 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
Sep 18, 2025Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to high variance and training instability. Existing approaches mitigate this issue using KL penalties or clipping, which passively constrain updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap by keeping correct solutions as on-policy data and rewriting incorrect ones with guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy before optimization, reducing importance sampling variance and stabilizing off-policy fine-tuning. Experiments on five mathematical reasoning benchmarks demonstrate consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. The data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.
MR-EEGWaveNet: Multiresolutional EEGWaveNet for Seizure Detection from Long EEG Recordings
May 23, 2025Feature engineering for generalized seizure detection models remains a significant challenge. Recently proposed models show variable performance depending on the training data and remain ineffective at accurately distinguishing artifacts from seizure data. In this study, we propose a novel end-to-end model, ''Multiresolutional EEGWaveNet (MR-EEGWaveNet),'' which efficiently distinguishes seizure events from background electroencephalogram (EEG) and artifacts/noise by capturing both temporal dependencies across different time frames and spatial relationships between channels. The model has three modules: convolution, feature extraction, and predictor. The convolution module extracts features through depth-wise and spatio-temporal convolution. The feature extraction module individually reduces the feature dimension extracted from EEG segments and their sub-segments. Subsequently, the extracted features are concatenated into a single vector for classification using a fully connected classifier called the predictor module. In addition, an anomaly score-based post-classification processing technique was introduced to reduce the false-positive rates of the model. Experimental results were reported and analyzed using different parameter settings and datasets (Siena (public) and Juntendo (private)). The proposed MR-EEGWaveNet significantly outperformed the conventional non-multiresolution approach, improving the F1 scores from 0.177 to 0.336 on Siena and 0.327 to 0.488 on Juntendo, with precision gains of 15.9% and 20.62%, respectively.
Unimodular Waveform Design for Integrated Sensing and Communication MIMO System via Manifold Optimization
Apr 08, 2025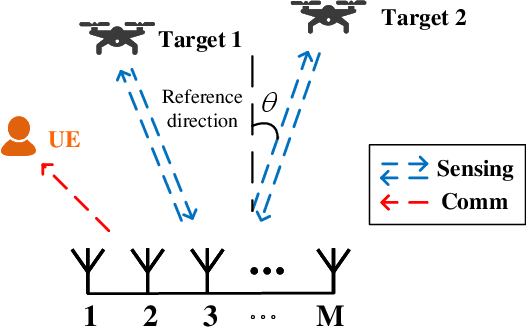
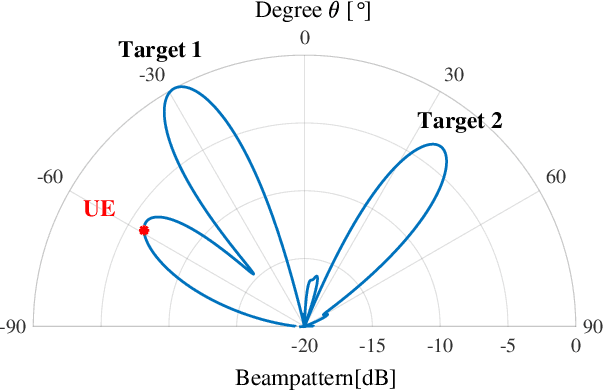
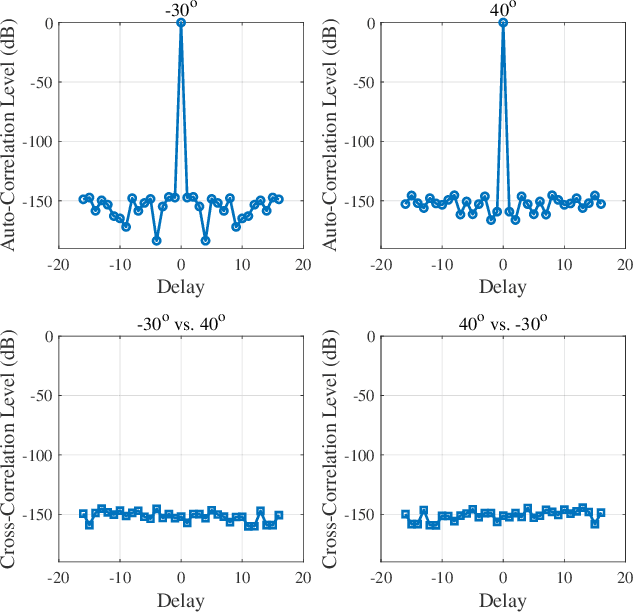
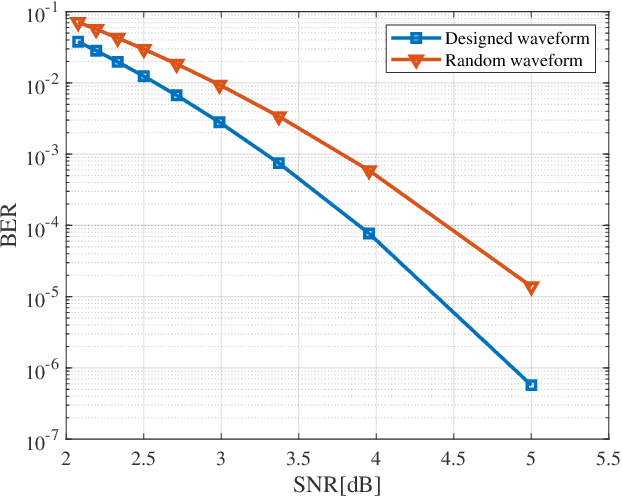
Integrated sensing and communication (ISAC) has been widely recognized as one of the key technologies for 6G wireless networks. In this paper, we focus on the waveform design of ISAC system, which can realize radar sensing while also facilitate information transmission. The main content is as follows: first, we formulate the waveform design problem as a nonconvex and non-smooth model with a unimodulus constraint based on the measurement metric of the radar and communication system. Second, we transform the model into an unconstrained problem on the Riemannian manifold and construct the corresponding operators by analyzing the unimodulus constraint. Third, to achieve the solution efficiently, we propose a low-complexity non-smooth unimodulus manifold gradient descent (N-UMGD) algorithm with theoretical convergence guarantee. The simulation results show that the proposed algorithm can concentrate the energy of the sensing signal in the desired direction and realize information transmission with a low bit error rate.
Scaling Capability in Token Space: An Analysis of Large Vision Language Model
Dec 30, 2024



The scaling capability has been widely validated in neural language models with respect to the number of parameters and the size of training data. One important question is that does the scaling capability also exists similarly with respect to the number of vision tokens in large vision language Model? This study fills the gap by investigating the relationship between the number of vision tokens and the performance on vision-language models. Our theoretical analysis and empirical evaluations demonstrate that the model exhibits scalable performance \(S(N_l)\) with respect to the number of vision tokens \(N_l\), characterized by the relationship \(S(N_l) \approx (c/N_l)^{\alpha}\). Furthermore, we also investigate the impact of a fusion mechanism that integrates the user's question with vision tokens. The results reveal two key findings. First, the scaling capability remains intact with the incorporation of the fusion mechanism. Second, the fusion mechanism enhances model performance, particularly when the user's question is task-specific and relevant. The analysis, conducted on fifteen diverse benchmarks spanning a broad range of tasks and domains, validates the effectiveness of the proposed approach.
Weak Scaling Capability in Token Space: An Observation from Large Vision Language Model
Dec 24, 2024The scaling capability has been widely validated with respect to the number of parameters and the size of training data. One important question that is unexplored is that does scaling capability also exists similarly with respect to the number of vision tokens? This study fills the gap by investigating the relationship between the number of vision tokens and the performance of vision-language models. Our theoretical analysis and empirical evaluations reveal that the model exhibits weak scaling capabilities on the length \(N_l\), with performance approximately \(S(N_l) \approx (c/N_l)^{\alpha}\), where \(c, \alpha\) are hyperparameters. Interestingly, this scaling behavior remains largely unaffected by the inclusion or exclusion of the user's question in the input. Furthermore, fusing the user's question with the vision token can enhance model performance when the question is relevant to the task. To address the computational challenges associated with large-scale vision tokens, we propose a novel architecture that efficiently reduces the token count while integrating user question tokens into the representation. Our findings may offer insights for developing more efficient and effective vision-language models under specific task constraints.
Designing Unimodular Waveforms with Good Correlation Properties for Large-Scale MIMO Radar via Manifold Optimization Method
Oct 10, 2024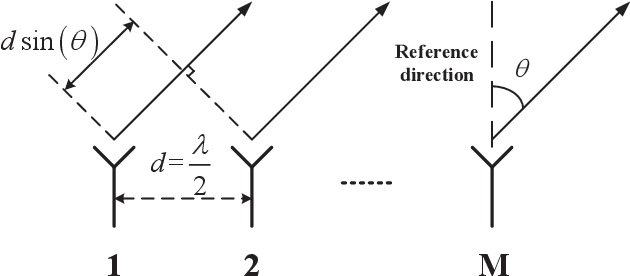
In this paper, we design constant modulus probing waveforms with good correlation properties for large-scale collocated multi-input multi-output (MIMO) radar systems. The main content is as follows: First, we formulate the design problem as a fourth-order polynomial minimization problem with unimodulus constraints. Then, by analyzing the geometric properties of the unimodulus constraints through Riemannian geometry theory and embedding them into the search space, we transform the original non-convex optimization problem into an unconstrained problem on a Riemannian manifold for solution. Second, we convert the objective function into the form of a large but finite number of loss functions and employ a customized R-SVRG algorithm to solve it. Third, we prove that the customized R-SVRG algorithm is theoretically guaranteed to converge if appropriate parameters are chosen. Numerical examples demonstrate the effectiveness of the proposed R-SVRG algorithm.
A Statistical Theory of Regularization-Based Continual Learning
Jun 10, 2024

We provide a statistical analysis of regularization-based continual learning on a sequence of linear regression tasks, with emphasis on how different regularization terms affect the model performance. We first derive the convergence rate for the oracle estimator obtained as if all data were available simultaneously. Next, we consider a family of generalized $\ell_2$-regularization algorithms indexed by matrix-valued hyperparameters, which includes the minimum norm estimator and continual ridge regression as special cases. As more tasks are introduced, we derive an iterative update formula for the estimation error of generalized $\ell_2$-regularized estimators, from which we determine the hyperparameters resulting in the optimal algorithm. Interestingly, the choice of hyperparameters can effectively balance the trade-off between forward and backward knowledge transfer and adjust for data heterogeneity. Moreover, the estimation error of the optimal algorithm is derived explicitly, which is of the same order as that of the oracle estimator. In contrast, our lower bounds for the minimum norm estimator and continual ridge regression show their suboptimality. A byproduct of our theoretical analysis is the equivalence between early stopping and generalized $\ell_2$-regularization in continual learning, which may be of independent interest. Finally, we conduct experiments to complement our theory.
EpilepsyLLM: Domain-Specific Large Language Model Fine-tuned with Epilepsy Medical Knowledge
Jan 11, 2024With large training datasets and massive amounts of computing sources, large language models (LLMs) achieve remarkable performance in comprehensive and generative ability. Based on those powerful LLMs, the model fine-tuned with domain-specific datasets posseses more specialized knowledge and thus is more practical like medical LLMs. However, the existing fine-tuned medical LLMs are limited to general medical knowledge with English language. For disease-specific problems, the model's response is inaccurate and sometimes even completely irrelevant, especially when using a language other than English. In this work, we focus on the particular disease of Epilepsy with Japanese language and introduce a customized LLM termed as EpilepsyLLM. Our model is trained from the pre-trained LLM by fine-tuning technique using datasets from the epilepsy domain. The datasets contain knowledge of basic information about disease, common treatment methods and drugs, and important notes in life and work. The experimental results demonstrate that EpilepsyLLM can provide more reliable and specialized medical knowledge responses.
TDLE: 2-D LiDAR Exploration With Hierarchical Planning Using Regional Division
Jul 06, 2023Exploration systems are critical for enhancing the autonomy of robots. Due to the unpredictability of the future planning space, existing methods either adopt an inefficient greedy strategy or require a lot of resources to obtain a global solution. In this work, we address the challenge of obtaining global exploration routes with minimal computing resources. A hierarchical planning framework dynamically divides the planning space into subregions and arranges their orders to provide global guidance for exploration. Indicators that are compatible with the subregion order are used to choose specific exploration targets, thereby considering estimates of spatial structure and extending the planning space to unknown regions. Extensive simulations and field tests demonstrate the efficacy of our method in comparison to existing 2D LiDAR-based approaches. Our code has been made public for further investigation.
ArCL: Enhancing Contrastive Learning with Augmentation-Robust Representations
Mar 02, 2023



Self-Supervised Learning (SSL) is a paradigm that leverages unlabeled data for model training. Empirical studies show that SSL can achieve promising performance in distribution shift scenarios, where the downstream and training distributions differ. However, the theoretical understanding of its transferability remains limited. In this paper, we develop a theoretical framework to analyze the transferability of self-supervised contrastive learning, by investigating the impact of data augmentation on it. Our results reveal that the downstream performance of contrastive learning depends largely on the choice of data augmentation. Moreover, we show that contrastive learning fails to learn domain-invariant features, which limits its transferability. Based on these theoretical insights, we propose a novel method called Augmentation-robust Contrastive Learning (ArCL), which guarantees to learn domain-invariant features and can be easily integrated with existing contrastive learning algorithms. We conduct experiments on several datasets and show that ArCL significantly improves the transferability of contrastive learning.