 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactBench: A Cause-Driven Benchmark for Multimodal Hallucination via Systematic Evaluation
May 28, 2026While multimodal large language models (MLLMs) have achieved rapid progress in vision-language understanding, they remain prone to multimodal hallucinations, producing responses that are inconsistent with the visual input. Existing benchmarks predominantly focus on detecting hallucination outcomes rather than evaluating the underlying causes of these failures. Moreover, many benchmarks rely on simplistic scenarios and limited evaluation formats that no longer challenge state-of-the-art models. To address these limitations, we introduce ReactBench, a cause-driven hallucination benchmark featuring multiple tasks and an exam-style evaluation format. By generating adversarial images and hallucination-inducing queries, ReactBench introduces four targeted tasks: Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. These tasks systematically expose co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. Beyond standard accuracy-based evaluation, we leverage Chain-of-Thought reasoning to identify fine-grained sub-causes of hallucination within each task. Extensive evaluations reveal that current MLLMs remain notably vulnerable to cause-specific hallucination triggers, demonstrating the value of ReactBench as a systematic and interpretable testbed for diagnosing and improving multimodal model robustness. The project page is available at https://reactbench.github.io/.
CLORE: Content-Level Optimization for Reasoning Efficiency
May 21, 2026Reinforcement learning post-training has improved the reasoning ability of large language models, but often produces unnecessarily long, repetitive, or semantically opaque reasoning traces. Existing efficient reasoning methods mainly regulate response length through explicit budgets or length-aware rewards, leaving intermediate reasoning content weakly supervised. We propose CLORE, a content-level optimization framework that improves reasoning efficiency by editing correct on-policy rollouts. CLORE uses an external augmentation model to delete repetitive segments, illegible or task-irrelevant content, and superfluous reasoning after the solution is established, while preserving the final answer. The resulting augmented--original pairs are optimized with an auxiliary reference-free DPO objective alongside standard policy-gradient training. By restricting augmentation to correct trajectories and performing local deletion, CLORE keeps edited rollouts close to the policy distribution and mitigates off-policy mismatch. Experiments on DeepSeek-R1-Distill-Qwen-7B and Qwen2.5-Math-7B across five mathematical reasoning benchmarks show that CLORE improves the accuracy--efficiency trade-off and remains compatible with GRPO, DAPO, Training Efficient, and ThinkPrune. Content-level analyses further show that CLORE reduces repetitive reasoning, illegible content, and post-answer exploration, supporting content-level supervision as a complementary direction to length-level control.
CrystalReasoner: Reasoning and RL for Property-Conditioned Crystal Structure Generation
May 14, 2026Generative modeling has emerged as a promising approach for crystal structure discovery. However, existing LLM-based generative models struggle with low-level atomic precision, while diffusion-based methods fall short in integrating high-level scientific knowledge. As a result, generated structures are often invalid, unstable, or do not possess desirable properties. To address this gap, we propose CrystalReasoner (\method), an end-to-end LLM framework that generates crystal structures from natural language instructions through reasoning and alignment. \method introduces physical priors as thinking tokens, which include crystallographic symmetry, local coordination environments and predicted physical properties before generating atomic coordinates. This bridges the gap between natural language and 3D structures. \method then employs reinforcement learning (RL) with a multi-objective, dense reward function to align generation with physical validity, chemical consistency, and thermodynamic stability. For property-conditioned tasks, we design task-specific reward functions and train specialized models for discrete constraints (e.g., space group) and continuous properties (e.g., elasticity, thermal expansion). Empirical results demonstrate that compared to prior works and baselines without thinking traces or RL, \method obtains better performance on diverse metrics, triples S.U.N. ratio, and achieves better performance for property conditioned generation. \method also exhibits adaptive reasoning, increasing reasoning lengths as the number of atoms increases. Our work demonstrates the potential of leveraging thinking traces and RL for generating valid, stable, and property-conditioned crystal structures. Please see our work at https://crystalreasoner.github.io/ .
VeriLLMed: Interactive Visual Debugging of Medical Large Language Models with Knowledge Graphs
Apr 25, 2026Large language models (LLMs) show promise in medical diagnosis, but real-world deployment remains challenging due to high-stakes clinical decisions and imperfect reasoning reliability. As a result, careful inspection of model behavior is essential for assessing whether diagnostic reasoning is reliable and clinically grounded. However, debugging medical LLMs remains difficult. First, developers often lack sufficient medical domain expertise to interpret model errors in clinically meaningful terms. Second, models can fail across a large and diverse set of instances involving different input types, tasks, and reasoning steps, making it challenging for developers to prioritize which errors deserve focused inspection. Third, developers struggle to identify recurring error patterns across cases, as existing debugging practices are largely instance-centric and rely on manual inspection of isolated failures. To address these challenges, we present VeriLLMed, a visual analytics system that integrates external biomedical knowledge to audit and debug medical LLM diagnostic reasoning. VeriLLMed transforms model outputs into comparable reasoning paths, constructs knowledge graph-grounded reference paths, and identifies three recurring classes of diagnosis errors: relation errors, branch errors, and missing errors. Case studies and expert evaluation demonstrate that VeriLLMed helps developers identify clinically implausible reasoning and generate actionable insights that can inform the improvement of medical LLMs.
Bridging Visual Representation and Reinforcement Learning from Verifiable Rewards in Large Vision-Language Models
Mar 28, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has substantially enhanced the reasoning capabilities of large language models in abstract reasoning tasks. However, its application to Large Vision-Language Models (LVLMs) remains constrained by a structural representational bottleneck. Existing approaches generally lack explicit modeling and effective utilization of visual information, preventing visual representations from being tightly coupled with the reinforcement learning optimization process and thereby limiting further improvements in multimodal reasoning performance. To address this limitation, we propose KAWHI (Key-Region Aligned Weighted Harmonic Incentive), a plug-and-play reward reweighting mechanism that explicitly incorporates structured visual information into uniform reward policy optimization methods (e.g., GRPO and GSPO). The method adaptively localizes semantically salient regions through hierarchical geometric aggregation, identifies vision-critical attention heads via structured attribution, and performs paragraph-level credit reallocation to align spatial visual evidence with semantically decisive reasoning steps. Extensive empirical evaluations on diverse reasoning benchmarks substantiate KAWHI as a general-purpose enhancement module, consistently improving the performance of various uniform reward optimization methods. Project page: KAWHI (https://kawhiiiileo.github.io/KAWHI_PAGE/)
OpenMic: A Multi-Agent-Based Stand-Up Comedy Generation System
Jan 13, 2026Chinese stand-up comedy generation goes beyond plain text generation, requiring culturally grounded humor, precise timing, stage-performance cues, and implicit multi-step reasoning. Moreover, commonly used Chinese humor datasets are often better suited for humor understanding and evaluation than for long-form stand-up generation, making direct supervision misaligned with the target task. To address these challenges, we present OpenMic, an end-to-end multi-agent system built on AutoGen that transforms a user-provided life topic into a 3-5 minute Chinese stand-up performance and further produces a narrated comedy video. OpenMic orchestrates multiple specialized agents in a multi-round iterative loop-planning to jointly optimize humor, timing, and performability. To mitigate the dataset-task mismatch, we augment generation with retrieval-augmented generation (RAG) for material grounding and idea expansion, and we fine-tune a dedicated JokeWriter to better internalize stand-up-specific setup-punchline structures and long-range callbacks.
When More is Less: Understanding Chain-of-Thought Length in LLMs
Feb 11, 2025



Chain-of-thought (CoT) reasoning enhances the multi-step reasoning capabilities of large language models (LLMs) by breaking complex tasks into smaller, manageable sub-tasks. Researchers have been exploring ways to guide models to generate more complex CoT processes to improve the reasoning ability of LLMs, such as long CoT and the test-time scaling law. However, for most models and tasks, does an increase in CoT length consistently lead to improved reasoning accuracy? In this paper, we observe a nuanced relationship: as the number of reasoning steps increases, performance initially improves but eventually decreases. To understand this phenomenon, we provide a piece of evidence that longer reasoning processes are increasingly susceptible to noise. We theoretically prove the existence of an optimal CoT length and derive a scaling law for this optimal length based on model capability and task difficulty. Inspired by our theory, we conduct experiments on both synthetic and real world datasets and propose Length-filtered Vote to alleviate the effects of excessively long or short CoTs. Our findings highlight the critical need to calibrate CoT length to align with model capabilities and task demands, offering a principled framework for optimizing multi-step reasoning in LLMs.
A Theoretical Understanding of Self-Correction through In-context Alignment
May 28, 2024



Going beyond mimicking limited human experiences, recent studies show initial evidence that, like humans, large language models (LLMs) are capable of improving their abilities purely by self-correction, i.e., correcting previous responses through self-examination, in certain circumstances. Nevertheless, little is known about how such capabilities arise. In this work, based on a simplified setup akin to an alignment task, we theoretically analyze self-correction from an in-context learning perspective, showing that when LLMs give relatively accurate self-examinations as rewards, they are capable of refining responses in an in-context way. Notably, going beyond previous theories on over-simplified linear transformers, our theoretical construction underpins the roles of several key designs of realistic transformers for self-correction: softmax attention, multi-head attention, and the MLP block. We validate these findings extensively on synthetic datasets. Inspired by these findings, we also illustrate novel applications of self-correction, such as defending against LLM jailbreaks, where a simple self-correction step does make a large difference. We believe that these findings will inspire further research on understanding, exploiting, and enhancing self-correction for building better foundation models.
End-to-end lossless compression of high precision depth maps guided by pseudo-residual
Jan 10, 2022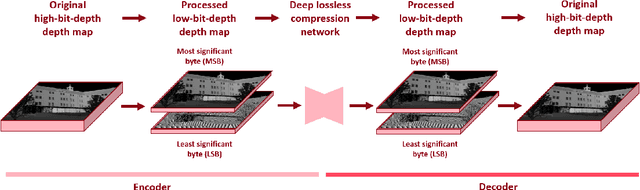
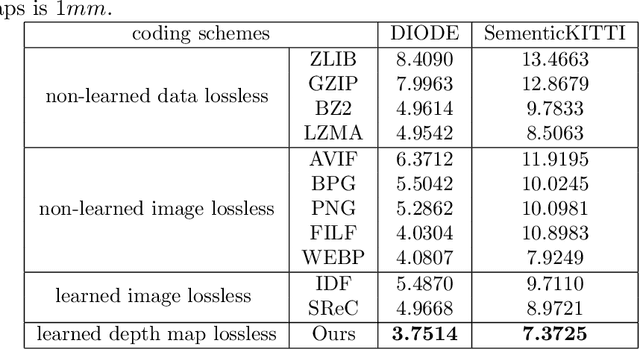

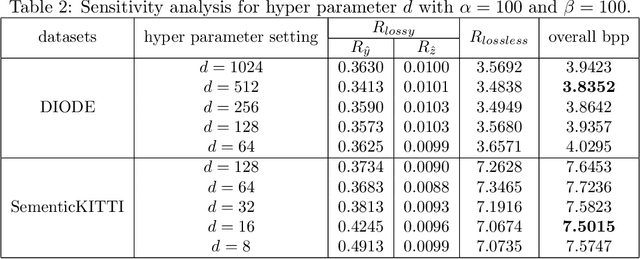
As a fundamental data format representing spatial information, depth map is widely used in signal processing and computer vision fields. Massive amount of high precision depth maps are produced with the rapid development of equipment like laser scanner or LiDAR. Therefore, it is urgent to explore a new compression method with better compression ratio for high precision depth maps. Utilizing the wide spread deep learning environment, we propose an end-to-end learning-based lossless compression method for high precision depth maps. The whole process is comprised of two sub-processes, named pre-processing of depth maps and deep lossless compression of processed depth maps. The deep lossless compression network consists of two sub-networks, named lossy compression network and lossless compression network. We leverage the concept of pseudo-residual to guide the generation of distribution for residual and avoid introducing context models. Our end-to-end lossless compression network achieves competitive performance over engineered codecs and has low computational cost.