 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization-Guided Foreground Augmentation in Autonomous Driving
Apr 21, 2026Autonomous driving systems often degrade under adverse visibility conditions-such as rain, nighttime, or snow-where online scene geometry (e.g., lane dividers, road boundaries, and pedestrian crossings) becomes sparse or fragmented. While high-definition (HD) maps can provide missing structural context, they are costly to construct and maintain at scale. We propose Localization-Guided Foreground Augmentation (LG-FA), a lightweight and plug-and-play inference module that enhances foreground perception by enriching geometric context online. LG-FA: (i) incrementally constructs a sparse global vector layer from per-frame Bird's-Eye View (BEV) predictions; (ii) estimates ego pose via class-constrained geometric alignment, jointly improving localization and completing missing local topology; and (iii) reprojects the augmented foreground into a unified global frame to improve per-frame predictions. Experiments on challenging nuScenes sequences demonstrate that LG-FA improves the geometric completeness and temporal stability of BEV representations, reduces localization error, and produces globally consistent lane and topology reconstructions. The module can be seamlessly integrated into existing BEV-based perception systems without backbone modification. By providing a reliable geometric context prior, LG-FA enhances temporal consistency and supplies stable structural support for downstream modules such as tracking and decision-making.
TrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer
Feb 24, 2026Mobility trajectories are essential for understanding urban dynamics and enhancing urban planning, yet access to such data is frequently hindered by privacy concerns. This research introduces a transformative framework for generating large-scale urban mobility trajectories, employing a novel application of a transformer-based model pre-trained and fine-tuned through a two-phase process. Initially, trajectory generation is conceptualized as an offline reinforcement learning (RL) problem, with a significant reduction in vocabulary space achieved during tokenization. The integration of Inverse Reinforcement Learning (IRL) allows for the capture of trajectory-wise reward signals, leveraging historical data to infer individual mobility preferences. Subsequently, the pre-trained model is fine-tuned using the constructed reward model, effectively addressing the challenges inherent in traditional RL-based autoregressive methods, such as long-term credit assignment and handling of sparse reward environments. Comprehensive evaluations on multiple datasets illustrate that our framework markedly surpasses existing models in terms of reliability and diversity. Our findings not only advance the field of urban mobility modeling but also provide a robust methodology for simulating urban data, with significant implications for traffic management and urban development planning. The implementation is publicly available at https://github.com/Wangjw6/TrajGPT_R.
Towards Resilient Transportation: A Conditional Transformer for Accident-Informed Traffic Forecasting
Dec 10, 2025Traffic prediction remains a key challenge in spatio-temporal data mining, despite progress in deep learning. Accurate forecasting is hindered by the complex influence of external factors such as traffic accidents and regulations, often overlooked by existing models due to limited data integration. To address these limitations, we present two enriched traffic datasets from Tokyo and California, incorporating traffic accident and regulation data. Leveraging these datasets, we propose ConFormer (Conditional Transformer), a novel framework that integrates graph propagation with guided normalization layer. This design dynamically adjusts spatial and temporal node relationships based on historical patterns, enhancing predictive accuracy. Our model surpasses the state-of-the-art STAEFormer in both predictive performance and efficiency, achieving lower computational costs and reduced parameter demands. Extensive evaluations demonstrate that ConFormer consistently outperforms mainstream spatio-temporal baselines across multiple metrics, underscoring its potential to advance traffic prediction research.
How Different from the Past? Spatio-Temporal Time Series Forecasting with Self-Supervised Deviation Learning
Oct 06, 2025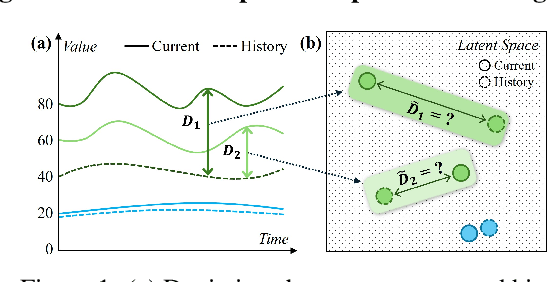
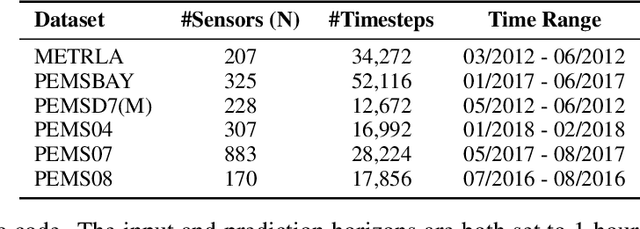
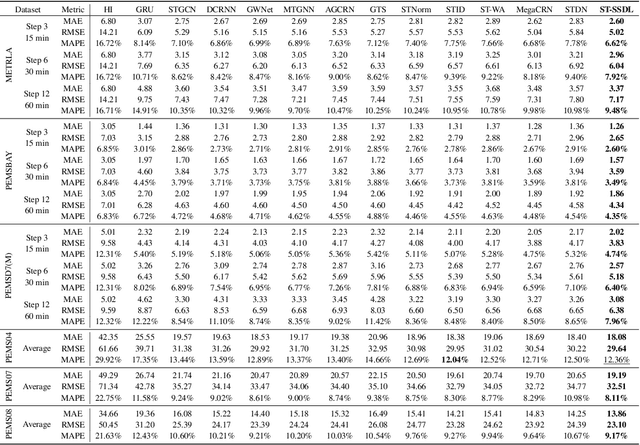
Spatio-temporal forecasting is essential for real-world applications such as traffic management and urban computing. Although recent methods have shown improved accuracy, they often fail to account for dynamic deviations between current inputs and historical patterns. These deviations contain critical signals that can significantly affect model performance. To fill this gap, we propose ST-SSDL, a Spatio-Temporal time series forecasting framework that incorporates a Self-Supervised Deviation Learning scheme to capture and utilize such deviations. ST-SSDL anchors each input to its historical average and discretizes the latent space using learnable prototypes that represent typical spatio-temporal patterns. Two auxiliary objectives are proposed to refine this structure: a contrastive loss that enhances inter-prototype discriminability and a deviation loss that regularizes the distance consistency between input representations and corresponding prototypes to quantify deviation. Optimized jointly with the forecasting objective, these components guide the model to organize its hidden space and improve generalization across diverse input conditions. Experiments on six benchmark datasets show that ST-SSDL consistently outperforms state-of-the-art baselines across multiple metrics. Visualizations further demonstrate its ability to adaptively respond to varying levels of deviation in complex spatio-temporal scenarios. Our code and datasets are available at https://github.com/Jimmy-7664/ST-SSDL.
Graph Community Augmentation with GMM-based Modeling in Latent Space
Dec 02, 2024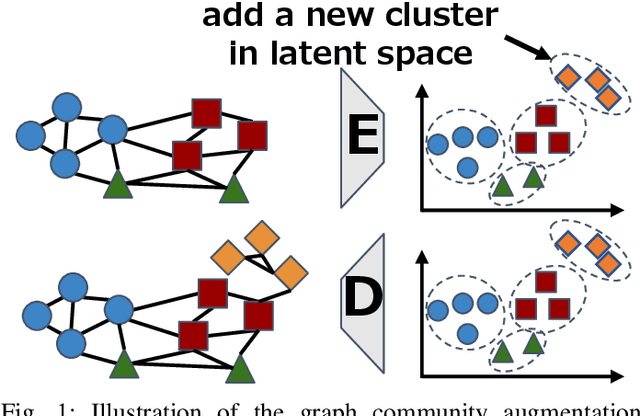
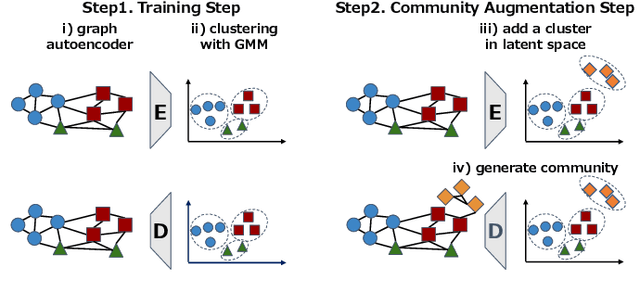
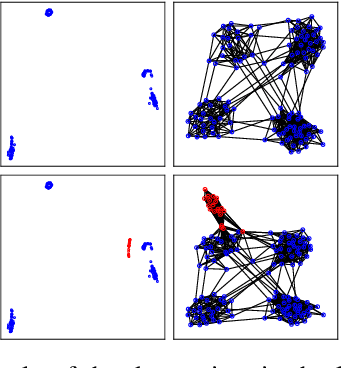
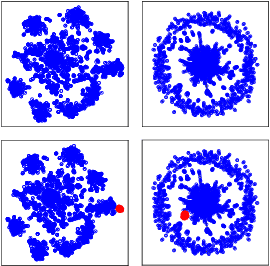
This study addresses the issue of graph generation with generative models. In particular, we are concerned with graph community augmentation problem, which refers to the problem of generating unseen or unfamiliar graphs with a new community out of the probability distribution estimated with a given graph dataset. The graph community augmentation means that the generated graphs have a new community. There is a chance of discovering an unseen but important structure of graphs with a new community, for example, in a social network such as a purchaser network. Graph community augmentation may also be helpful for generalization of data mining models in a case where it is difficult to collect real graph data enough. In fact, there are many ways to generate a new community in an existing graph. It is desirable to discover a new graph with a new community beyond the given graph while we keep the structure of the original graphs to some extent for the generated graphs to be realistic. To this end, we propose an algorithm called the graph community augmentation (GCA). The key ideas of GCA are (i) to fit Gaussian mixture model (GMM) to data points in the latent space into which the nodes in the original graph are embedded, and (ii) to add data points in the new cluster in the latent space for generating a new community based on the minimum description length (MDL) principle. We empirically demonstrate the effectiveness of GCA for generating graphs with a new community structure on synthetic and real datasets.
Multimodal Point-of-Interest Recommendation
Oct 07, 2024



Large Language Models are applied to recommendation tasks such as items to buy and news articles to read. Point of Interest is quite a new area to sequential recommendation based on language representations of multimodal datasets. As a first step to prove our concepts, we focused on restaurant recommendation based on each user's past visit history. When choosing a next restaurant to visit, a user would consider genre and location of the venue and, if available, pictures of dishes served there. We created a pseudo restaurant check-in history dataset from the Foursquare dataset and the FoodX-251 dataset by converting pictures into text descriptions with a multimodal model called LLaVA, and used a language-based sequential recommendation framework named Recformer proposed in 2023. A model trained on this semi-multimodal dataset has outperformed another model trained on the same dataset without picture descriptions. This suggests that this semi-multimodal model reflects actual human behaviours and that our path to a multimodal recommendation model is in the right direction.
Balancing Summarization and Change Detection in Graph Streams
Nov 30, 2023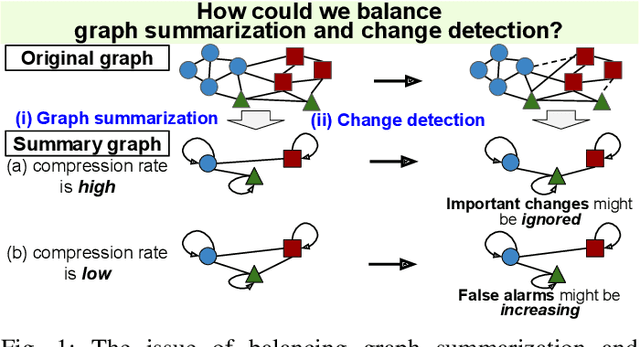
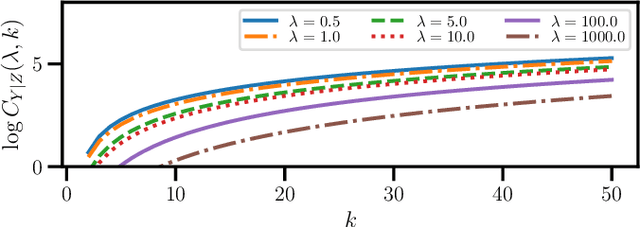
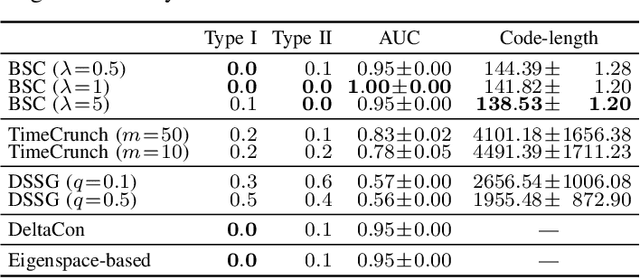

This study addresses the issue of balancing graph summarization and graph change detection. Graph summarization compresses large-scale graphs into a smaller scale. However, the question remains: To what extent should the original graph be compressed? This problem is solved from the perspective of graph change detection, aiming to detect statistically significant changes using a stream of summary graphs. If the compression rate is extremely high, important changes can be ignored, whereas if the compression rate is extremely low, false alarms may increase with more memory. This implies that there is a trade-off between compression rate in graph summarization and accuracy in change detection. We propose a novel quantitative methodology to balance this trade-off to simultaneously realize reliable graph summarization and change detection. We introduce a probabilistic structure of hierarchical latent variable model into a graph, thereby designing a parameterized summary graph on the basis of the minimum description length principle. The parameter specifying the summary graph is then optimized so that the accuracy of change detection is guaranteed to suppress Type I error probability (probability of raising false alarms) to be less than a given confidence level. First, we provide a theoretical framework for connecting graph summarization with change detection. Then, we empirically demonstrate its effectiveness on synthetic and real datasets.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.
MegaCRN: Meta-Graph Convolutional Recurrent Network for Spatio-Temporal Modeling
Dec 12, 2022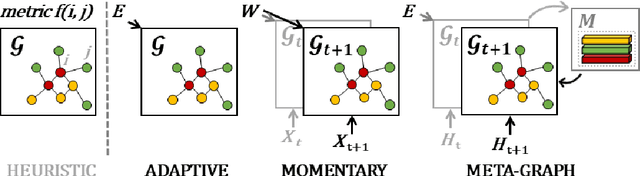

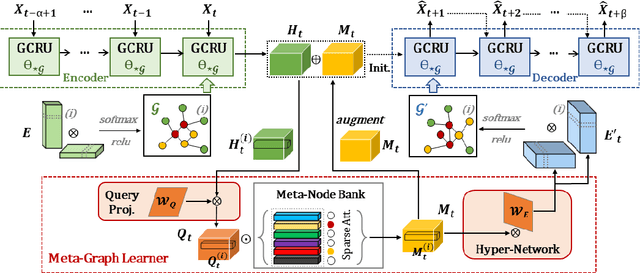
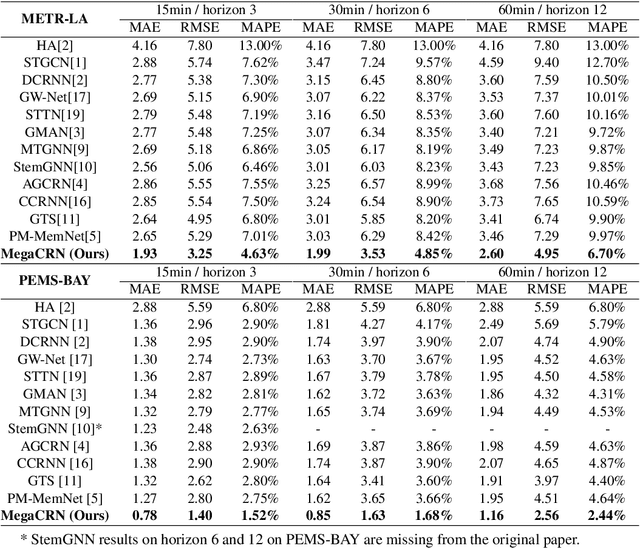
Spatio-temporal modeling as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the underlying heterogeneity and non-stationarity implied in the graph streams, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a large-scale spatio-temporal dataset that contains a variaty of non-stationary phenomena. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle locations and time slots with different patterns and be robustly adaptive to different anomalous situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Dec 08, 2022



Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.