 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature discriminativity estimation in CNNs for transfer learning
Nov 08, 2019
The purpose of feature extraction on convolutional neural networks is to reuse deep representations learnt for a pre-trained model to solve a new, potentially unrelated problem. However, raw feature extraction from all layers is unfeasible given the massive size of these networks. Recently, a supervised method using complexity reduction was proposed, resulting in significant improvements in performance for transfer learning tasks. This approach first computes the discriminative power of features, and then discretises them using thresholds computed for the task. In this paper, we analyse the behaviour of these thresholds, with the purpose of finding a methodology for their estimation. After a comprehensive study, we find a very strong correlation between problem size and threshold value, with coefficient of determination above 90%. These results allow us to propose a unified model for threshold estimation, with potential application to transfer learning tasks.
* Presented in the 22nd International Conference of the Catalan Association for Artificial Intelligence (CCIA 19)
A Visual Distance for WordNet
Apr 27, 2018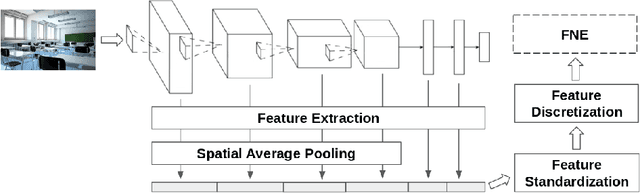
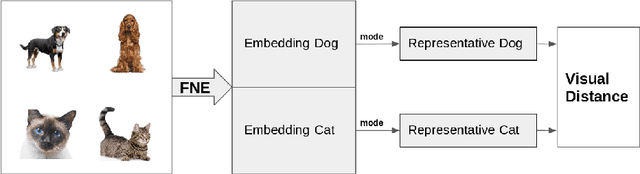
Measuring the distance between concepts is an important field of study of Natural Language Processing, as it can be used to improve tasks related to the interpretation of those same concepts. WordNet, which includes a wide variety of concepts associated with words (i.e., synsets), is often used as a source for computing those distances. In this paper, we explore a distance for WordNet synsets based on visual features, instead of lexical ones. For this purpose, we extract the graphic features generated within a deep convolutional neural networks trained with ImageNet and use those features to generate a representative of each synset. Based on those representatives, we define a distance measure of synsets, which complements the traditional lexical distances. Finally, we propose some experiments to evaluate its performance and compare it with the current state-of-the-art.
Building Graph Representations of Deep Vector Embeddings
Aug 09, 2017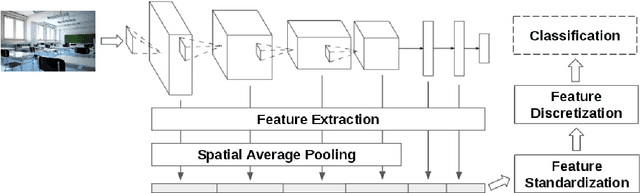
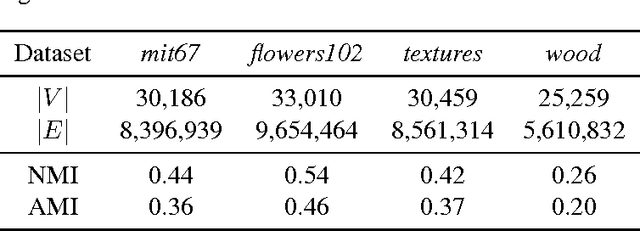
Patterns stored within pre-trained deep neural networks compose large and powerful descriptive languages that can be used for many different purposes. Typically, deep network representations are implemented within vector embedding spaces, which enables the use of traditional machine learning algorithms on top of them. In this short paper we propose the construction of a graph embedding space instead, introducing a methodology to transform the knowledge coded within a deep convolutional network into a topological space (i.e. a network). We outline how such graph can hold data instances, data features, relations between instances and features, and relations among features. Finally, we introduce some preliminary experiments to illustrate how the resultant graph embedding space can be exploited through graph analytics algorithms.
Full-Network Embedding in a Multimodal Embedding Pipeline
Aug 09, 2017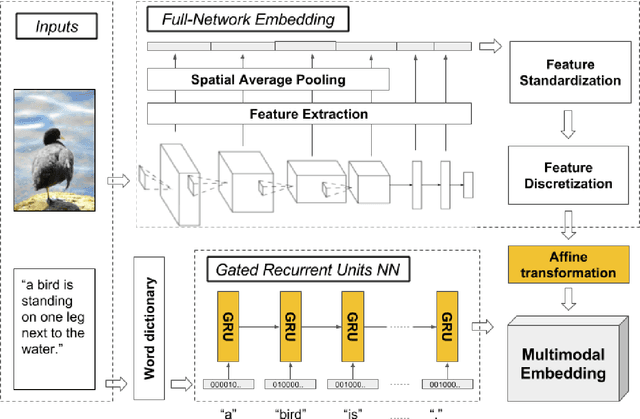
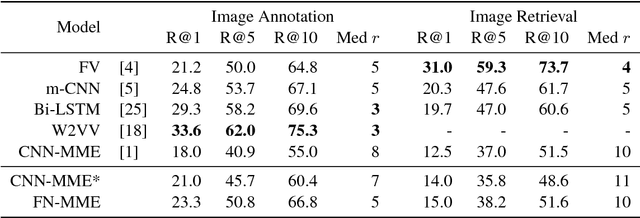
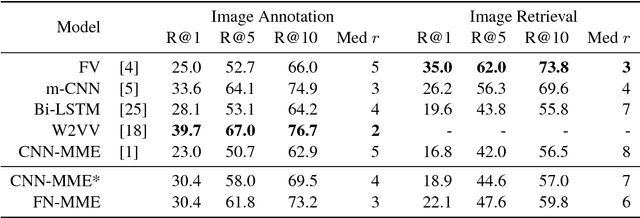
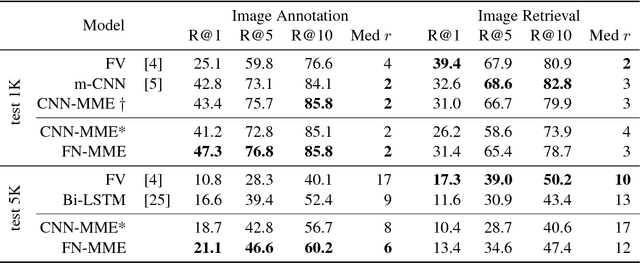
The current state-of-the-art for image annotation and image retrieval tasks is obtained through deep neural networks, which combine an image representation and a text representation into a shared embedding space. In this paper we evaluate the impact of using the Full-Network embedding in this setting, replacing the original image representation in a competitive multimodal embedding generation scheme. Unlike the one-layer image embeddings typically used by most approaches, the Full-Network embedding provides a multi-scale representation of images, which results in richer characterizations. To measure the influence of the Full-Network embedding, we evaluate its performance on three different datasets, and compare the results with the original multimodal embedding generation scheme when using a one-layer image embedding, and with the rest of the state-of-the-art. Results for image annotation and image retrieval tasks indicate that the Full-Network embedding is consistently superior to the one-layer embedding. These results motivate the integration of the Full-Network embedding on any multimodal embedding generation scheme, something feasible thanks to the flexibility of the approach.
An Out-of-the-box Full-network Embedding for Convolutional Neural Networks
May 22, 2017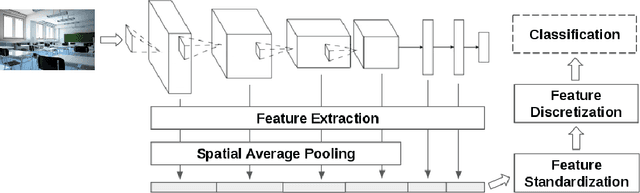
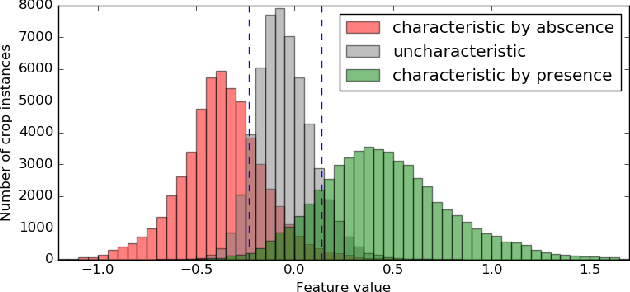
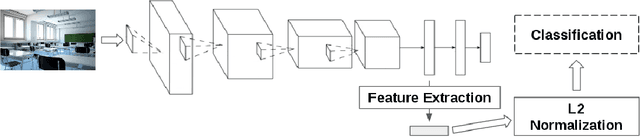
Transfer learning for feature extraction can be used to exploit deep representations in contexts where there is very few training data, where there are limited computational resources, or when tuning the hyper-parameters needed for training is not an option. While previous contributions to feature extraction propose embeddings based on a single layer of the network, in this paper we propose a full-network embedding which successfully integrates convolutional and fully connected features, coming from all layers of a deep convolutional neural network. To do so, the embedding normalizes features in the context of the problem, and discretizes their values to reduce noise and regularize the embedding space. Significantly, this also reduces the computational cost of processing the resultant representations. The proposed method is shown to outperform single layer embeddings on several image classification tasks, while also being more robust to the choice of the pre-trained model used for obtaining the initial features. The performance gap in classification accuracy between thoroughly tuned solutions and the full-network embedding is also reduced, which makes of the proposed approach a competitive solution for a large set of applications.