accuracy when review data is sparse or unevenly distributed. These findings highlight the importance of integrating LLM-driven textual feedback with GNN-derived user behavioral patterns to develop robust, context-aware recommender systems.
ContinuouSP: Generative Model for Crystal Structure Prediction with Invariance and Continuity
Feb 04, 2025


The discovery of new materials using crystal structure prediction (CSP) based on generative machine learning models has become a significant research topic in recent years. In this paper, we study invariance and continuity in the generative machine learning for CSP. We propose a new model, called ContinuouSP, which effectively handles symmetry and periodicity in crystals. We clearly formulate the invariance and the continuity, and construct a model based on the energy-based model. Our preliminary evaluation demonstrates the effectiveness of this model with the CSP task.
Annealing Machine-assisted Learning of Graph Neural Network for Combinatorial Optimization
Jan 10, 2025



While Annealing Machines (AM) have shown increasing capabilities in solving complex combinatorial problems, positioning themselves as a more immediate alternative to the expected advances of future fully quantum solutions, there are still scaling limitations. In parallel, Graph Neural Networks (GNN) have been recently adapted to solve combinatorial problems, showing competitive results and potentially high scalability due to their distributed nature. We propose a merging approach that aims at retaining both the accuracy exhibited by AMs and the representational flexibility and scalability of GNNs. Our model considers a compression step, followed by a supervised interaction where partial solutions obtained from the AM are used to guide local GNNs from where node feature representations are obtained and combined to initialize an additional GNN-based solver that handles the original graph's target problem. Intuitively, the AM can solve the combinatorial problem indirectly by infusing its knowledge into the GNN. Experiments on canonical optimization problems show that the idea is feasible, effectively allowing the AM to solve size problems beyond its original limits.
From Votes to Volatility Predicting the Stock Market on Election Day
Dec 15, 2024

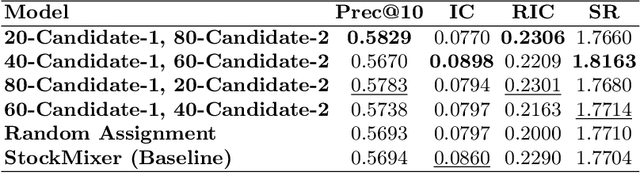
Stock market forecasting has been a topic of extensive research, aiming to provide investors with optimal stock recommendations for higher returns. In recent years, this field has gained even more attention due to the widespread adoption of deep learning models. While these models have achieved impressive accuracy in predicting stock behavior, tailoring them to specific scenarios has become increasingly important. Election Day represents one such critical scenario, characterized by intensified market volatility, as the winning candidate's policies significantly impact various economic sectors and companies. To address this challenge, we propose the Election Day Stock Market Forecasting (EDSMF) Model. Our approach leverages the contextual capabilities of large language models alongside specialized agents designed to analyze the political and economic consequences of elections. By building on a state-of-the-art architecture, we demonstrate that EDSMF improves the predictive performance of the S&P 500 during this uniquely volatile day.
Graph-Enhanced EEG Foundation Model
Nov 29, 2024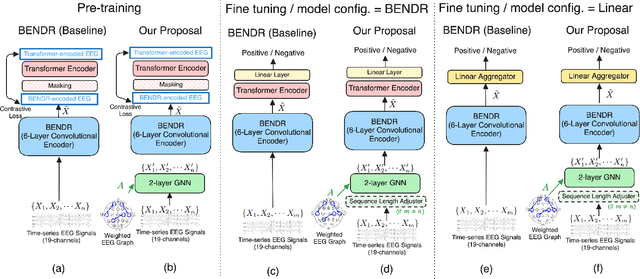

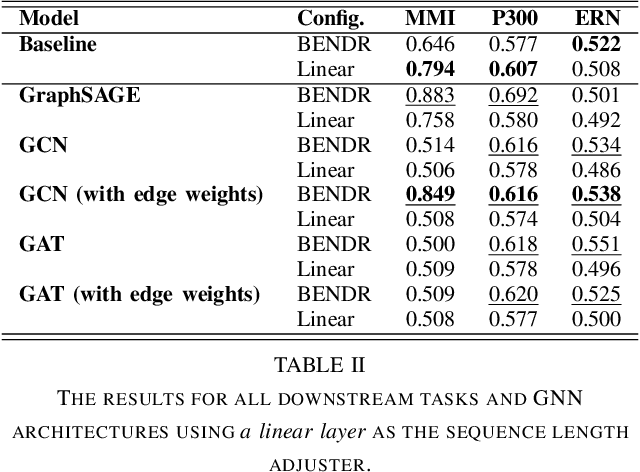
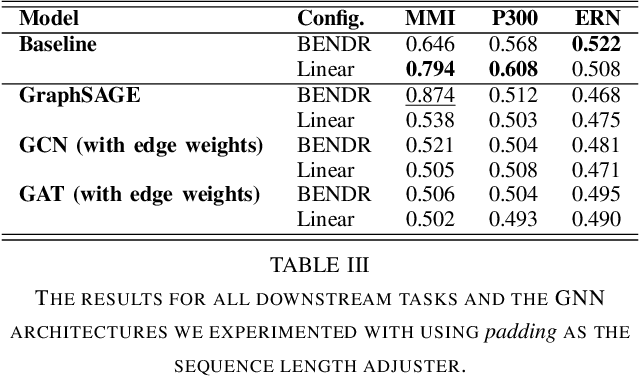
Electroencephalography (EEG) signals provide critical insights for applications in disease diagnosis and healthcare. However, the scarcity of labeled EEG data poses a significant challenge. Foundation models offer a promising solution by leveraging large-scale unlabeled data through pre-training, enabling strong performance across diverse tasks. While both temporal dynamics and inter-channel relationships are vital for understanding EEG signals, existing EEG foundation models primarily focus on the former, overlooking the latter. To address this limitation, we propose a novel foundation model for EEG that integrates both temporal and inter-channel information. Our architecture combines Graph Neural Networks (GNNs), which effectively capture relational structures, with a masked autoencoder to enable efficient pre-training. We evaluated our approach using three downstream tasks and experimented with various GNN architectures. The results demonstrate that our proposed model, particularly when employing the GCN architecture with optimized configurations, consistently outperformed baseline methods across all tasks. These findings suggest that our model serves as a robust foundation model for EEG analysis.
Graph Adapter of EEG Foundation Models for Parameter Efficient Fine Tuning
Nov 25, 2024



In diagnosing mental diseases from electroencephalography (EEG) data, neural network models such as Transformers have been employed to capture temporal dynamics. Additionally, it is crucial to learn the spatial relationships between EEG sensors, for which Graph Neural Networks (GNNs) are commonly used. However, fine-tuning large-scale complex neural network models simultaneously to capture both temporal and spatial features increases computational costs due to the more significant number of trainable parameters. It causes the limited availability of EEG datasets for downstream tasks, making it challenging to fine-tune large models effectively. We propose EEG-GraphAdapter (EGA), a parameter-efficient fine-tuning (PEFT) approach to address these challenges. EGA is integrated into pre-trained temporal backbone models as a GNN-based module and fine-tuned itself alone while keeping the backbone model parameters frozen. This enables the acquisition of spatial representations of EEG signals for downstream tasks, significantly reducing computational overhead and data requirements. Experimental evaluations on healthcare-related downstream tasks of Major Depressive Disorder and Abnormality Detection demonstrate that our EGA improves performance by up to 16.1% in the F1-score compared with the backbone BENDR model.
Multimodal Point-of-Interest Recommendation
Oct 07, 2024



Large Language Models are applied to recommendation tasks such as items to buy and news articles to read. Point of Interest is quite a new area to sequential recommendation based on language representations of multimodal datasets. As a first step to prove our concepts, we focused on restaurant recommendation based on each user's past visit history. When choosing a next restaurant to visit, a user would consider genre and location of the venue and, if available, pictures of dishes served there. We created a pseudo restaurant check-in history dataset from the Foursquare dataset and the FoodX-251 dataset by converting pictures into text descriptions with a multimodal model called LLaVA, and used a language-based sequential recommendation framework named Recformer proposed in 2023. A model trained on this semi-multimodal dataset has outperformed another model trained on the same dataset without picture descriptions. This suggests that this semi-multimodal model reflects actual human behaviours and that our path to a multimodal recommendation model is in the right direction.
A Prompting-Based Representation Learning Method for Recommendation with Large Language Models
Sep 25, 2024



In recent years, Recommender Systems (RS) have witnessed a transformative shift with the advent of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). Models such as GPT-3.5/4, Llama, have demonstrated unprecedented capabilities in understanding and generating human-like text. The extensive information pre-trained by these LLMs allows for the potential to capture a more profound semantic representation from different contextual information of users and items. While the great potential lies behind the thriving of LLMs, the challenge of leveraging user-item preferences from contextual information and its alignment with the improvement of Recommender Systems needs to be addressed. Believing that a better understanding of the user or item itself can be the key factor in improving recommendation performance, we conduct research on generating informative profiles using state-of-the-art LLMs. To boost the linguistic abilities of LLMs in Recommender Systems, we introduce the Prompting-Based Representation Learning Method for Recommendation (P4R). In our P4R framework, we utilize the LLM prompting strategy to create personalized item profiles. These profiles are then transformed into semantic representation spaces using a pre-trained BERT model for text embedding. Furthermore, we incorporate a Graph Convolution Network (GCN) for collaborative filtering representation. The P4R framework aligns these two embedding spaces in order to address the general recommendation tasks. In our evaluation, we compare P4R with state-of-the-art Recommender models and assess the quality of prompt-based profile generation.