 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotSoTiny: A Large, Living Benchmark for RTL Code Generation
Dec 23, 2025LLMs have shown early promise in generating RTL code, yet evaluating their capabilities in realistic setups remains a challenge. So far, RTL benchmarks have been limited in scale, skewed toward trivial designs, offering minimal verification rigor, and remaining vulnerable to data contamination. To overcome these limitations and to push the field forward, this paper introduces NotSoTiny, a benchmark that assesses LLM on the generation of structurally rich and context-aware RTL. Built from hundreds of actual hardware designs produced by the Tiny Tapeout community, our automated pipeline removes duplicates, verifies correctness and periodically incorporates new designs to mitigate contamination, matching Tiny Tapeout release schedule. Evaluation results show that NotSoTiny tasks are more challenging than prior benchmarks, emphasizing its effectiveness in overcoming current limitations of LLMs applied to hardware design, and in guiding the improvement of such promising technology.
TuRTLe: A Unified Evaluation of LLMs for RTL Generation
Mar 31, 2025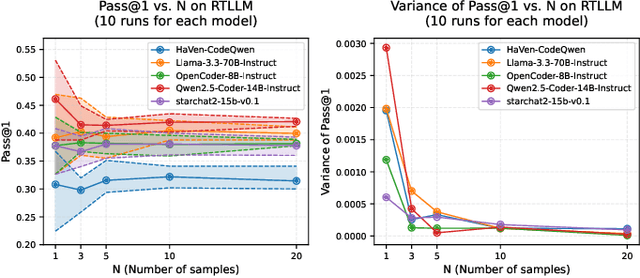
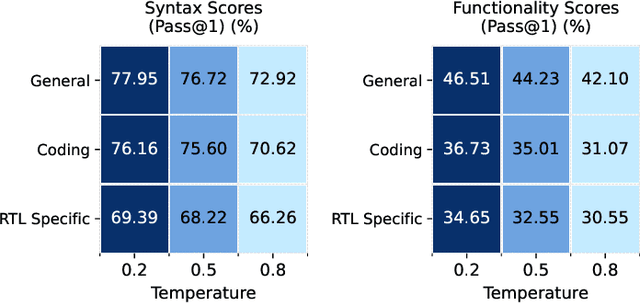
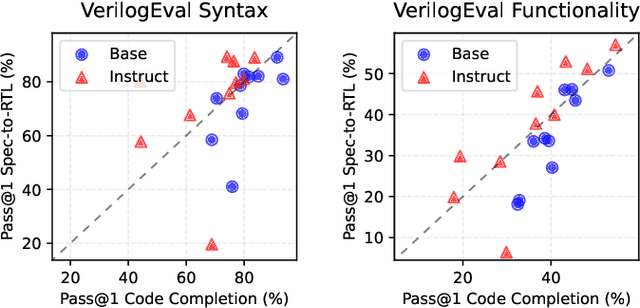
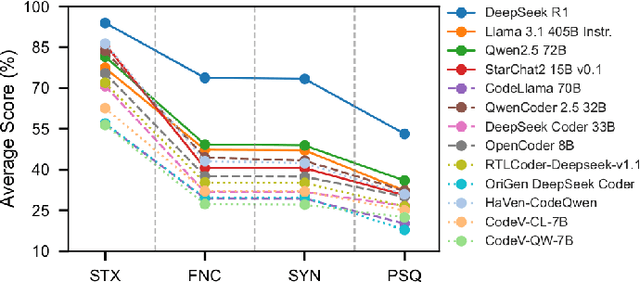
The rapid advancements in LLMs have driven the adoption of generative AI in various domains, including Electronic Design Automation (EDA). Unlike traditional software development, EDA presents unique challenges, as generated RTL code must not only be syntactically correct and functionally accurate but also synthesizable by hardware generators while meeting performance, power, and area constraints. These additional requirements introduce complexities that existing code-generation benchmarks often fail to capture, limiting their effectiveness in evaluating LLMs for RTL generation. To address this gap, we propose TuRTLe, a unified evaluation framework designed to systematically assess LLMs across key RTL generation tasks. TuRTLe integrates multiple existing benchmarks and automates the evaluation process, enabling a comprehensive assessment of LLM performance in syntax correctness, functional correctness, synthesis, PPA optimization, and exact line completion. Using this framework, we benchmark a diverse set of open LLMs and analyze their strengths and weaknesses in EDA-specific tasks. Our results show that reasoning-based models, such as DeepSeek R1, consistently outperform others across multiple evaluation criteria, but at the cost of increased computational overhead and inference latency. Additionally, base models are better suited in module completion tasks, while instruct-tuned models perform better in specification-to-RTL tasks.
TinyEmo: Scaling down Emotional Reasoning via Metric Projection
Oct 09, 2024This paper introduces TinyEmo, a family of small multi-modal language models for emotional reasoning and classification. Our approach features: (1) a synthetic emotional instruct dataset for both pre-training and fine-tuning stages, (2) a Metric Projector that delegates classification from the language model allowing for more efficient training and inference, (3) a multi-modal large language model (MM-LLM) for emotional reasoning, and (4) a semi-automated framework for bias detection. TinyEmo is able to perform emotion classification and emotional reasoning, all while using substantially fewer parameters than comparable models. This efficiency allows us to freely incorporate more diverse emotional datasets, enabling strong performance on classification tasks, with our smallest model (700M parameters) outperforming larger state-of-the-art models based on general-purpose MM-LLMs with over 7B parameters. Additionally, the Metric Projector allows for interpretability and indirect bias detection in large models without additional training, offering an approach to understand and improve AI systems. We release code, models, and dataset at https://github.com/ggcr/TinyEmo