 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Detection of Watermarks for Large Language Models Under Human Edits
Nov 21, 2024Watermarking has offered an effective approach to distinguishing text generated by large language models (LLMs) from human-written text. However, the pervasive presence of human edits on LLM-generated text dilutes watermark signals, thereby significantly degrading detection performance of existing methods. In this paper, by modeling human edits through mixture model detection, we introduce a new method in the form of a truncated goodness-of-fit test for detecting watermarked text under human edits, which we refer to as Tr-GoF. We prove that the Tr-GoF test achieves optimality in robust detection of the Gumbel-max watermark in a certain asymptotic regime of substantial text modifications and vanishing watermark signals. Importantly, Tr-GoF achieves this optimality \textit{adaptively} as it does not require precise knowledge of human edit levels or probabilistic specifications of the LLMs, in contrast to the optimal but impractical (Neyman--Pearson) likelihood ratio test. Moreover, we establish that the Tr-GoF test attains the highest detection efficiency rate in a certain regime of moderate text modifications. In stark contrast, we show that sum-based detection rules, as employed by existing methods, fail to achieve optimal robustness in both regimes because the additive nature of their statistics is less resilient to edit-induced noise. Finally, we demonstrate the competitive and sometimes superior empirical performance of the Tr-GoF test on both synthetic data and open-source LLMs in the OPT and LLaMA families.
Investigating the Impact of Model Complexity in Large Language Models
Oct 01, 2024Large Language Models (LLMs) based on the pre-trained fine-tuning paradigm have become pivotal in solving natural language processing tasks, consistently achieving state-of-the-art performance. Nevertheless, the theoretical understanding of how model complexity influences fine-tuning performance remains challenging and has not been well explored yet. In this paper, we focus on autoregressive LLMs and propose to employ Hidden Markov Models (HMMs) to model them. Based on the HMM modeling, we investigate the relationship between model complexity and the generalization capability in downstream tasks. Specifically, we consider a popular tuning paradigm for downstream tasks, head tuning, where all pre-trained parameters are frozen and only individual heads are trained atop pre-trained LLMs. Our theoretical analysis reveals that the risk initially increases and then decreases with rising model complexity, showcasing a "double descent" phenomenon. In this case, the initial "descent" is degenerate, signifying that the "sweet spot" where bias and variance are balanced occurs when the model size is zero. Obtaining the presented in this study conclusion confronts several challenges, primarily revolving around effectively modeling autoregressive LLMs and downstream tasks, as well as conducting a comprehensive risk analysis for multivariate regression. Our research is substantiated by experiments conducted on data generated from HMMs, which provided empirical support and alignment with our theoretical insights.
A Statistical Theory of Regularization-Based Continual Learning
Jun 10, 2024

We provide a statistical analysis of regularization-based continual learning on a sequence of linear regression tasks, with emphasis on how different regularization terms affect the model performance. We first derive the convergence rate for the oracle estimator obtained as if all data were available simultaneously. Next, we consider a family of generalized $\ell_2$-regularization algorithms indexed by matrix-valued hyperparameters, which includes the minimum norm estimator and continual ridge regression as special cases. As more tasks are introduced, we derive an iterative update formula for the estimation error of generalized $\ell_2$-regularized estimators, from which we determine the hyperparameters resulting in the optimal algorithm. Interestingly, the choice of hyperparameters can effectively balance the trade-off between forward and backward knowledge transfer and adjust for data heterogeneity. Moreover, the estimation error of the optimal algorithm is derived explicitly, which is of the same order as that of the oracle estimator. In contrast, our lower bounds for the minimum norm estimator and continual ridge regression show their suboptimality. A byproduct of our theoretical analysis is the equivalence between early stopping and generalized $\ell_2$-regularization in continual learning, which may be of independent interest. Finally, we conduct experiments to complement our theory.
A Statistical Framework of Watermarks for Large Language Models: Pivot, Detection Efficiency and Optimal Rules
Apr 01, 2024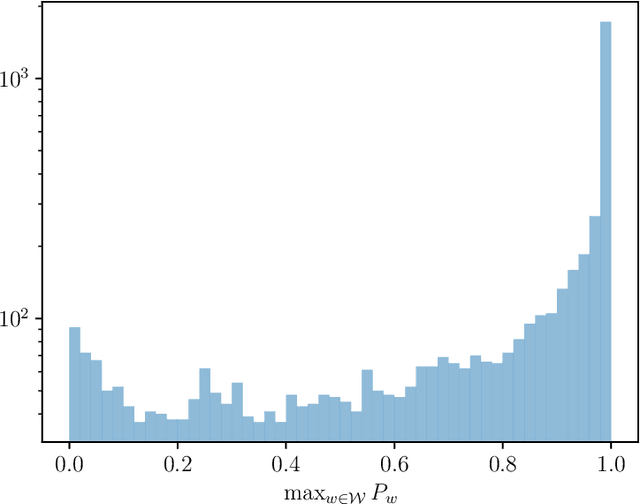

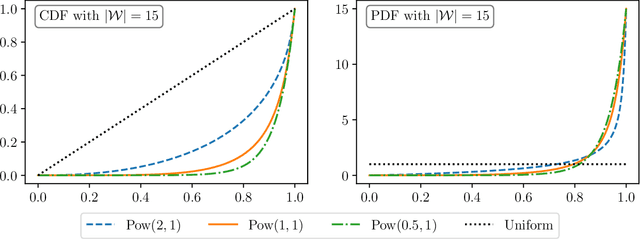
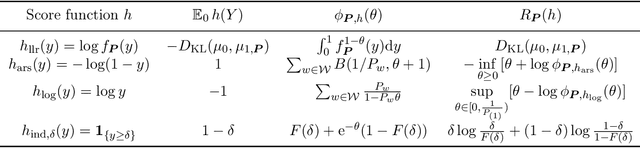
Since ChatGPT was introduced in November 2022, embedding (nearly) unnoticeable statistical signals into text generated by large language models (LLMs), also known as watermarking, has been used as a principled approach to provable detection of LLM-generated text from its human-written counterpart. In this paper, we introduce a general and flexible framework for reasoning about the statistical efficiency of watermarks and designing powerful detection rules. Inspired by the hypothesis testing formulation of watermark detection, our framework starts by selecting a pivotal statistic of the text and a secret key -- provided by the LLM to the verifier -- to enable controlling the false positive rate (the error of mistakenly detecting human-written text as LLM-generated). Next, this framework allows one to evaluate the power of watermark detection rules by obtaining a closed-form expression of the asymptotic false negative rate (the error of incorrectly classifying LLM-generated text as human-written). Our framework further reduces the problem of determining the optimal detection rule to solving a minimax optimization program. We apply this framework to two representative watermarks -- one of which has been internally implemented at OpenAI -- and obtain several findings that can be instrumental in guiding the practice of implementing watermarks. In particular, we derive optimal detection rules for these watermarks under our framework. These theoretically derived detection rules are demonstrated to be competitive and sometimes enjoy a higher power than existing detection approaches through numerical experiments.
Coreset selection can accelerate quantum machine learning models with provable generalization
Sep 19, 2023
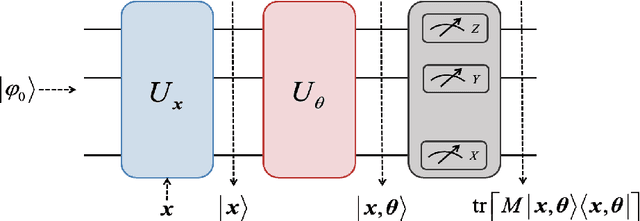
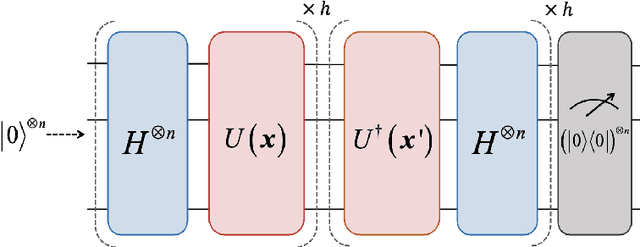
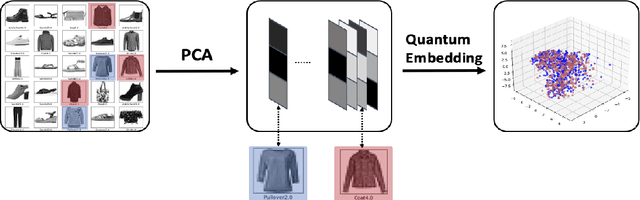
Quantum neural networks (QNNs) and quantum kernels stand as prominent figures in the realm of quantum machine learning, poised to leverage the nascent capabilities of near-term quantum computers to surmount classical machine learning challenges. Nonetheless, the training efficiency challenge poses a limitation on both QNNs and quantum kernels, curbing their efficacy when applied to extensive datasets. To confront this concern, we present a unified approach: coreset selection, aimed at expediting the training of QNNs and quantum kernels by distilling a judicious subset from the original training dataset. Furthermore, we analyze the generalization error bounds of QNNs and quantum kernels when trained on such coresets, unveiling the comparable performance with those training on the complete original dataset. Through systematic numerical simulations, we illuminate the potential of coreset selection in expediting tasks encompassing synthetic data classification, identification of quantum correlations, and quantum compiling. Our work offers a useful way to improve diverse quantum machine learning models with a theoretical guarantee while reducing the training cost.
CARE: Large Precision Matrix Estimation for Compositional Data
Sep 13, 2023High-dimensional compositional data are prevalent in many applications. The simplex constraint poses intrinsic challenges to inferring the conditional dependence relationships among the components forming a composition, as encoded by a large precision matrix. We introduce a precise specification of the compositional precision matrix and relate it to its basis counterpart, which is shown to be asymptotically identifiable under suitable sparsity assumptions. By exploiting this connection, we propose a composition adaptive regularized estimation (CARE) method for estimating the sparse basis precision matrix. We derive rates of convergence for the estimator and provide theoretical guarantees on support recovery and data-driven parameter tuning. Our theory reveals an intriguing trade-off between identification and estimation, thereby highlighting the blessing of dimensionality in compositional data analysis. In particular, in sufficiently high dimensions, the CARE estimator achieves minimax optimality and performs as well as if the basis were observed. We further discuss how our framework can be extended to handle data containing zeros, including sampling zeros and structural zeros. The advantages of CARE over existing methods are illustrated by simulation studies and an application to inferring microbial ecological networks in the human gut.
Heterogeneous Federated Learning on a Graph
Sep 19, 2022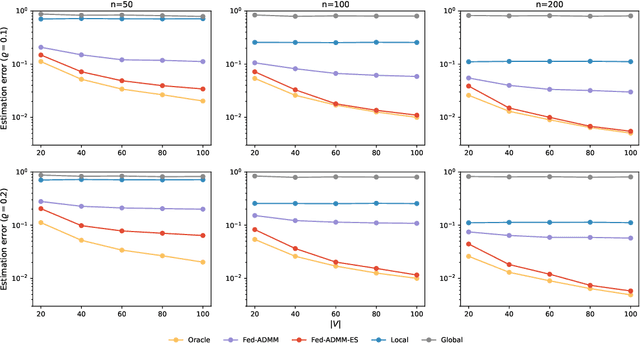


Federated learning, where algorithms are trained across multiple decentralized devices without sharing local data, is increasingly popular in distributed machine learning practice. Typically, a graph structure $G$ exists behind local devices for communication. In this work, we consider parameter estimation in federated learning with data distribution and communication heterogeneity, as well as limited computational capacity of local devices. We encode the distribution heterogeneity by parametrizing distributions on local devices with a set of distinct $p$-dimensional vectors. We then propose to jointly estimate parameters of all devices under the $M$-estimation framework with the fused Lasso regularization, encouraging an equal estimate of parameters on connected devices in $G$. We provide a general result for our estimator depending on $G$, which can be further calibrated to obtain convergence rates for various specific problem setups. Surprisingly, our estimator attains the optimal rate under certain graph fidelity condition on $G$, as if we could aggregate all samples sharing the same distribution. If the graph fidelity condition is not met, we propose an edge selection procedure via multiple testing to ensure the optimality. To ease the burden of local computation, a decentralized stochastic version of ADMM is provided, with convergence rate $O(T^{-1}\log T)$ where $T$ denotes the number of iterations. We highlight that, our algorithm transmits only parameters along edges of $G$ at each iteration, without requiring a central machine, which preserves privacy. We further extend it to the case where devices are randomly inaccessible during the training process, with a similar algorithmic convergence guarantee. The computational and statistical efficiency of our method is evidenced by simulation experiments and the 2020 US presidential election data set.
Harmless Overparametrization in Two-layer Neural Networks
Jun 09, 2021
Overparametrized neural networks, where the number of active parameters is larger than the sample size, prove remarkably effective in modern deep learning practice. From the classical perspective, however, much fewer parameters are sufficient for optimal estimation and prediction, whereas overparametrization can be harmful even in the presence of explicit regularization. To reconcile this conflict, we present a generalization theory for overparametrized ReLU networks by incorporating an explicit regularizer based on the scaled variation norm. Interestingly, this regularizer is equivalent to the ridge from the angle of gradient-based optimization, but is similar to the group lasso in terms of controlling model complexity. By exploiting this ridge-lasso duality, we show that overparametrization is generally harmless to two-layer ReLU networks. In particular, the overparametrized estimators are minimax optimal up to a logarithmic factor. By contrast, we show that overparametrized random feature models suffer from the curse of dimensionality and thus are suboptimal.