 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Deep Learning-based Brain Tumor Segmentation with 3D UNets and Explainable AI (XAI): A Comparative Analysis
Oct 09, 2025The current study investigated the use of Explainable Artificial Intelligence (XAI) to improve the accuracy of brain tumor segmentation in MRI images, with the goal of assisting physicians in clinical decision-making. The study focused on applying UNet models for brain tumor segmentation and using the XAI techniques of Gradient-weighted Class Activation Mapping (Grad-CAM) and attention-based visualization to enhance the understanding of these models. Three deep learning models - UNet, Residual UNet (ResUNet), and Attention UNet (AttUNet) - were evaluated to identify the best-performing model. XAI was employed with the aims of clarifying model decisions and increasing physicians' trust in these models. We compared the performance of two UNet variants (ResUNet and AttUNet) with the conventional UNet in segmenting brain tumors from the BraTS2020 public dataset and analyzed model predictions with Grad-CAM and attention-based visualization. Using the latest computer hardware, we trained and validated each model using the Adam optimizer and assessed their performance with respect to: (i) training, validation, and inference times, (ii) segmentation similarity coefficients and loss functions, and (iii) classification performance. Notably, during the final testing phase, ResUNet outperformed the other models with respect to Dice and Jaccard similarity scores, as well as accuracy, recall, and F1 scores. Grad-CAM provided visuospatial insights into the tumor subregions each UNet model focused on while attention-based visualization provided valuable insights into the working mechanisms of AttUNet's attention modules. These results demonstrated ResUNet as the best-performing model and we conclude by recommending its use for automated brain tumor segmentation in future clinical assessments. Our source code and checkpoint are available at https://github.com/ethanong98/MultiModel-XAI-Brats2020
SleepDIFFormer: Sleep Stage Classification via Multivariate Differential Transformer
Aug 21, 2025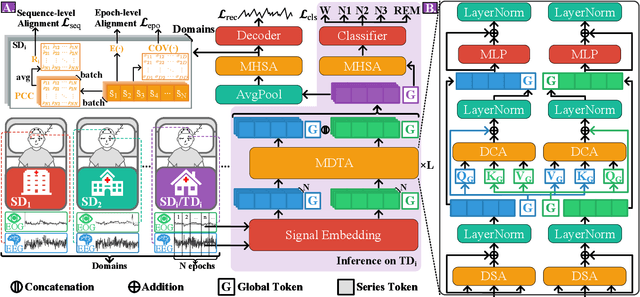



Classification of sleep stages is essential for assessing sleep quality and diagnosing sleep disorders such as insomnia. However, manual inspection of EEG characteristics for each stage is time-consuming and prone to human error. Although machine learning and deep learning methods have been actively developed, they continue to face challenges from the non-stationarity and variability of electroencephalography (EEG) and electrooculography (EOG) signals, often leading to poor generalization on unseen datasets. This research proposed a Sleep Stage Classification method by developing Multivariate Differential Transformer (SleepDIFFormer) for joint EEG and EOG representation learning. Specifically, SleepDIFFormer was developed to process EEG and EOG signals using our Multivariate Differential Transformer Architecture (MDTA) for time series, trained with cross-domain alignment. Our method mitigated spatial and temporal attention noise while learning a domain-invariant joint EEG-EOG representation through feature distribution alignment, thereby enabling generalization to unseen target datasets. Empirically, we evaluated our method on five different sleep staging datasets and compared it with existing approaches, achieving state-of-the-art performance. We also conducted thorough ablation analyses of SleepDIFFormer and interpreted the differential attention weights, highlighting their relevance to characteristic sleep EEG patterns. These findings have implications for advancing automated sleep stage classification and its application to sleep quality assessment. Our source code is publicly available at https://github.com/Ben1001409/SleepDIFFormer
Neural Parameter Search for Slimmer Fine-Tuned Models and Better Transfer
May 24, 2025Foundation models and their checkpoints have significantly advanced deep learning, boosting performance across various applications. However, fine-tuned models often struggle outside their specific domains and exhibit considerable redundancy. Recent studies suggest that combining a pruned fine-tuned model with the original pre-trained model can mitigate forgetting, reduce interference when merging model parameters across tasks, and improve compression efficiency. In this context, developing an effective pruning strategy for fine-tuned models is crucial. Leveraging the advantages of the task vector mechanism, we preprocess fine-tuned models by calculating the differences between them and the original model. Recognizing that different task vector subspaces contribute variably to model performance, we introduce a novel method called Neural Parameter Search (NPS-Pruning) for slimming down fine-tuned models. This method enhances pruning efficiency by searching through neural parameters of task vectors within low-rank subspaces. Our method has three key applications: enhancing knowledge transfer through pairwise model interpolation, facilitating effective knowledge fusion via model merging, and enabling the deployment of compressed models that retain near-original performance while significantly reducing storage costs. Extensive experiments across vision, NLP, and multi-modal benchmarks demonstrate the effectiveness and robustness of our approach, resulting in substantial performance gains. The code is publicly available at: https://github.com/duguodong7/NPS-Pruning.
Multi-Modality Expansion and Retention for LLMs through Parameter Merging and Decoupling
May 21, 2025Fine-tuning Large Language Models (LLMs) with multimodal encoders on modality-specific data expands the modalities that LLMs can handle, leading to the formation of Multimodal LLMs (MLLMs). However, this paradigm heavily relies on resource-intensive and inflexible fine-tuning from scratch with new multimodal data. In this paper, we propose MMER (Multi-modality Expansion and Retention), a training-free approach that integrates existing MLLMs for effective multimodal expansion while retaining their original performance. Specifically, MMER reuses MLLMs' multimodal encoders while merging their LLM parameters. By comparing original and merged LLM parameters, MMER generates binary masks to approximately separate LLM parameters for each modality. These decoupled parameters can independently process modality-specific inputs, reducing parameter conflicts and preserving original MLLMs' fidelity. MMER can also mitigate catastrophic forgetting by applying a similar process to MLLMs fine-tuned on new tasks. Extensive experiments show significant improvements over baselines, proving that MMER effectively expands LLMs' multimodal capabilities while retaining 99% of the original performance, and also markedly mitigates catastrophic forgetting.
Disentangling Task Interference within Neurons: Model Merging in Alignment with Neuronal Mechanisms
Mar 07, 2025Fine-tuning pre-trained models on targeted datasets enhances task-specific performance but often comes at the expense of generalization. Model merging techniques, which integrate multiple fine-tuned models into a single multi-task model through task arithmetic at various levels: model, layer, or parameter, offer a promising solution. However, task interference remains a fundamental challenge, leading to performance degradation and suboptimal merged models. Existing approaches largely overlook the fundamental role of individual neurons and their connectivity, resulting in a lack of interpretability in both the merging process and the merged models. In this work, we present the first study on the impact of neuronal alignment in model merging. We decompose task-specific representations into two complementary neuronal subspaces that regulate neuron sensitivity and input adaptability. Leveraging this decomposition, we introduce NeuroMerging, a novel merging framework developed to mitigate task interference within neuronal subspaces, enabling training-free model fusion across diverse tasks. Through extensive experiments, we demonstrate that NeuroMerging achieves superior performance compared to existing methods on multi-task benchmarks across both vision and natural language domains. Our findings highlight the importance of aligning neuronal mechanisms in model merging, offering new insights into mitigating task interference and improving knowledge fusion.
Parameter Competition Balancing for Model Merging
Oct 03, 2024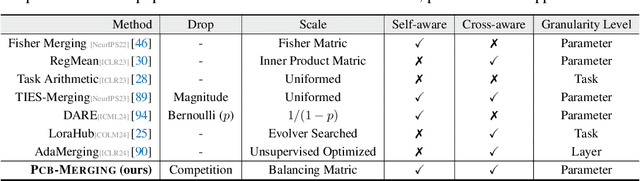
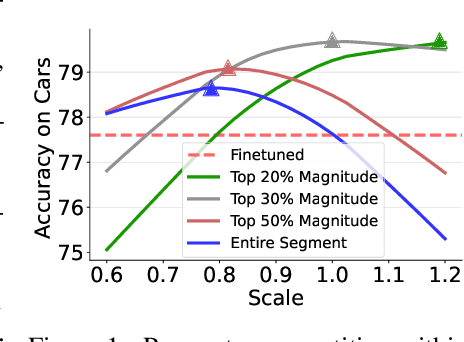
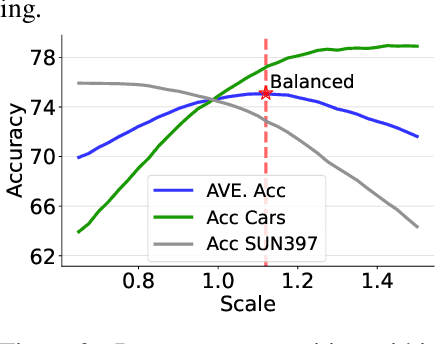
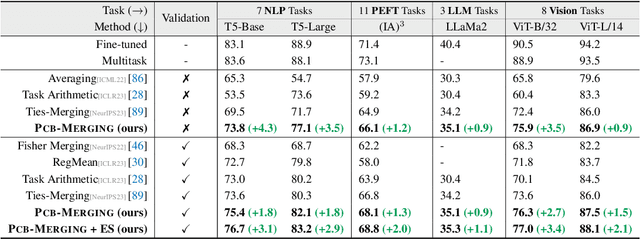
While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named PCB-Merging (Parameter Competition Balancing), a lightweight and training-free technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods. The code is publicly available at: \url{https://github.com/duguodong7/pcb-merging}.
Meta-heuristic Optimizer Inspired by the Philosophy of Yi Jing
Aug 10, 2024Drawing inspiration from the philosophy of Yi Jing, the Yin-Yang pair optimization (YYPO) algorithm has been shown to achieve competitive performance in single objective optimizations, in addition to the advantage of low time complexity when compared to other population-based meta-heuristics. Building upon a reversal concept in Yi Jing, we propose the novel Yi optimization (YI) algorithm. Specifically, we enhance the Yin-Yang pair in YYPO with a proposed Yi-point, in which we use Cauchy flight to update the solution, by implementing both the harmony and reversal concept of Yi Jing. The proposed Yi-point balances both the effort of exploration and exploitation in the optimization process. To examine YI, we use the IEEE CEC 2017 benchmarks and compare YI against the dynamical YYPO, CV1.0 optimizer, and four classical optimizers, i.e., the differential evolution, the genetic algorithm, the particle swarm optimization, and the simulated annealing. According to the experimental results, YI shows highly competitive performance while keeping the low time complexity. The results of this work have implications for enhancing a meta-heuristic optimizer using the philosophy of Yi Jing. While this work implements only certain aspects of Yi Jing, we envisage enhanced performance by incorporating other aspects.
Impacts of Darwinian Evolution on Pre-trained Deep Neural Networks
Aug 10, 2024Darwinian evolution of the biological brain is documented through multiple lines of evidence, although the modes of evolutionary changes remain unclear. Drawing inspiration from the evolved neural systems (e.g., visual cortex), deep learning models have demonstrated superior performance in visual tasks, among others. While the success of training deep neural networks has been relying on back-propagation (BP) and its variants to learn representations from data, BP does not incorporate the evolutionary processes that govern biological neural systems. This work proposes a neural network optimization framework based on evolutionary theory. Specifically, BP-trained deep neural networks for visual recognition tasks obtained from the ending epochs are considered the primordial ancestors (initial population). Subsequently, the population evolved with differential evolution. Extensive experiments are carried out to examine the relationships between Darwinian evolution and neural network optimization, including the correspondence between datasets, environment, models, and living species. The empirical results show that the proposed framework has positive impacts on the network, with reduced over-fitting and an order of magnitude lower time complexity compared to BP. Moreover, the experiments show that the proposed framework performs well on deep neural networks and big datasets.
Knowledge Fusion By Evolving Weights of Language Models
Jun 18, 2024



Fine-tuning pre-trained language models, particularly large language models, demands extensive computing resources and can result in varying performance outcomes across different domains and datasets. This paper examines the approach of integrating multiple models from diverse training scenarios into a unified model. This unified model excels across various data domains and exhibits the ability to generalize well on out-of-domain data. We propose a knowledge fusion method named Evolver, inspired by evolutionary algorithms, which does not need further training or additional training data. Specifically, our method involves aggregating the weights of different language models into a population and subsequently generating offspring models through mutation and crossover operations. These offspring models are then evaluated against their parents, allowing for the preservation of those models that show enhanced performance on development datasets. Importantly, our model evolving strategy can be seamlessly integrated with existing model merging frameworks, offering a versatile tool for model enhancement. Experimental results on mainstream language models (i.e., encoder-only, decoder-only, encoder-decoder) reveal that Evolver outperforms previous state-of-the-art models by large margins. The code is publicly available at {https://github.com/duguodong7/model-evolution}.
CADE: Cosine Annealing Differential Evolution for Spiking Neural Network
Jun 04, 2024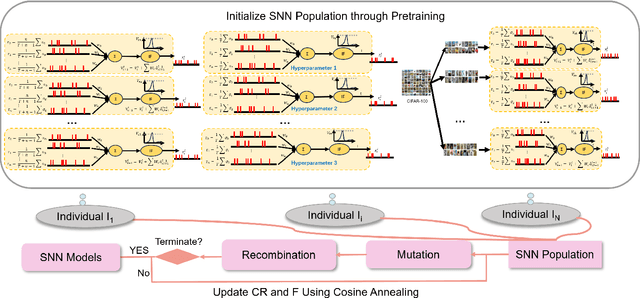



Spiking neural networks (SNNs) have gained prominence for their potential in neuromorphic computing and energy-efficient artificial intelligence, yet optimizing them remains a formidable challenge for gradient-based methods due to their discrete, spike-based computation. This paper attempts to tackle the challenges by introducing Cosine Annealing Differential Evolution (CADE), designed to modulate the mutation factor (F) and crossover rate (CR) of differential evolution (DE) for the SNN model, i.e., Spiking Element Wise (SEW) ResNet. Extensive empirical evaluations were conducted to analyze CADE. CADE showed a balance in exploring and exploiting the search space, resulting in accelerated convergence and improved accuracy compared to existing gradient-based and DE-based methods. Moreover, an initialization method based on a transfer learning setting was developed, pretraining on a source dataset (i.e., CIFAR-10) and fine-tuning the target dataset (i.e., CIFAR-100), to improve population diversity. It was found to further enhance CADE for SNN. Remarkably, CADE elevates the performance of the highest accuracy SEW model by an additional 0.52 percentage points, underscoring its effectiveness in fine-tuning and enhancing SNNs. These findings emphasize the pivotal role of a scheduler for F and CR adjustment, especially for DE-based SNN. Source Code on Github: https://github.com/Tank-Jiang/CADE4SNN.