 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Competition Balancing for Model Merging
Oct 03, 2024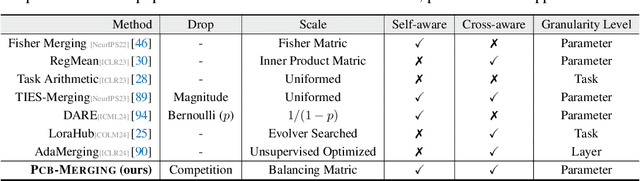
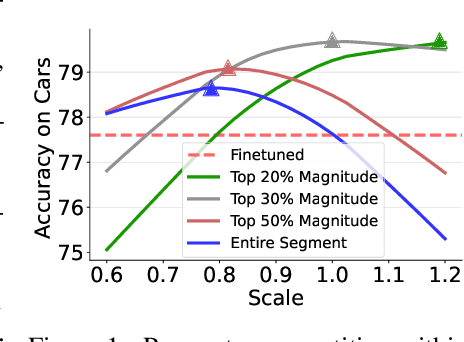
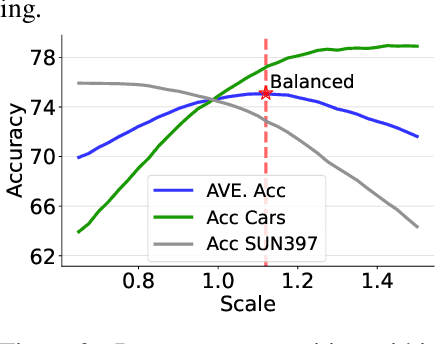
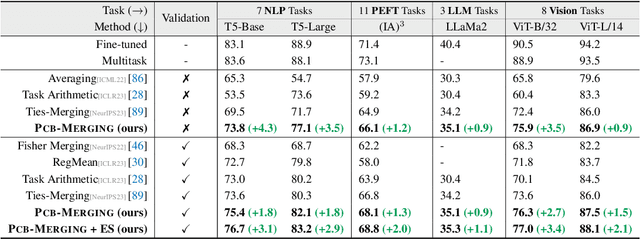
While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named PCB-Merging (Parameter Competition Balancing), a lightweight and training-free technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods. The code is publicly available at: \url{https://github.com/duguodong7/pcb-merging}.
Multimodal Reasoning with Multimodal Knowledge Graph
Jun 04, 2024Multimodal reasoning with large language models (LLMs) often suffers from hallucinations and the presence of deficient or outdated knowledge within LLMs. Some approaches have sought to mitigate these issues by employing textual knowledge graphs, but their singular modality of knowledge limits comprehensive cross-modal understanding. In this paper, we propose the Multimodal Reasoning with Multimodal Knowledge Graph (MR-MKG) method, which leverages multimodal knowledge graphs (MMKGs) to learn rich and semantic knowledge across modalities, significantly enhancing the multimodal reasoning capabilities of LLMs. In particular, a relation graph attention network is utilized for encoding MMKGs and a cross-modal alignment module is designed for optimizing image-text alignment. A MMKG-grounded dataset is constructed to equip LLMs with initial expertise in multimodal reasoning through pretraining. Remarkably, MR-MKG achieves superior performance while training on only a small fraction of parameters, approximately 2.25% of the LLM's parameter size. Experimental results on multimodal question answering and multimodal analogy reasoning tasks demonstrate that our MR-MKG method outperforms previous state-of-the-art models.