 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad
Mar 24, 2025Although foundation models (FMs) claim to be powerful, their generalization ability significantly decreases when faced with distribution shifts, weak supervision, or malicious attacks in the open world. On the other hand, most domain generalization or adversarial fine-tuning methods are task-related or model-specific, ignoring the universality in practical applications and the transferability between FMs. This paper delves into the problem of generalizing FMs to the out-of-domain data. We propose a novel framework, the Object-Concept-Relation Triad (OCRT), that enables FMs to extract sparse, high-level concepts and intricate relational structures from raw visual inputs. The key idea is to bind objects in visual scenes and a set of object-centric representations through unsupervised decoupling and iterative refinement. To be specific, we project the object-centric representations onto a semantic concept space that the model can readily interpret and estimate their importance to filter out irrelevant elements. Then, a concept-based graph, which has a flexible degree, is constructed to incorporate the set of concepts and their corresponding importance, enabling the extraction of high-order factors from informative concepts and facilitating relational reasoning among these concepts. Extensive experiments demonstrate that OCRT can substantially boost the generalizability and robustness of SAM and CLIP across multiple downstream tasks.
Bootstrap Segmentation Foundation Model under Distribution Shift via Object-Centric Learning
Aug 29, 2024



Foundation models have made incredible strides in achieving zero-shot or few-shot generalization, leveraging prompt engineering to mimic the problem-solving approach of human intelligence. However, when it comes to some foundation models like Segment Anything, there is still a challenge in performing well on out-of-distribution data, including camouflaged and medical images. Inconsistent prompting strategies during fine-tuning and testing further compound the issue, leading to decreased performance. Drawing inspiration from how human cognition processes new environments, we introduce SlotSAM, a method that reconstructs features from the encoder in a self-supervised manner to create object-centric representations. These representations are then integrated into the foundation model, bolstering its object-level perceptual capabilities while reducing the impact of distribution-related variables. The beauty of SlotSAM lies in its simplicity and adaptability to various tasks, making it a versatile solution that significantly enhances the generalization abilities of foundation models. Through limited parameter fine-tuning in a bootstrap manner, our approach paves the way for improved generalization in novel environments. The code is available at github.com/lytang63/SlotSAM.
Mixstyle-Entropy: Domain Generalization with Causal Intervention and Perturbation
Aug 22, 2024



Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
InPer: Whole-Process Domain Generalization via Causal Intervention and Perturbation
Aug 07, 2024Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
SUBLLM: A Novel Efficient Architecture with Token Sequence Subsampling for LLM
Jun 03, 2024While Large Language Models (LLMs) have achieved remarkable success in various fields, the efficiency of training and inference remains a major challenge. To address this issue, we propose SUBLLM, short for Subsampling-Upsampling-Bypass Large Language Model, an innovative architecture that extends the core decoder-only framework by incorporating subsampling, upsampling, and bypass modules. The subsampling modules are responsible for shortening the sequence, while the upsampling modules restore the sequence length, and the bypass modules enhance convergence. In comparison to LLaMA, the proposed SUBLLM exhibits significant enhancements in both training and inference speeds as well as memory usage, while maintaining competitive few-shot performance. During training, SUBLLM increases speeds by 26% and cuts memory by 10GB per GPU. In inference, it boosts speeds by up to 37% and reduces memory by 1GB per GPU. The training and inference speeds can be enhanced by 34% and 52% respectively when the context window is expanded to 8192. We shall release the source code of the proposed architecture in the published version.
Data-Driven Outage Restoration Time Prediction via Transfer Learning with Cluster Ensembles
Dec 21, 2021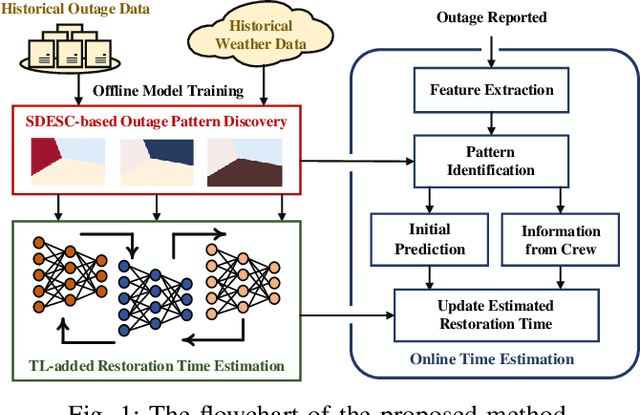
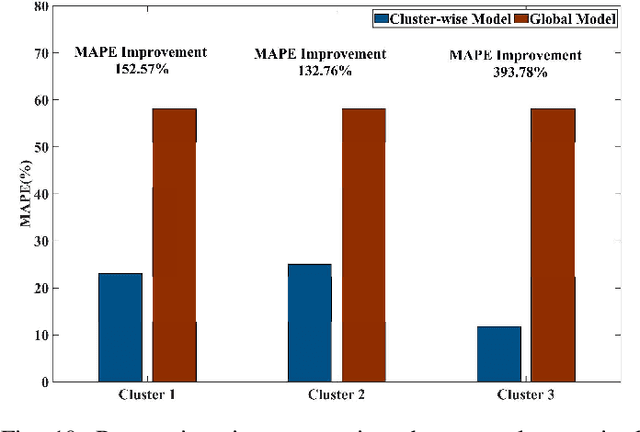
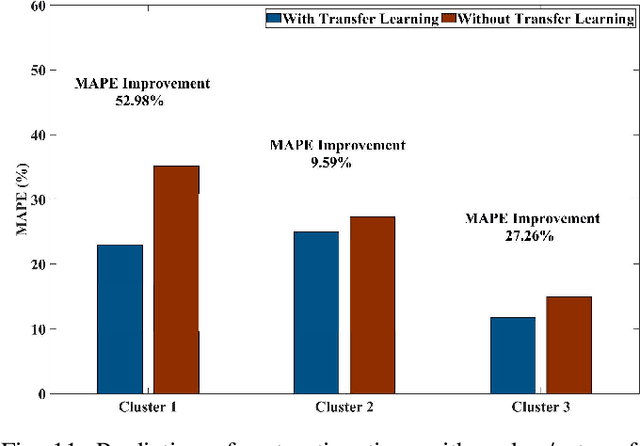
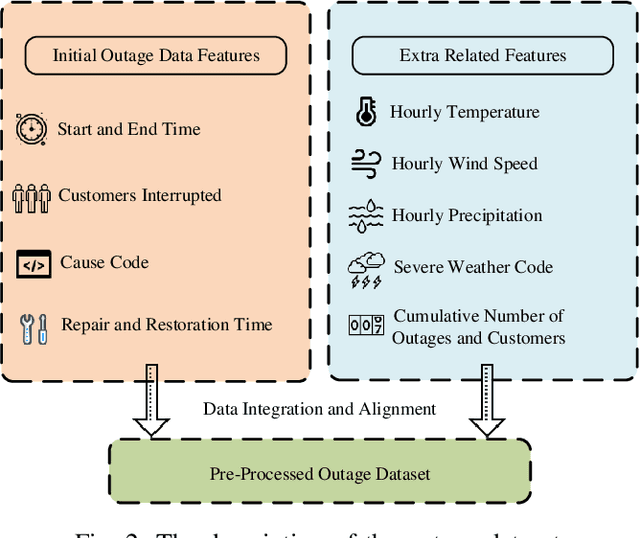
This paper develops a data-driven approach to accurately predict the restoration time of outages under different scales and factors. To achieve the goal, the proposed method consists of three stages. First, given the unprecedented amount of data collected by utilities, a sparse dictionary-based ensemble spectral clustering (SDESC) method is proposed to decompose historical outage datasets, which enjoys good computational efficiency and scalability. Specifically, each outage sample is represented by a linear combination of a small number of selected dictionary samples using a density-based method. Then, the dictionary-based representation is utilized to perform the spectral analysis to group the data samples with similar features into the same subsets. In the second stage, a knowledge-transfer-added restoration time prediction model is trained for each subset by combining weather information and outage-related features. The transfer learning technology is introduced with the aim of dealing with the underestimation problem caused by data imbalance in different subsets, thus improving the model performance. Furthermore, to connect unseen outages with the learned outage subsets, a t-distributed stochastic neighbor embedding-based strategy is applied. The proposed method fully builds on and is also tested on a large real-world outage dataset from a utility provider with a time span of six consecutive years. The numerical results validate that our method has high prediction accuracy while showing good stability against real-world data limitations.
Synthetic Active Distribution System Generation via Unbalanced Graph Generative Adversarial Network
Aug 02, 2021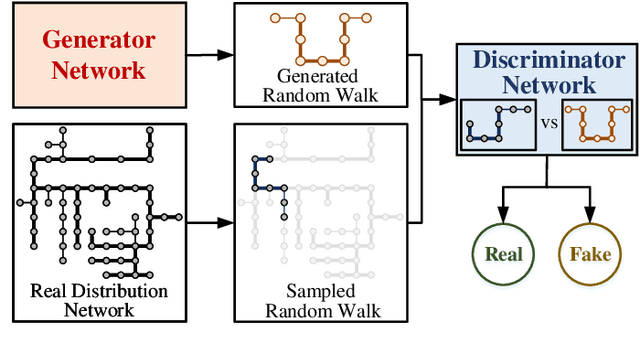
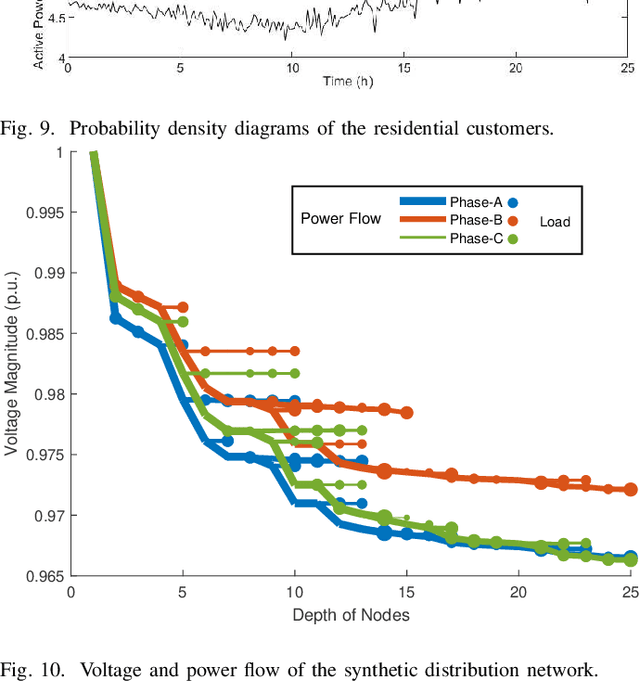
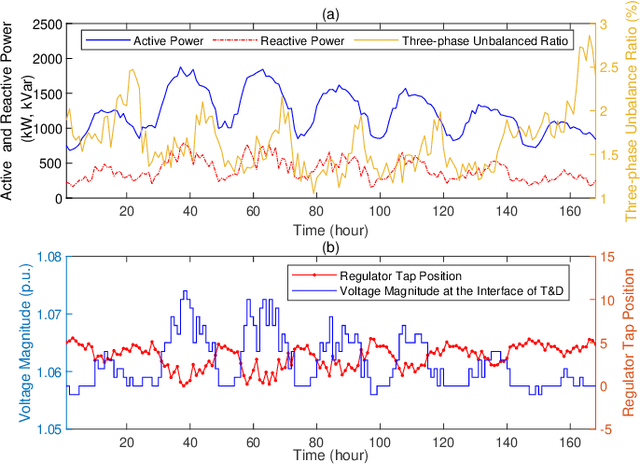
Real active distribution networks with associated smart meter (SM) data are critical for power researchers. However, it is practically difficult for researchers to obtain such comprehensive datasets from utilities due to privacy concerns. To bridge this gap, an implicit generative model with Wasserstein GAN objectives, namely unbalanced graph generative adversarial network (UG-GAN), is designed to generate synthetic three-phase unbalanced active distribution system connectivity. The basic idea is to learn the distribution of random walks both over a real-world system and across each phase of line segments, capturing the underlying local properties of an individual real-world distribution network and generating specific synthetic networks accordingly. Then, to create a comprehensive synthetic test case, a network correction and extension process is proposed to obtain time-series nodal demands and standard distribution grid components with realistic parameters, including distributed energy resources (DERs) and capacity banks. A Midwest distribution system with 1-year SM data has been utilized to validate the performance of our method. Case studies with several power applications demonstrate that synthetic active networks generated by the proposed framework can mimic almost all features of real-world networks while avoiding the disclosure of confidential information.
Mitigating Smart Meter Asynchrony Error Via Multi-Objective Low Rank Matrix Recovery
May 11, 2021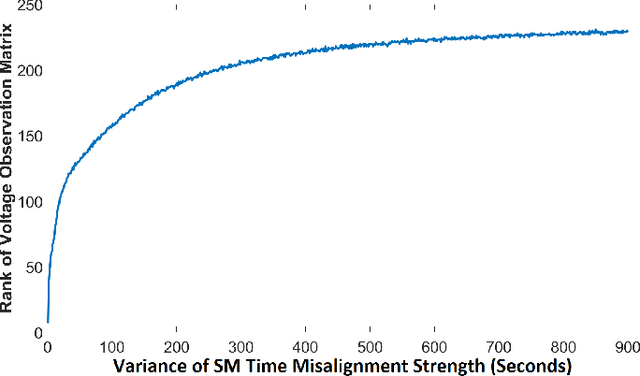
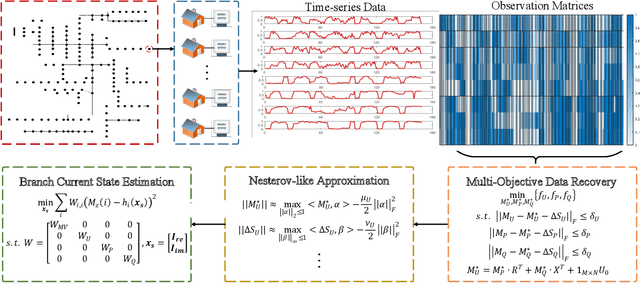
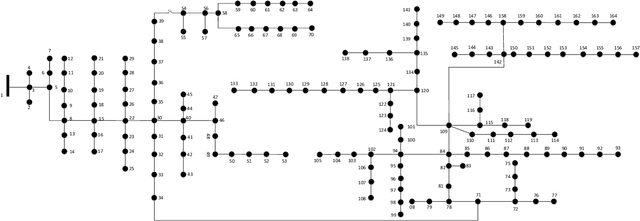
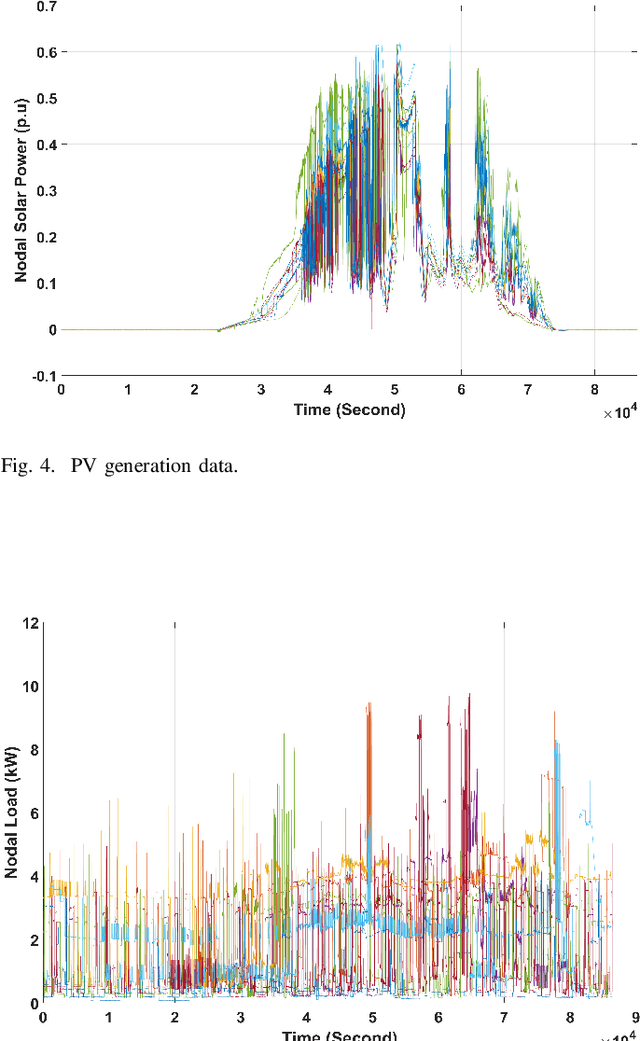
Smart meters (SMs) are being widely deployed by distribution utilities across the U.S. Despite their benefits in real-time monitoring. SMs suffer from certain data quality issues; specifically, unlike phasor measurement units (PMUs) that use GPS for data synchronization, SMs are not perfectly synchronized. The asynchrony error can degrade the monitoring accuracy in distribution networks. To address this challenge, we propose a principal component pursuit (PCP)-based data recovery strategy. Since asynchrony results in a loss of temporal correlation among SMs, the key idea in our solution is to leverage a PCP-based low rank matrix recovery technique to maximize the temporal correlation between multiple data streams obtained from SMs. Further, our approach has a novel multi-objective structure, which allows utilities to precisely refine and recover all SM-measured variables, including voltage and power measurements, while incorporating their inherent dependencies through power flow equations. We have performed numerical experiments using real SM data to demonstrate the effectiveness of the proposed strategy in mitigating the impact of SM asynchrony on distribution grid monitoring.
Distribution Grid Modeling Using Smart Meter Data
Feb 28, 2021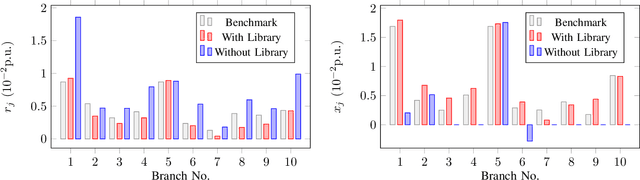
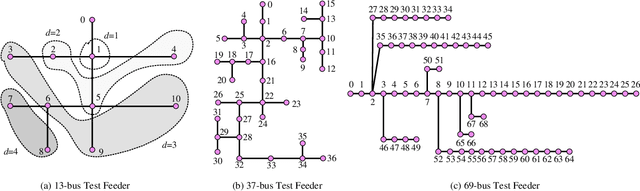
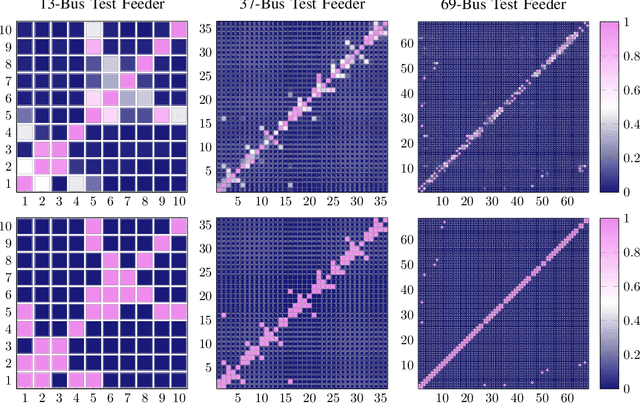
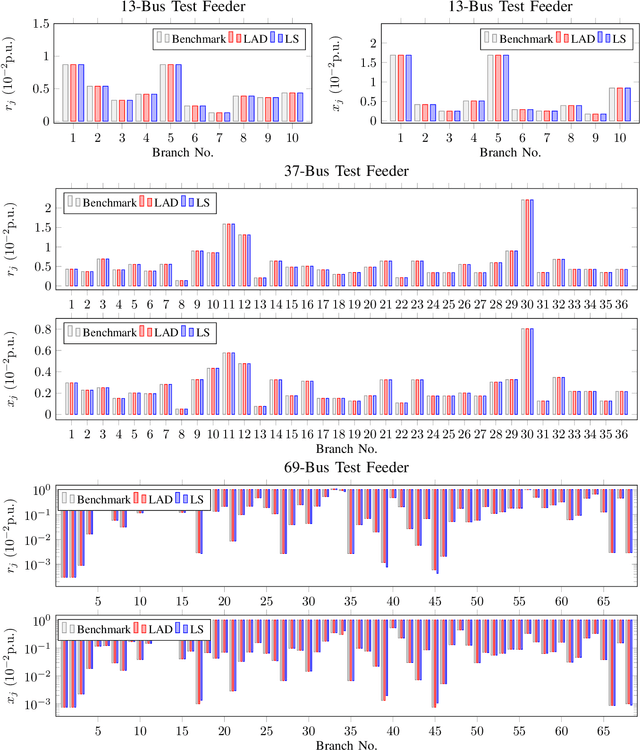
The knowledge of distribution grid models, including topologies and line impedances, is essential to grid monitoring, control and protection. However, this information is often unavailable, incomplete or outdated. The increasing deployment of smart meters (SMs) provides a unique opportunity to address this issue. This paper proposes a two-stage data-driven framework for distribution grid modeling using SM data. In the first stage, we propose to identify the topology via reconstructing a weighted Laplacian matrix of distribution networks, which is mathematically proven to be robust against moderately heterogeneous R/X profiles. In the second stage, we develop nonlinear least absolute deviations (LAD) and least squares (LS) regression models to estimate line impedances of single branches based on a nonlinear inverse power flow, which is then embedded within a bottom-up sweep algorithm to achieve the identification across the network in a branch-wise manner. Because the estimation models are inherently non-convex programs and NP-hard, we specially address their tractable convex relaxations and verify the exactness. In addition, we design a conductor library to significantly narrow down the solution space. Numerical results on the modified IEEE 13-bus, 37-bus and 69-bus test feeders validate the effectiveness of the proposed methods.
A Hierarchical Deep Actor-Critic Learning Method for Joint Distribution System State Estimation
Dec 04, 2020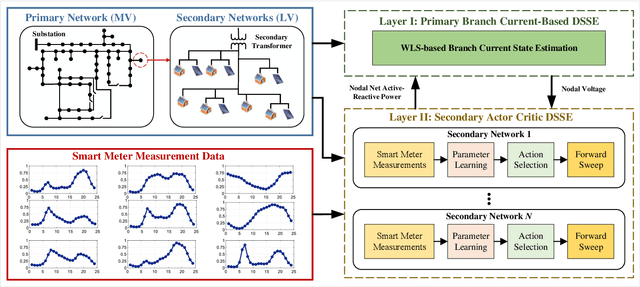
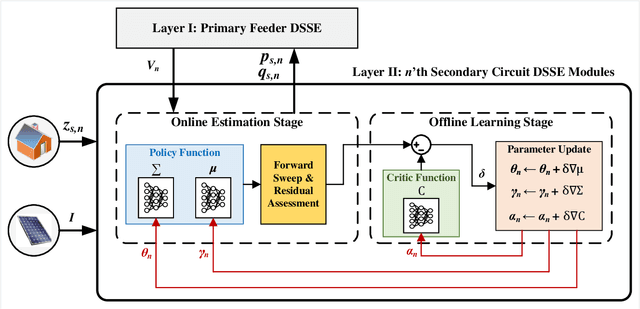
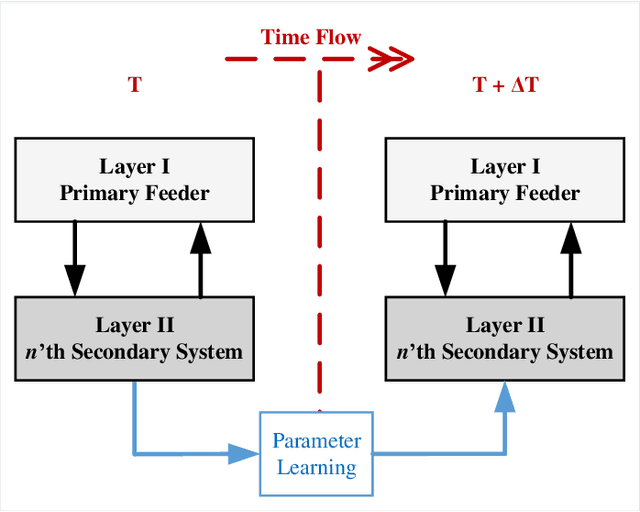
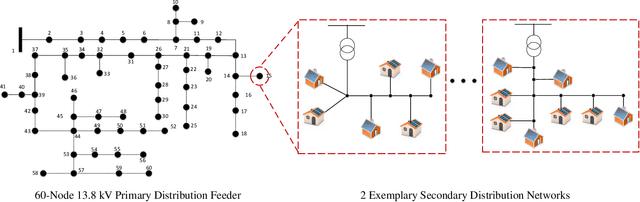
Due to increasing penetration of volatile distributed photovoltaic (PV) resources, real-time monitoring of customers at the grid-edge has become a critical task. However, this requires solving the distribution system state estimation (DSSE) jointly for both primary and secondary levels of distribution grids, which is computationally complex and lacks scalability to large systems. To achieve near real-time solutions for DSSE, we present a novel hierarchical reinforcement learning-aided framework: at the first layer, a weighted least squares (WLS) algorithm solves the DSSE over primary medium-voltage feeders; at the second layer, deep actor-critic (A-C) modules are trained for each secondary transformer using measurement residuals to estimate the states of low-voltage circuits and capture the impact of PVs at the grid-edge. While the A-C parameter learning process takes place offline, the trained A-C modules are deployed online for fast secondary grid state estimation; this is the key factor in scalability and computational efficiency of the framework. To maintain monitoring accuracy, the two levels exchange boundary information with each other at the secondary nodes, including transformer voltages (first layer to second layer) and active/reactive total power injection (second layer to first layer). This interactive information passing strategy results in a closed-loop structure that is able to track optimal solutions at both layers in few iterations. Moreover, our model can handle the topology changes using the Jacobian matrices of the first layer. We have performed numerical experiments using real utility data and feeder models to verify the performance of the proposed framework.