 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Competition Balancing for Model Merging
Oct 03, 2024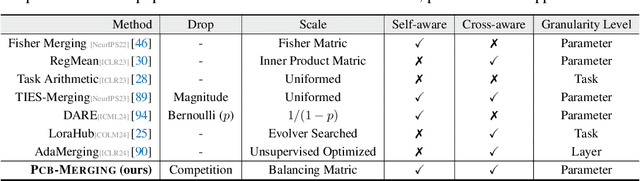
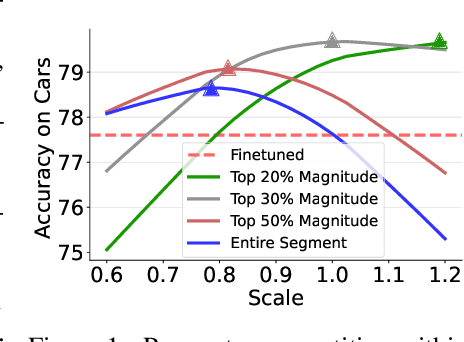
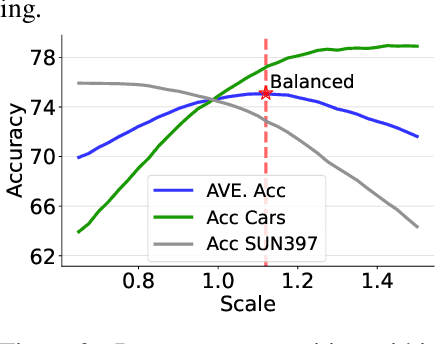
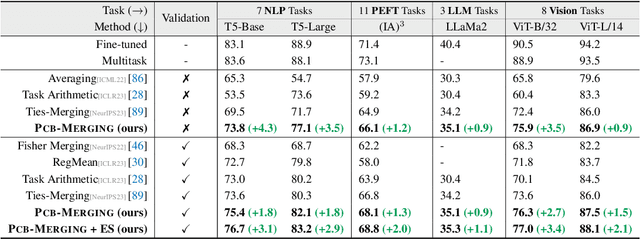
While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named PCB-Merging (Parameter Competition Balancing), a lightweight and training-free technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods. The code is publicly available at: \url{https://github.com/duguodong7/pcb-merging}.
Knowledge Fusion By Evolving Weights of Language Models
Jun 18, 2024



Fine-tuning pre-trained language models, particularly large language models, demands extensive computing resources and can result in varying performance outcomes across different domains and datasets. This paper examines the approach of integrating multiple models from diverse training scenarios into a unified model. This unified model excels across various data domains and exhibits the ability to generalize well on out-of-domain data. We propose a knowledge fusion method named Evolver, inspired by evolutionary algorithms, which does not need further training or additional training data. Specifically, our method involves aggregating the weights of different language models into a population and subsequently generating offspring models through mutation and crossover operations. These offspring models are then evaluated against their parents, allowing for the preservation of those models that show enhanced performance on development datasets. Importantly, our model evolving strategy can be seamlessly integrated with existing model merging frameworks, offering a versatile tool for model enhancement. Experimental results on mainstream language models (i.e., encoder-only, decoder-only, encoder-decoder) reveal that Evolver outperforms previous state-of-the-art models by large margins. The code is publicly available at {https://github.com/duguodong7/model-evolution}.