 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Explains the Explanation? Quantitatively Assessing Feature Attribution Methods
Sep 28, 2021
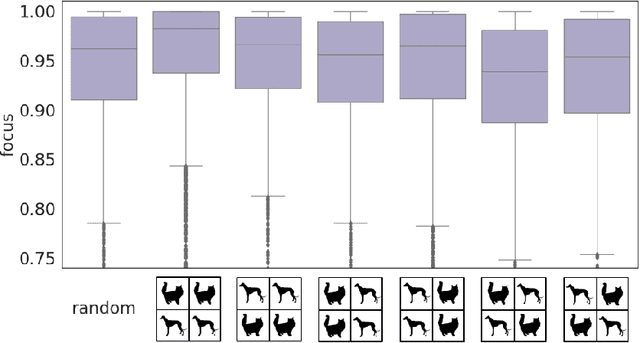
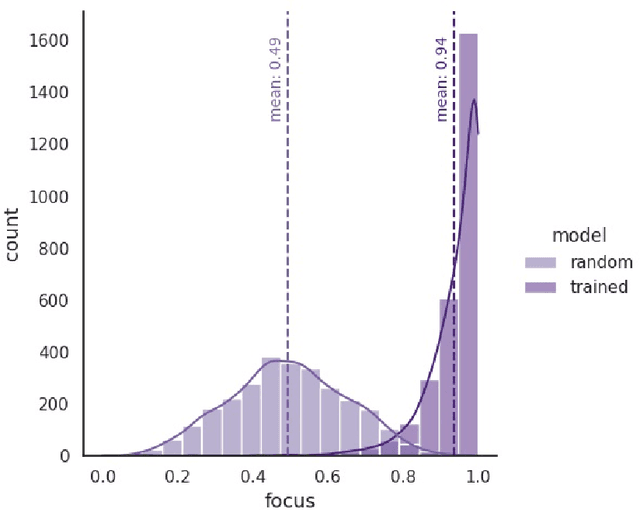
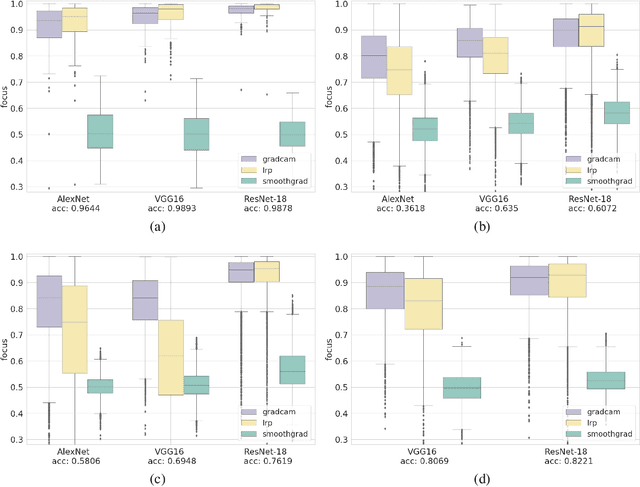
AI explainability seeks to increase the transparency of models, making them more trustworthy in the process. The need for transparency has been recently motivated by the emergence of deep learning models, which are particularly obscure by nature. Even in the domain of images, where deep learning has succeeded the most, explainability is still poorly assessed. Multiple feature attribution methods have been proposed in the literature with the purpose of explaining a DL model's behavior using visual queues, but no standardized metrics to assess or select these methods exist. In this paper we propose a novel evaluation metric -- the Focus -- designed to quantify the faithfulness of explanations provided by feature attribution methods, such as LRP or GradCAM. First, we show the robustness of the metric through randomization experiments, and then use Focus to evaluate and compare three popular explainability techniques using multiple architectures and datasets. Our results find LRP and GradCAM to be consistent and reliable, the former being more accurate for high performing models, while the latter remains most competitive even when applied to poorly performing models. Finally, we identify a strong relation between Focus and factors like model architecture and task, unveiling a new unsupervised approach for the assessment of models.
A Closer Look at Art Mediums: The MAMe Image Classification Dataset
Jul 27, 2020
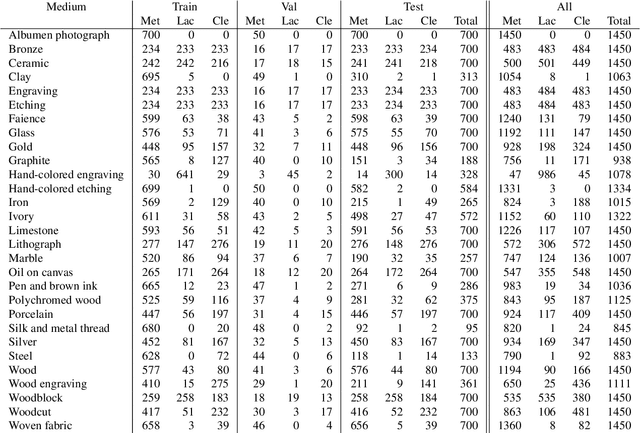
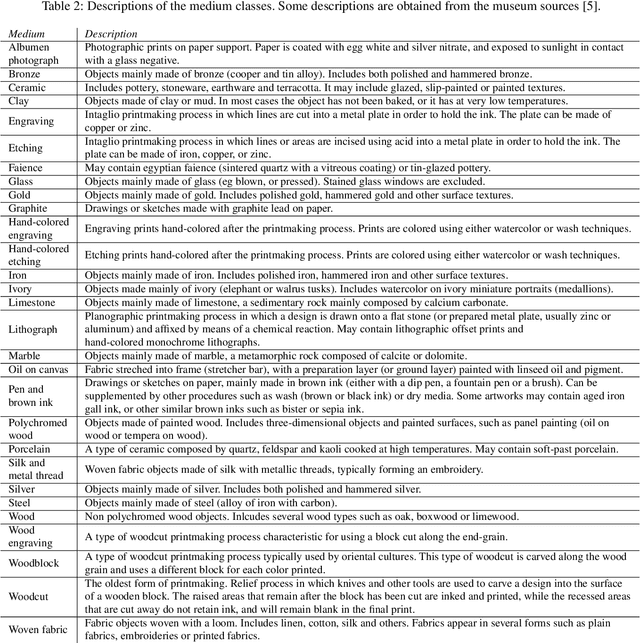
Art is an expression of human creativity, skill and technology. An exceptionally rich source of visual content. In the context of AI image processing systems, artworks represent one of the most challenging domains conceivable: Properly perceiving art requires attention to detail, a huge generalization capacity, and recognizing both simple and complex visual patterns. To challenge the AI community, this work introduces a novel image classification task focused on museum art mediums, the MAMe dataset. Data is gathered from three different museums, and aggregated by art experts into 29 classes of medium (i.e. materials and techniques). For each class, MAMe provides a minimum of 850 images (700 for training) of high-resolution and variable shape. The combination of volume, resolution and shape allows MAMe to fill a void in current image classification challenges, empowering research in aspects so far overseen by the research community. After reviewing the singularity of MAMe in the context of current image classification tasks, a thorough description of the task is provided, together with dataset statistics. Baseline experiments are conducted using well-known architectures, to highlight both the feasibility and complexity of the task proposed. Finally, these baselines are inspected using explainability methods and expert knowledge, to gain insight on the challenges that remain ahead.
MetH: A family of high-resolution and variable-shape image challenges
Nov 29, 2019


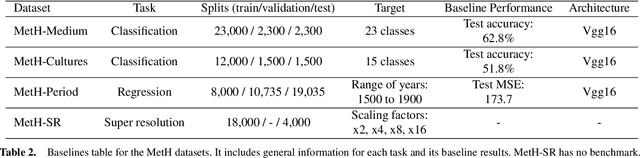
High-resolution and variable-shape images have not yet been properly addressed by the AI community. The approach of down-sampling data often used with convolutional neural networks is sub-optimal for many tasks, and has too many drawbacks to be considered a sustainable alternative. In sight of the increasing importance of problems that can benefit from exploiting high-resolution (HR) and variable-shape, and with the goal of promoting research in that direction, we introduce a new family of datasets (MetH). The four proposed problems include two image classification, one image regression and one super resolution task. Each of these datasets contains thousands of art pieces captured by HR and variable-shape images, labeled by experts at the Metropolitan Museum of Art. We perform an analysis, which shows how the proposed tasks go well beyond current public alternatives in both pixel size and aspect ratio variance. At the same time, the performance obtained by popular architectures on these tasks shows that there is ample room for improvement. To wrap up the relevance of the contribution we review the fields, both in AI and high-performance computing, that could benefit from the proposed challenges.
Random Forest as a Tumour Genetic Marker Extractor
Nov 26, 2019
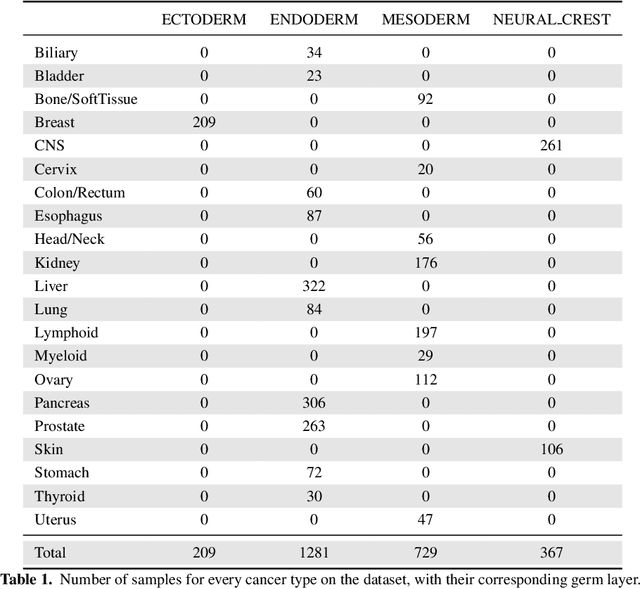
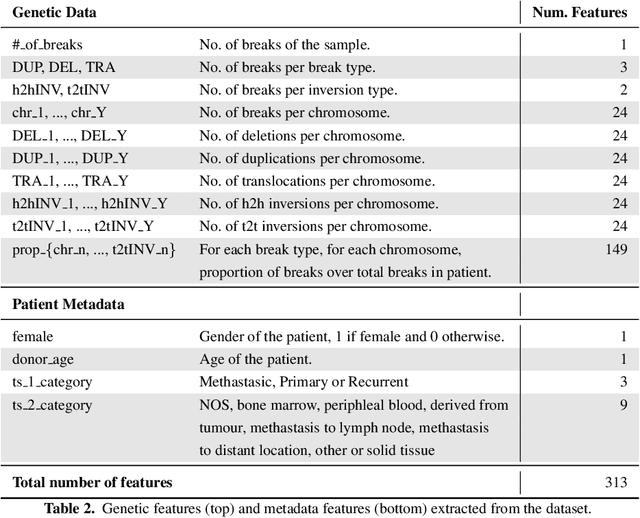

Finding tumour genetic markers is essential to biomedicine due to their relevance for cancer detection and therapy development. In this paper, we explore a recently released dataset of chromosome rearrangements in 2,586 cancer patients, where different sorts of alterations have been detected. Using a Random Forest classifier, we evaluate the relevance of several features (some directly available in the original data, some engineered by us) related to chromosome rearrangements. This evaluation results in a set of potential tumour genetic markers, some of which are validated in the bibliography, while others are potentially novel.
On the Behavior of Convolutional Nets for Feature Extraction
Jan 29, 2018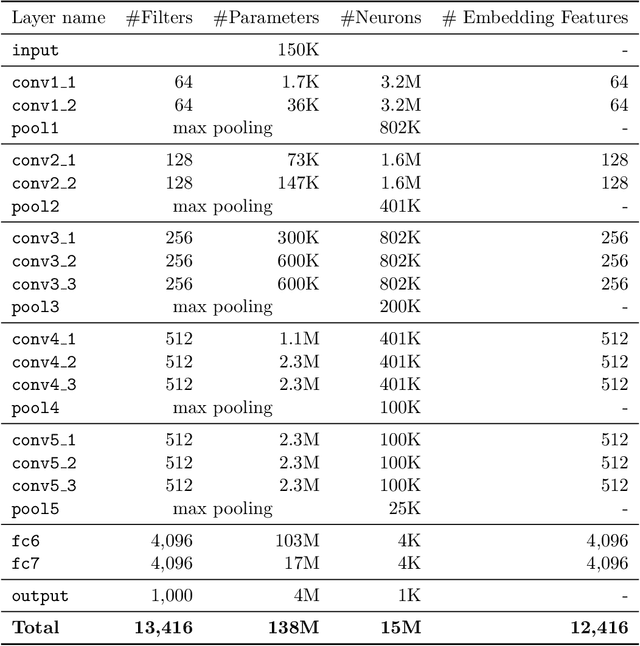
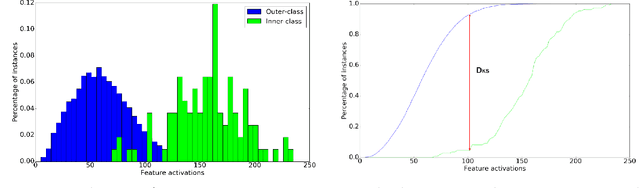
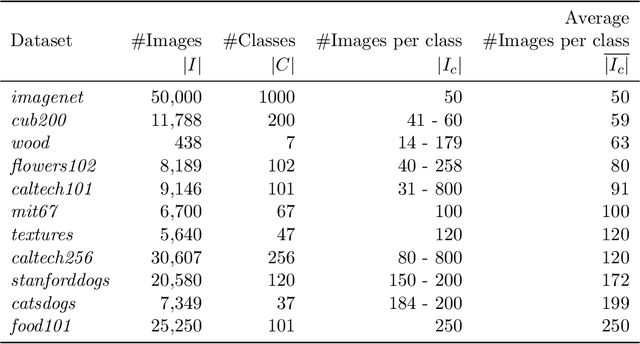

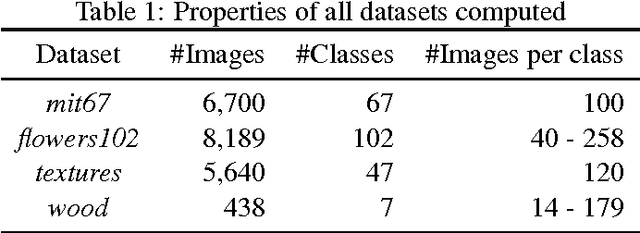
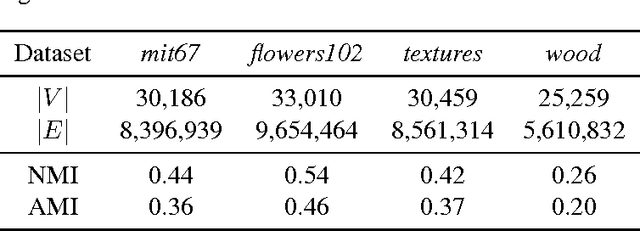
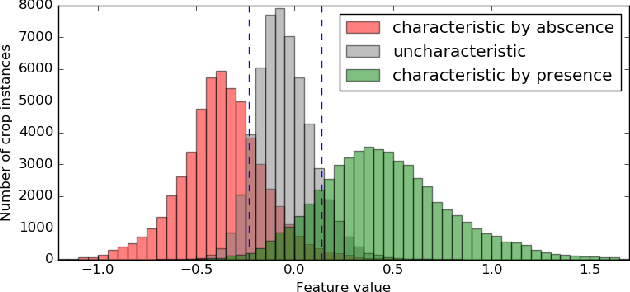
Deep neural networks are representation learning techniques. During training, a deep net is capable of generating a descriptive language of unprecedented size and detail in machine learning. Extracting the descriptive language coded within a trained CNN model (in the case of image data), and reusing it for other purposes is a field of interest, as it provides access to the visual descriptors previously learnt by the CNN after processing millions of images, without requiring an expensive training phase. Contributions to this field (commonly known as feature representation transfer or transfer learning) have been purely empirical so far, extracting all CNN features from a single layer close to the output and testing their performance by feeding them to a classifier. This approach has provided consistent results, although its relevance is limited to classification tasks. In a completely different approach, in this paper we statistically measure the discriminative power of every single feature found within a deep CNN, when used for characterizing every class of 11 datasets. We seek to provide new insights into the behavior of CNN features, particularly the ones from convolutional layers, as this can be relevant for their application to knowledge representation and reasoning. Our results confirm that low and middle level features may behave differently to high level features, but only under certain conditions. We find that all CNN features can be used for knowledge representation purposes both by their presence or by their absence, doubling the information a single CNN feature may provide. We also study how much noise these features may include, and propose a thresholding approach to discard most of it. All these insights have a direct application to the generation of CNN embedding spaces.
Building Graph Representations of Deep Vector Embeddings
Aug 09, 2017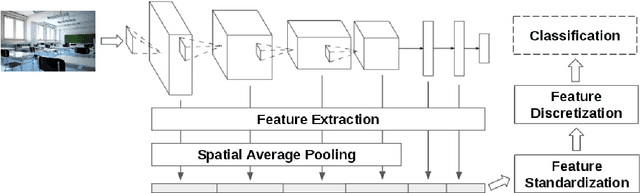
Patterns stored within pre-trained deep neural networks compose large and powerful descriptive languages that can be used for many different purposes. Typically, deep network representations are implemented within vector embedding spaces, which enables the use of traditional machine learning algorithms on top of them. In this short paper we propose the construction of a graph embedding space instead, introducing a methodology to transform the knowledge coded within a deep convolutional network into a topological space (i.e. a network). We outline how such graph can hold data instances, data features, relations between instances and features, and relations among features. Finally, we introduce some preliminary experiments to illustrate how the resultant graph embedding space can be exploited through graph analytics algorithms.
Full-Network Embedding in a Multimodal Embedding Pipeline
Aug 09, 2017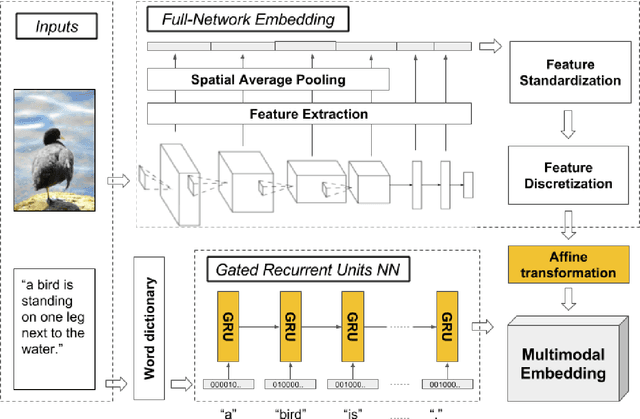
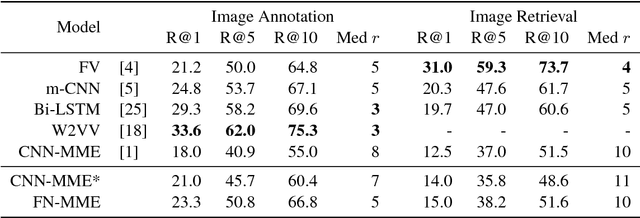
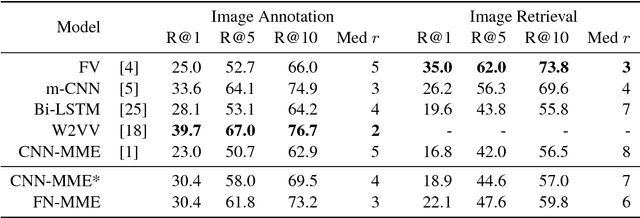
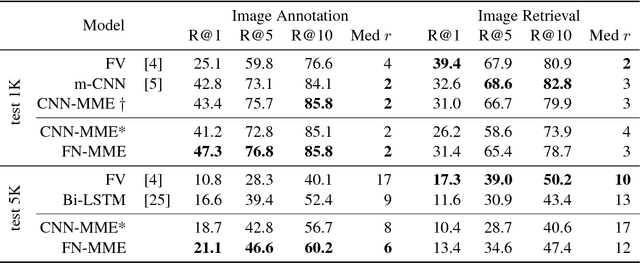
The current state-of-the-art for image annotation and image retrieval tasks is obtained through deep neural networks, which combine an image representation and a text representation into a shared embedding space. In this paper we evaluate the impact of using the Full-Network embedding in this setting, replacing the original image representation in a competitive multimodal embedding generation scheme. Unlike the one-layer image embeddings typically used by most approaches, the Full-Network embedding provides a multi-scale representation of images, which results in richer characterizations. To measure the influence of the Full-Network embedding, we evaluate its performance on three different datasets, and compare the results with the original multimodal embedding generation scheme when using a one-layer image embedding, and with the rest of the state-of-the-art. Results for image annotation and image retrieval tasks indicate that the Full-Network embedding is consistently superior to the one-layer embedding. These results motivate the integration of the Full-Network embedding on any multimodal embedding generation scheme, something feasible thanks to the flexibility of the approach.
An Out-of-the-box Full-network Embedding for Convolutional Neural Networks
May 22, 2017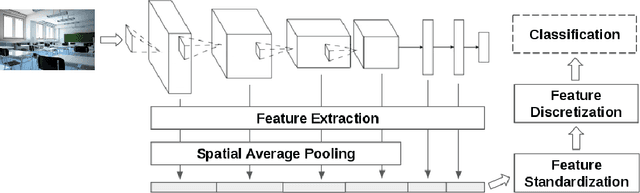
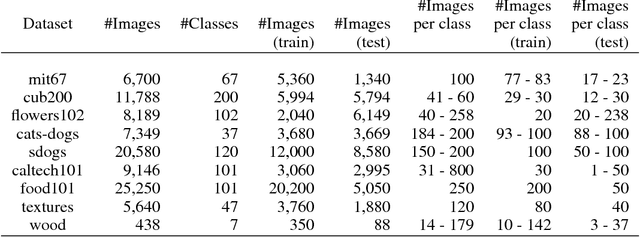
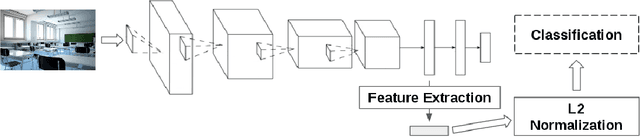
Transfer learning for feature extraction can be used to exploit deep representations in contexts where there is very few training data, where there are limited computational resources, or when tuning the hyper-parameters needed for training is not an option. While previous contributions to feature extraction propose embeddings based on a single layer of the network, in this paper we propose a full-network embedding which successfully integrates convolutional and fully connected features, coming from all layers of a deep convolutional neural network. To do so, the embedding normalizes features in the context of the problem, and discretizes their values to reduce noise and regularize the embedding space. Significantly, this also reduces the computational cost of processing the resultant representations. The proposed method is shown to outperform single layer embeddings on several image classification tasks, while also being more robust to the choice of the pre-trained model used for obtaining the initial features. The performance gap in classification accuracy between thoroughly tuned solutions and the full-network embedding is also reduced, which makes of the proposed approach a competitive solution for a large set of applications.