 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Capability in Token Space: An Analysis of Large Vision Language Model
Dec 30, 2024



The scaling capability has been widely validated in neural language models with respect to the number of parameters and the size of training data. One important question is that does the scaling capability also exists similarly with respect to the number of vision tokens in large vision language Model? This study fills the gap by investigating the relationship between the number of vision tokens and the performance on vision-language models. Our theoretical analysis and empirical evaluations demonstrate that the model exhibits scalable performance \(S(N_l)\) with respect to the number of vision tokens \(N_l\), characterized by the relationship \(S(N_l) \approx (c/N_l)^{\alpha}\). Furthermore, we also investigate the impact of a fusion mechanism that integrates the user's question with vision tokens. The results reveal two key findings. First, the scaling capability remains intact with the incorporation of the fusion mechanism. Second, the fusion mechanism enhances model performance, particularly when the user's question is task-specific and relevant. The analysis, conducted on fifteen diverse benchmarks spanning a broad range of tasks and domains, validates the effectiveness of the proposed approach.
Weak Scaling Capability in Token Space: An Observation from Large Vision Language Model
Dec 24, 2024The scaling capability has been widely validated with respect to the number of parameters and the size of training data. One important question that is unexplored is that does scaling capability also exists similarly with respect to the number of vision tokens? This study fills the gap by investigating the relationship between the number of vision tokens and the performance of vision-language models. Our theoretical analysis and empirical evaluations reveal that the model exhibits weak scaling capabilities on the length \(N_l\), with performance approximately \(S(N_l) \approx (c/N_l)^{\alpha}\), where \(c, \alpha\) are hyperparameters. Interestingly, this scaling behavior remains largely unaffected by the inclusion or exclusion of the user's question in the input. Furthermore, fusing the user's question with the vision token can enhance model performance when the question is relevant to the task. To address the computational challenges associated with large-scale vision tokens, we propose a novel architecture that efficiently reduces the token count while integrating user question tokens into the representation. Our findings may offer insights for developing more efficient and effective vision-language models under specific task constraints.
Understanding Convolutional Neural Networks from Theoretical Perspective via Volterra Convolution
Oct 19, 2021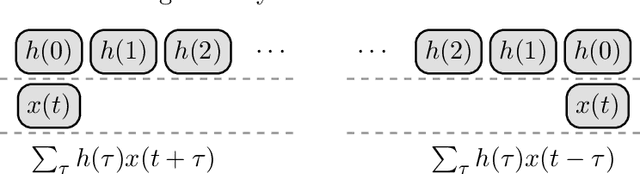

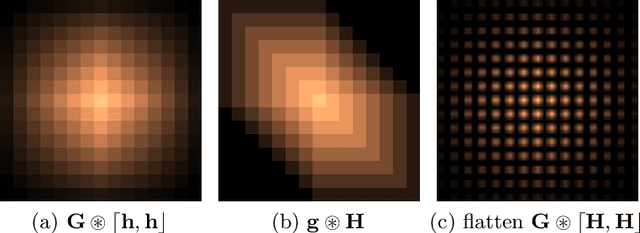
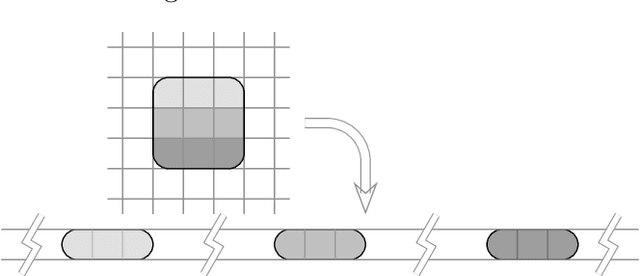
This study proposes a general and unified perspective of convolutional neural networks by exploring the relationship between (deep) convolutional neural networks and finite Volterra convolutions. It provides a novel approach to explain and study the overall characteristics of neural networks without being disturbed by the complex network architectures. Concretely, we examine the basic structures of finite term Volterra convolutions and convolutional neural networks. Our results show that convolutional neural network is an approximation of the finite term Volterra convolution, whose order increases exponentially with the number of layers and kernel size increases exponentially with the strides. With this perspective, the specialized perturbations are directly obtained from the approximated kernels rather than iterative generated adversarial examples. Extensive experiments on synthetic and real-world data sets show the correctness and effectiveness of our results.