 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Parameter Search for Slimmer Fine-Tuned Models and Better Transfer
May 24, 2025Foundation models and their checkpoints have significantly advanced deep learning, boosting performance across various applications. However, fine-tuned models often struggle outside their specific domains and exhibit considerable redundancy. Recent studies suggest that combining a pruned fine-tuned model with the original pre-trained model can mitigate forgetting, reduce interference when merging model parameters across tasks, and improve compression efficiency. In this context, developing an effective pruning strategy for fine-tuned models is crucial. Leveraging the advantages of the task vector mechanism, we preprocess fine-tuned models by calculating the differences between them and the original model. Recognizing that different task vector subspaces contribute variably to model performance, we introduce a novel method called Neural Parameter Search (NPS-Pruning) for slimming down fine-tuned models. This method enhances pruning efficiency by searching through neural parameters of task vectors within low-rank subspaces. Our method has three key applications: enhancing knowledge transfer through pairwise model interpolation, facilitating effective knowledge fusion via model merging, and enabling the deployment of compressed models that retain near-original performance while significantly reducing storage costs. Extensive experiments across vision, NLP, and multi-modal benchmarks demonstrate the effectiveness and robustness of our approach, resulting in substantial performance gains. The code is publicly available at: https://github.com/duguodong7/NPS-Pruning.
Disentangling Task Interference within Neurons: Model Merging in Alignment with Neuronal Mechanisms
Mar 07, 2025Fine-tuning pre-trained models on targeted datasets enhances task-specific performance but often comes at the expense of generalization. Model merging techniques, which integrate multiple fine-tuned models into a single multi-task model through task arithmetic at various levels: model, layer, or parameter, offer a promising solution. However, task interference remains a fundamental challenge, leading to performance degradation and suboptimal merged models. Existing approaches largely overlook the fundamental role of individual neurons and their connectivity, resulting in a lack of interpretability in both the merging process and the merged models. In this work, we present the first study on the impact of neuronal alignment in model merging. We decompose task-specific representations into two complementary neuronal subspaces that regulate neuron sensitivity and input adaptability. Leveraging this decomposition, we introduce NeuroMerging, a novel merging framework developed to mitigate task interference within neuronal subspaces, enabling training-free model fusion across diverse tasks. Through extensive experiments, we demonstrate that NeuroMerging achieves superior performance compared to existing methods on multi-task benchmarks across both vision and natural language domains. Our findings highlight the importance of aligning neuronal mechanisms in model merging, offering new insights into mitigating task interference and improving knowledge fusion.
The Combined Problem of Online Task Assignment and Lifelong Path Finding in Logistics Warehouses: A Case Study
Feb 11, 2025



We study the combined problem of online task assignment and lifelong path finding, which is crucial for the logistics industries. However, most literature either (1) focuses on lifelong path finding assuming a given task assigner, or (2) studies the offline version of this problem where tasks are known in advance. We argue that, to maximize the system throughput, the online version that integrates these two components should be tackled directly. To this end, we introduce a formal framework of the combined problem and its solution concept. Then, we design a rule-based lifelong planner under a practical robot model that works well even in environments with severe local congestion. Upon that, we automate the search for the task assigner with respect to the underlying path planner. Simulation experiments conducted in warehouse scenarios at \textit{Meituan}, one of the largest shopping platforms in China, demonstrate that (a)~\textit{in terms of time efficiency}, our system requires only 83.77\% of the execution time needed for the currently deployed system at Meituan, outperforming other SOTA algorithms by 8.09\%; (b)~\textit{in terms of economic efficiency}, ours can achieve the same throughput with only 60\% of the agents currently in use.
Parameter Competition Balancing for Model Merging
Oct 03, 2024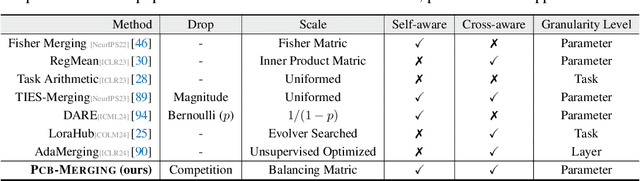
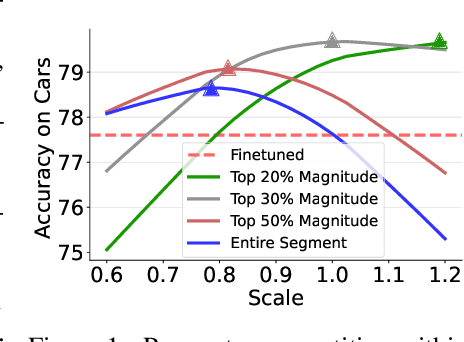
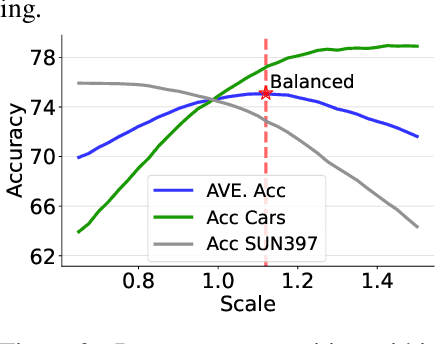
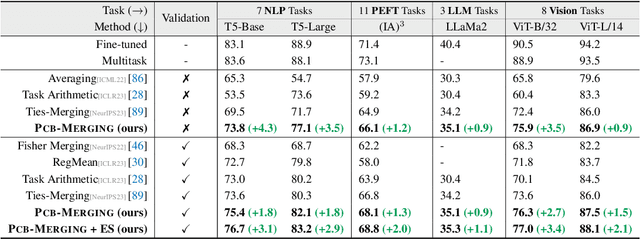
While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named PCB-Merging (Parameter Competition Balancing), a lightweight and training-free technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods. The code is publicly available at: \url{https://github.com/duguodong7/pcb-merging}.
Knowledge Fusion By Evolving Weights of Language Models
Jun 18, 2024



Fine-tuning pre-trained language models, particularly large language models, demands extensive computing resources and can result in varying performance outcomes across different domains and datasets. This paper examines the approach of integrating multiple models from diverse training scenarios into a unified model. This unified model excels across various data domains and exhibits the ability to generalize well on out-of-domain data. We propose a knowledge fusion method named Evolver, inspired by evolutionary algorithms, which does not need further training or additional training data. Specifically, our method involves aggregating the weights of different language models into a population and subsequently generating offspring models through mutation and crossover operations. These offspring models are then evaluated against their parents, allowing for the preservation of those models that show enhanced performance on development datasets. Importantly, our model evolving strategy can be seamlessly integrated with existing model merging frameworks, offering a versatile tool for model enhancement. Experimental results on mainstream language models (i.e., encoder-only, decoder-only, encoder-decoder) reveal that Evolver outperforms previous state-of-the-art models by large margins. The code is publicly available at {https://github.com/duguodong7/model-evolution}.
CADE: Cosine Annealing Differential Evolution for Spiking Neural Network
Jun 04, 2024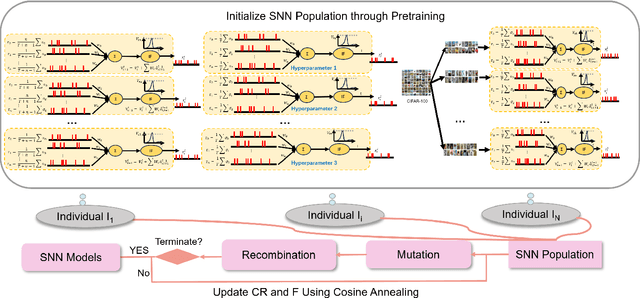



Spiking neural networks (SNNs) have gained prominence for their potential in neuromorphic computing and energy-efficient artificial intelligence, yet optimizing them remains a formidable challenge for gradient-based methods due to their discrete, spike-based computation. This paper attempts to tackle the challenges by introducing Cosine Annealing Differential Evolution (CADE), designed to modulate the mutation factor (F) and crossover rate (CR) of differential evolution (DE) for the SNN model, i.e., Spiking Element Wise (SEW) ResNet. Extensive empirical evaluations were conducted to analyze CADE. CADE showed a balance in exploring and exploiting the search space, resulting in accelerated convergence and improved accuracy compared to existing gradient-based and DE-based methods. Moreover, an initialization method based on a transfer learning setting was developed, pretraining on a source dataset (i.e., CIFAR-10) and fine-tuning the target dataset (i.e., CIFAR-100), to improve population diversity. It was found to further enhance CADE for SNN. Remarkably, CADE elevates the performance of the highest accuracy SEW model by an additional 0.52 percentage points, underscoring its effectiveness in fine-tuning and enhancing SNNs. These findings emphasize the pivotal role of a scheduler for F and CR adjustment, especially for DE-based SNN. Source Code on Github: https://github.com/Tank-Jiang/CADE4SNN.
Distribution Grid Modeling Using Smart Meter Data
Feb 28, 2021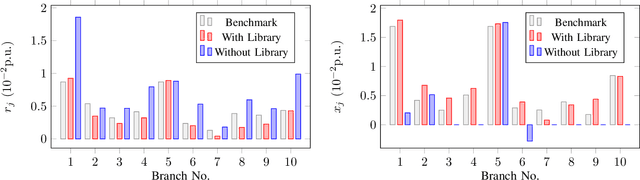
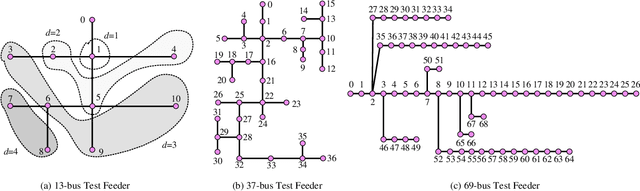
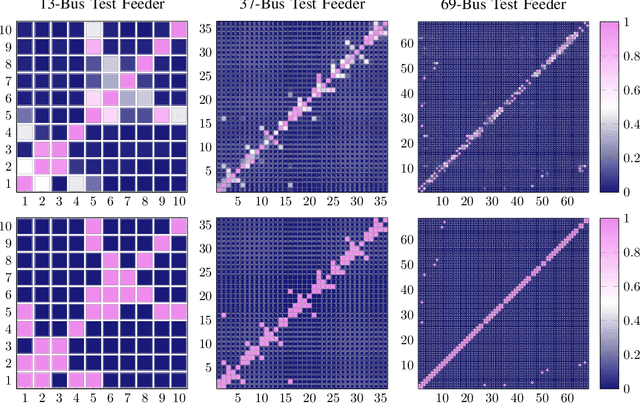
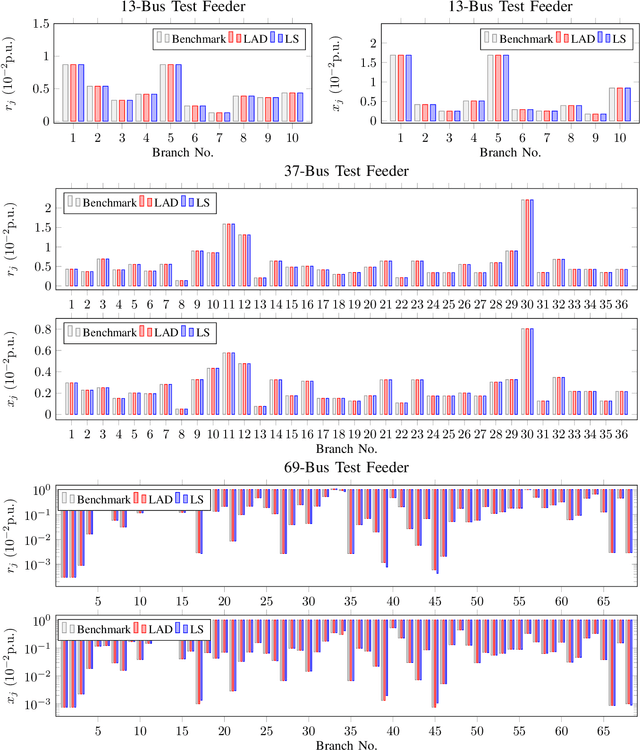
The knowledge of distribution grid models, including topologies and line impedances, is essential to grid monitoring, control and protection. However, this information is often unavailable, incomplete or outdated. The increasing deployment of smart meters (SMs) provides a unique opportunity to address this issue. This paper proposes a two-stage data-driven framework for distribution grid modeling using SM data. In the first stage, we propose to identify the topology via reconstructing a weighted Laplacian matrix of distribution networks, which is mathematically proven to be robust against moderately heterogeneous R/X profiles. In the second stage, we develop nonlinear least absolute deviations (LAD) and least squares (LS) regression models to estimate line impedances of single branches based on a nonlinear inverse power flow, which is then embedded within a bottom-up sweep algorithm to achieve the identification across the network in a branch-wise manner. Because the estimation models are inherently non-convex programs and NP-hard, we specially address their tractable convex relaxations and verify the exactness. In addition, we design a conductor library to significantly narrow down the solution space. Numerical results on the modified IEEE 13-bus, 37-bus and 69-bus test feeders validate the effectiveness of the proposed methods.