 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Behavior of Convolutional Nets for Feature Extraction
Jan 29, 2018

Deep neural networks are representation learning techniques. During training, a deep net is capable of generating a descriptive language of unprecedented size and detail in machine learning. Extracting the descriptive language coded within a trained CNN model (in the case of image data), and reusing it for other purposes is a field of interest, as it provides access to the visual descriptors previously learnt by the CNN after processing millions of images, without requiring an expensive training phase. Contributions to this field (commonly known as feature representation transfer or transfer learning) have been purely empirical so far, extracting all CNN features from a single layer close to the output and testing their performance by feeding them to a classifier. This approach has provided consistent results, although its relevance is limited to classification tasks. In a completely different approach, in this paper we statistically measure the discriminative power of every single feature found within a deep CNN, when used for characterizing every class of 11 datasets. We seek to provide new insights into the behavior of CNN features, particularly the ones from convolutional layers, as this can be relevant for their application to knowledge representation and reasoning. Our results confirm that low and middle level features may behave differently to high level features, but only under certain conditions. We find that all CNN features can be used for knowledge representation purposes both by their presence or by their absence, doubling the information a single CNN feature may provide. We also study how much noise these features may include, and propose a thresholding approach to discard most of it. All these insights have a direct application to the generation of CNN embedding spaces.
Building Graph Representations of Deep Vector Embeddings
Aug 09, 2017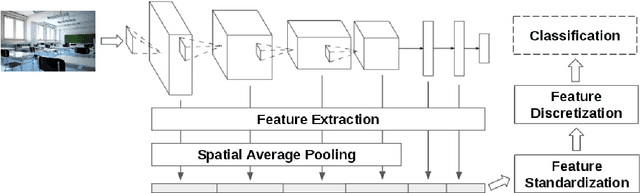
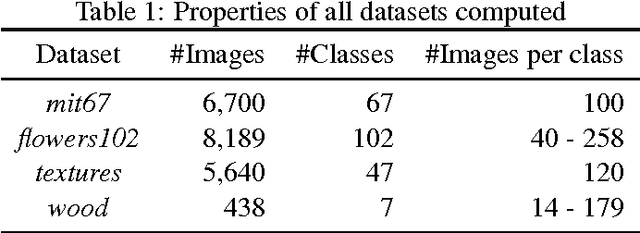
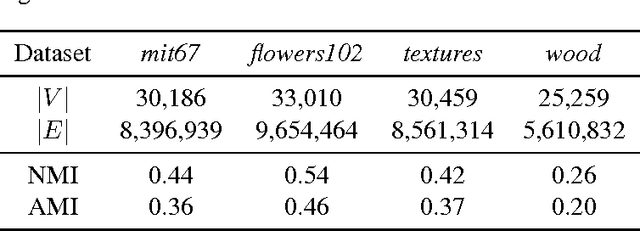
Patterns stored within pre-trained deep neural networks compose large and powerful descriptive languages that can be used for many different purposes. Typically, deep network representations are implemented within vector embedding spaces, which enables the use of traditional machine learning algorithms on top of them. In this short paper we propose the construction of a graph embedding space instead, introducing a methodology to transform the knowledge coded within a deep convolutional network into a topological space (i.e. a network). We outline how such graph can hold data instances, data features, relations between instances and features, and relations among features. Finally, we introduce some preliminary experiments to illustrate how the resultant graph embedding space can be exploited through graph analytics algorithms.
An Out-of-the-box Full-network Embedding for Convolutional Neural Networks
May 22, 2017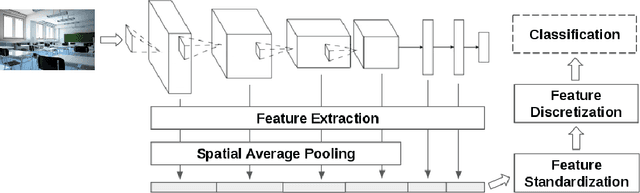
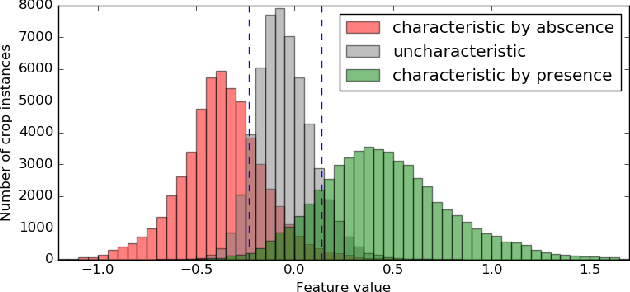
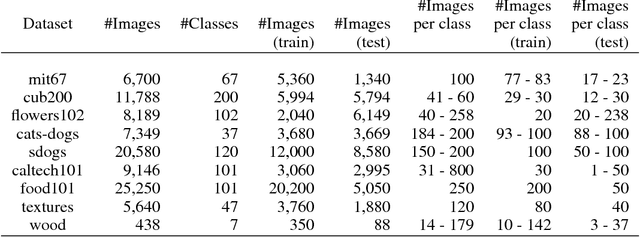
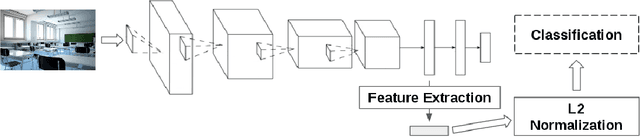
Transfer learning for feature extraction can be used to exploit deep representations in contexts where there is very few training data, where there are limited computational resources, or when tuning the hyper-parameters needed for training is not an option. While previous contributions to feature extraction propose embeddings based on a single layer of the network, in this paper we propose a full-network embedding which successfully integrates convolutional and fully connected features, coming from all layers of a deep convolutional neural network. To do so, the embedding normalizes features in the context of the problem, and discretizes their values to reduce noise and regularize the embedding space. Significantly, this also reduces the computational cost of processing the resultant representations. The proposed method is shown to outperform single layer embeddings on several image classification tasks, while also being more robust to the choice of the pre-trained model used for obtaining the initial features. The performance gap in classification accuracy between thoroughly tuned solutions and the full-network embedding is also reduced, which makes of the proposed approach a competitive solution for a large set of applications.