 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024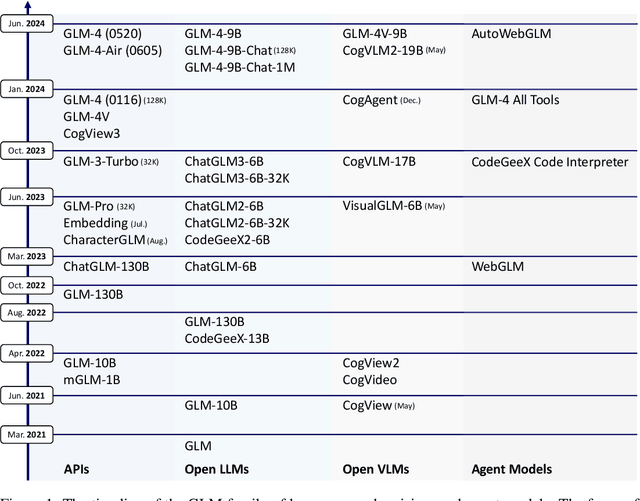
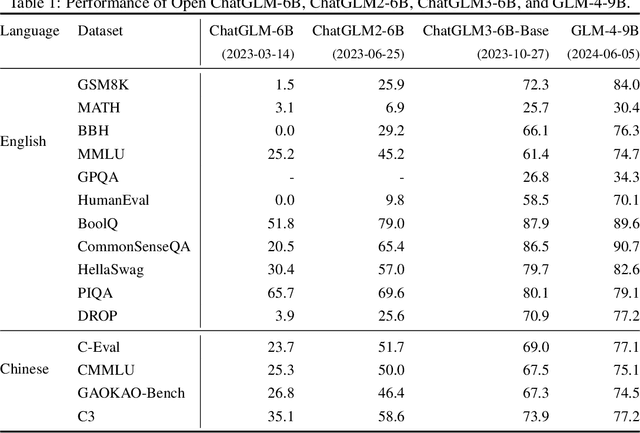
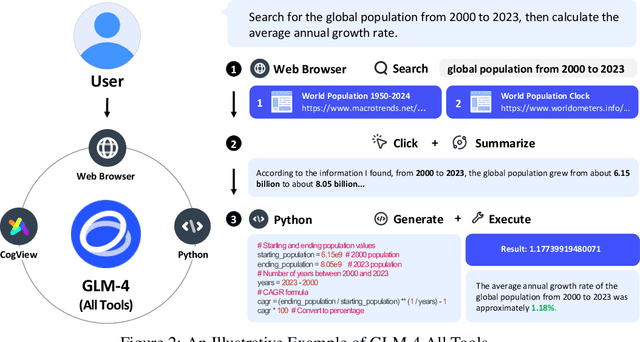
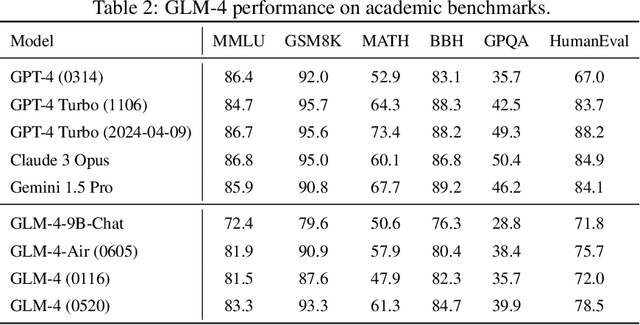
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
Efficacy of ByteT5 in Multilingual Translation of Biblical Texts for Underrepresented Languages
May 22, 2024

This study presents the development and evaluation of a ByteT5-based multilingual translation model tailored for translating the Bible into underrepresented languages. Utilizing the comprehensive Johns Hopkins University Bible Corpus, we trained the model to capture the intricate nuances of character-based and morphologically rich languages. Our results, measured by the BLEU score and supplemented with sample translations, suggest the model can improve accessibility to sacred texts. It effectively handles the distinctive biblical lexicon and structure, thus bridging the linguistic divide. The study also discusses the model's limitations and suggests pathways for future enhancements, focusing on expanding access to sacred literature across linguistic boundaries.
Towards Practical Federated Causal Structure Learning
Jun 19, 2023Understanding causal relations is vital in scientific discovery. The process of causal structure learning involves identifying causal graphs from observational data to understand such relations. Usually, a central server performs this task, but sharing data with the server poses privacy risks. Federated learning can solve this problem, but existing solutions for federated causal structure learning make unrealistic assumptions about data and lack convergence guarantees. FedC2SL is a federated constraint-based causal structure learning scheme that learns causal graphs using a federated conditional independence test, which examines conditional independence between two variables under a condition set without collecting raw data from clients. FedC2SL requires weaker and more realistic assumptions about data and offers stronger resistance to data variability among clients. FedPC and FedFCI are the two variants of FedC2SL for causal structure learning in causal sufficiency and causal insufficiency, respectively. The study evaluates FedC2SL using both synthetic datasets and real-world data against existing solutions and finds it demonstrates encouraging performance and strong resilience to data heterogeneity among clients.
Data-Driven Outage Restoration Time Prediction via Transfer Learning with Cluster Ensembles
Dec 21, 2021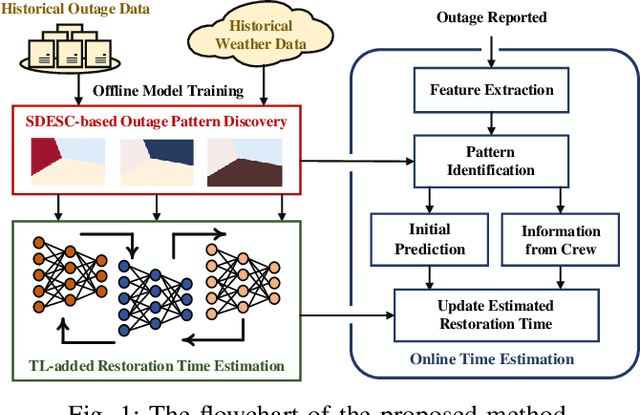
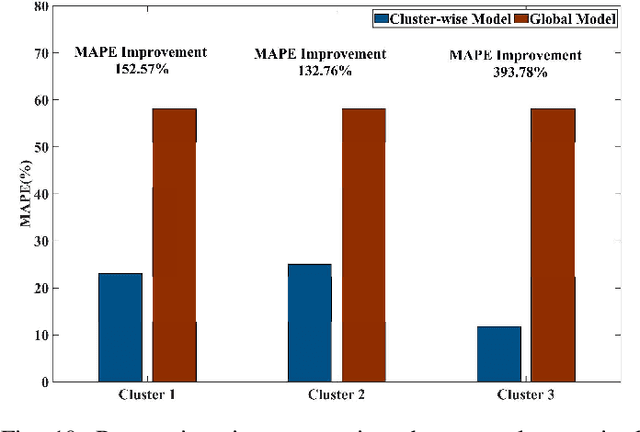
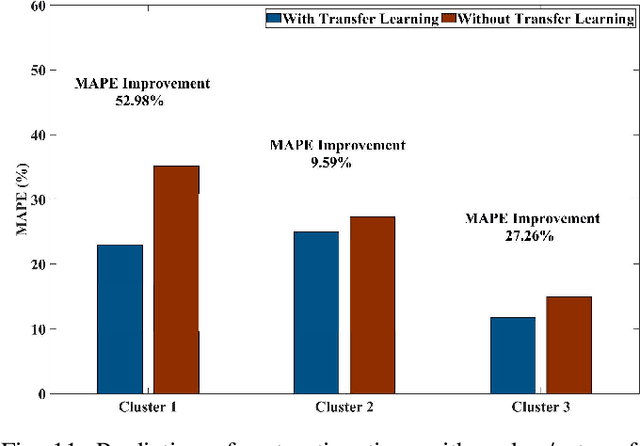
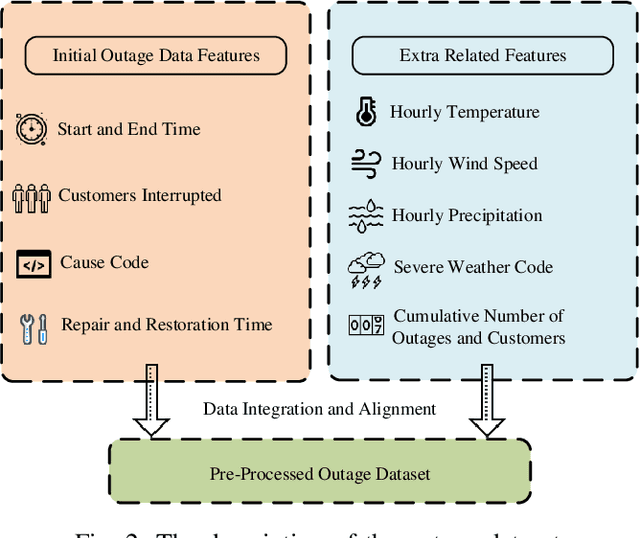
This paper develops a data-driven approach to accurately predict the restoration time of outages under different scales and factors. To achieve the goal, the proposed method consists of three stages. First, given the unprecedented amount of data collected by utilities, a sparse dictionary-based ensemble spectral clustering (SDESC) method is proposed to decompose historical outage datasets, which enjoys good computational efficiency and scalability. Specifically, each outage sample is represented by a linear combination of a small number of selected dictionary samples using a density-based method. Then, the dictionary-based representation is utilized to perform the spectral analysis to group the data samples with similar features into the same subsets. In the second stage, a knowledge-transfer-added restoration time prediction model is trained for each subset by combining weather information and outage-related features. The transfer learning technology is introduced with the aim of dealing with the underestimation problem caused by data imbalance in different subsets, thus improving the model performance. Furthermore, to connect unseen outages with the learned outage subsets, a t-distributed stochastic neighbor embedding-based strategy is applied. The proposed method fully builds on and is also tested on a large real-world outage dataset from a utility provider with a time span of six consecutive years. The numerical results validate that our method has high prediction accuracy while showing good stability against real-world data limitations.
A Two-layer Approach for Estimating Behind-the-Meter PV Generation Using Smart Meter Data
Oct 31, 2021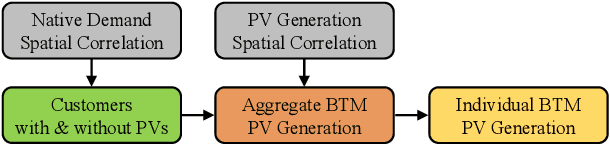

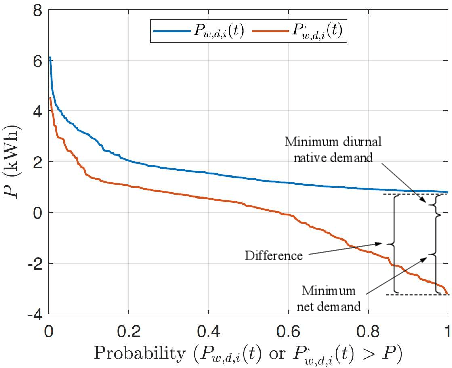
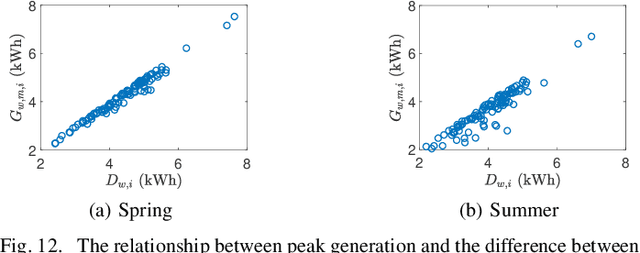
As the cost of the residential solar system decreases, rooftop photovoltaic (PV) has been widely integrated into distribution systems. Most rooftop PV systems are installed behind-the-meter (BTM), i.e., only the net demand is metered, while the native demand and PV generation are not separately recorded. Under this condition, the PV generation and native demand are invisible to utilities, which brings challenges for optimal distribution system operation and expansion. In this paper, we have come up with a novel two-layer approach to disaggregate the unknown PV generation and native demand from the known hourly net demand data recorded by smart meters: 1) At the aggregate level, the proposed approach separates the total PV generation and native demand time series from the total net demand time series for customers with PVs. 2) At the customer level, the separated aggregate-level PV generation is allocated to individual PVs. These two layers leverage the spatial correlations of native demand and PV generation, respectively. One primary advantage of our proposed approach is that it is more independent and practical compared to previous works because it does not require PV array parameters, meteorological data and previously recorded solar power exemplars. We have verified our proposed approach using real native demand and PV generation data.
Synthetic Active Distribution System Generation via Unbalanced Graph Generative Adversarial Network
Aug 02, 2021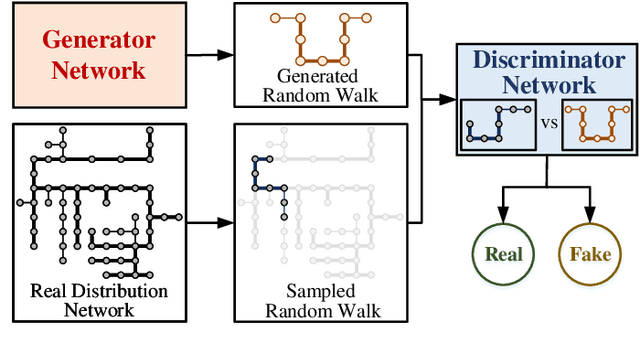
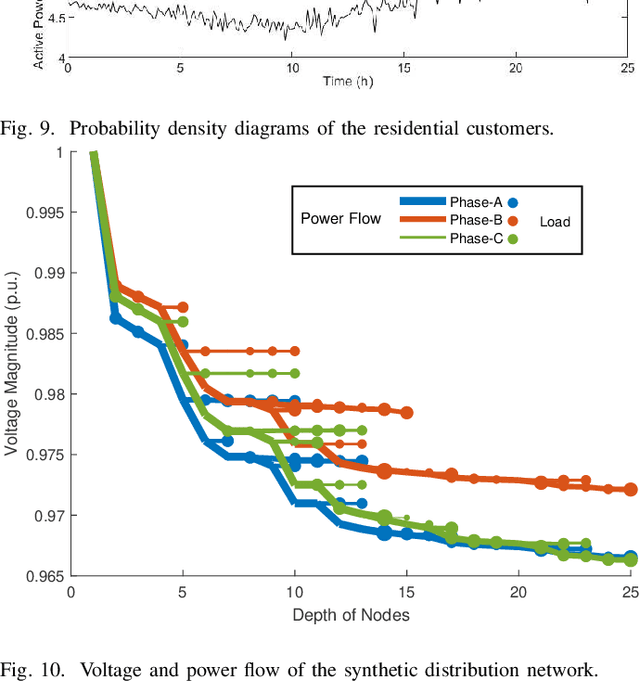
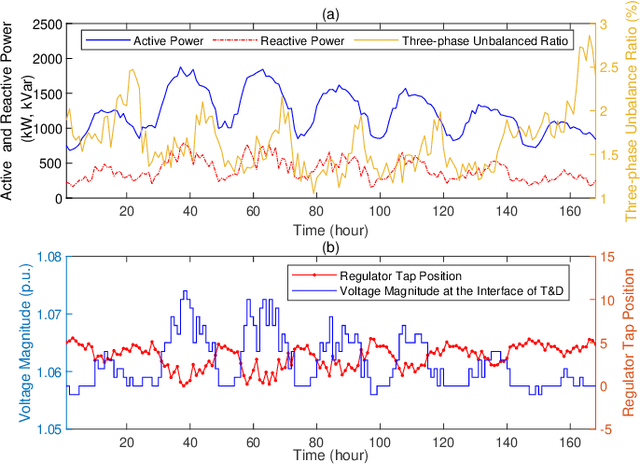
Real active distribution networks with associated smart meter (SM) data are critical for power researchers. However, it is practically difficult for researchers to obtain such comprehensive datasets from utilities due to privacy concerns. To bridge this gap, an implicit generative model with Wasserstein GAN objectives, namely unbalanced graph generative adversarial network (UG-GAN), is designed to generate synthetic three-phase unbalanced active distribution system connectivity. The basic idea is to learn the distribution of random walks both over a real-world system and across each phase of line segments, capturing the underlying local properties of an individual real-world distribution network and generating specific synthetic networks accordingly. Then, to create a comprehensive synthetic test case, a network correction and extension process is proposed to obtain time-series nodal demands and standard distribution grid components with realistic parameters, including distributed energy resources (DERs) and capacity banks. A Midwest distribution system with 1-year SM data has been utilized to validate the performance of our method. Case studies with several power applications demonstrate that synthetic active networks generated by the proposed framework can mimic almost all features of real-world networks while avoiding the disclosure of confidential information.
Mitigating Smart Meter Asynchrony Error Via Multi-Objective Low Rank Matrix Recovery
May 11, 2021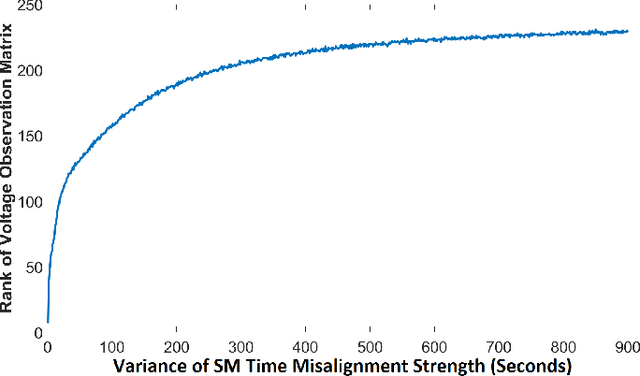
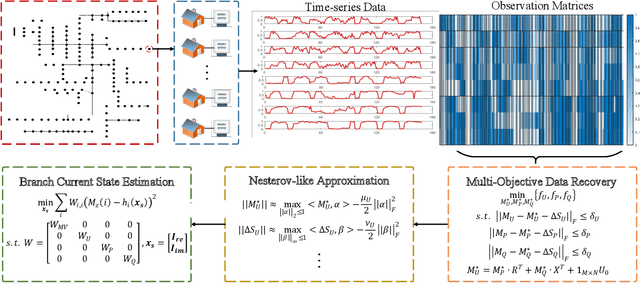
Smart meters (SMs) are being widely deployed by distribution utilities across the U.S. Despite their benefits in real-time monitoring. SMs suffer from certain data quality issues; specifically, unlike phasor measurement units (PMUs) that use GPS for data synchronization, SMs are not perfectly synchronized. The asynchrony error can degrade the monitoring accuracy in distribution networks. To address this challenge, we propose a principal component pursuit (PCP)-based data recovery strategy. Since asynchrony results in a loss of temporal correlation among SMs, the key idea in our solution is to leverage a PCP-based low rank matrix recovery technique to maximize the temporal correlation between multiple data streams obtained from SMs. Further, our approach has a novel multi-objective structure, which allows utilities to precisely refine and recover all SM-measured variables, including voltage and power measurements, while incorporating their inherent dependencies through power flow equations. We have performed numerical experiments using real SM data to demonstrate the effectiveness of the proposed strategy in mitigating the impact of SM asynchrony on distribution grid monitoring.
Distribution Grid Modeling Using Smart Meter Data
Feb 28, 2021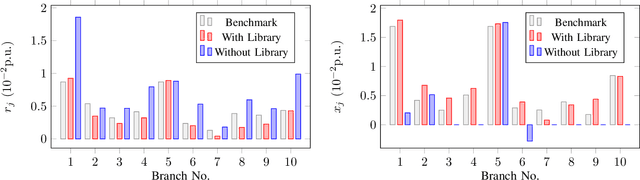
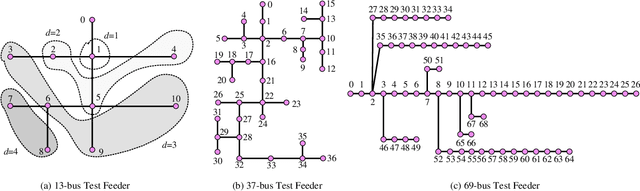
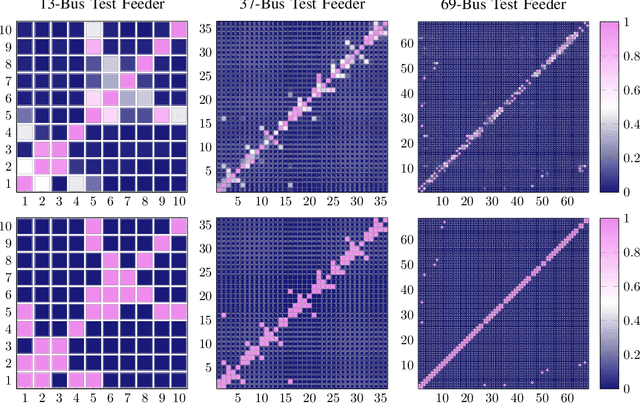
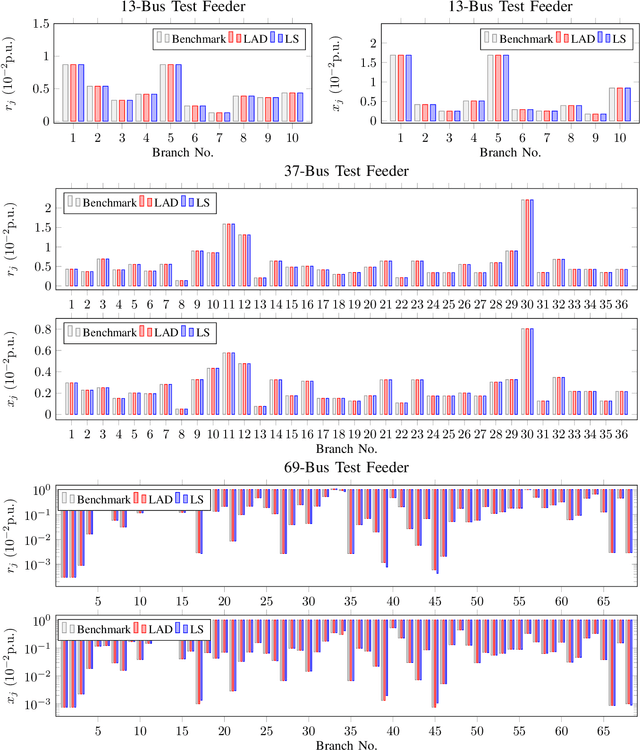
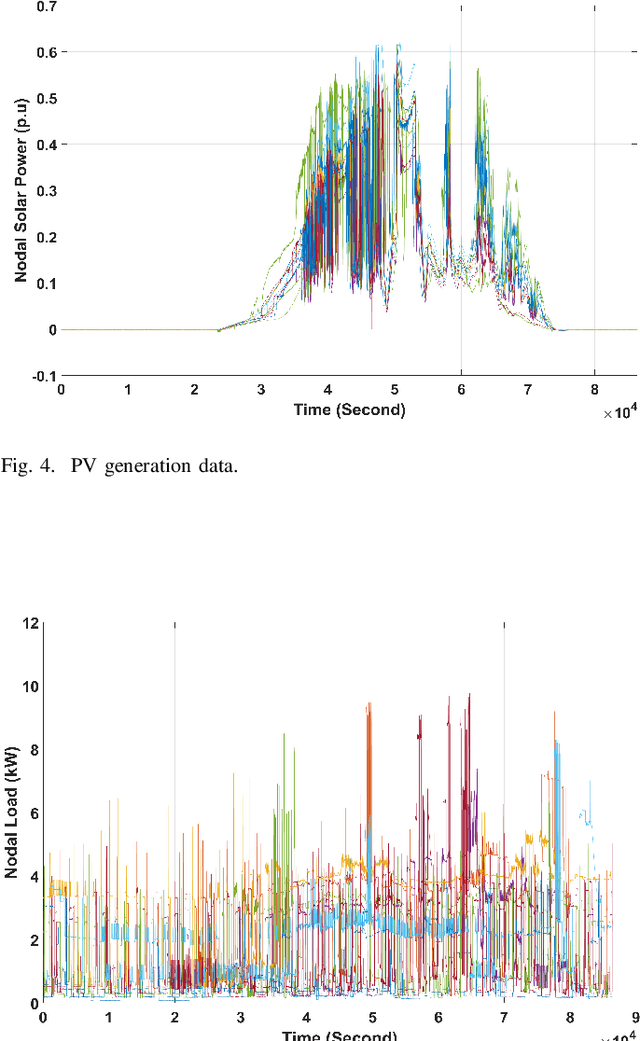
The knowledge of distribution grid models, including topologies and line impedances, is essential to grid monitoring, control and protection. However, this information is often unavailable, incomplete or outdated. The increasing deployment of smart meters (SMs) provides a unique opportunity to address this issue. This paper proposes a two-stage data-driven framework for distribution grid modeling using SM data. In the first stage, we propose to identify the topology via reconstructing a weighted Laplacian matrix of distribution networks, which is mathematically proven to be robust against moderately heterogeneous R/X profiles. In the second stage, we develop nonlinear least absolute deviations (LAD) and least squares (LS) regression models to estimate line impedances of single branches based on a nonlinear inverse power flow, which is then embedded within a bottom-up sweep algorithm to achieve the identification across the network in a branch-wise manner. Because the estimation models are inherently non-convex programs and NP-hard, we specially address their tractable convex relaxations and verify the exactness. In addition, we design a conductor library to significantly narrow down the solution space. Numerical results on the modified IEEE 13-bus, 37-bus and 69-bus test feeders validate the effectiveness of the proposed methods.
A Hierarchical Deep Actor-Critic Learning Method for Joint Distribution System State Estimation
Dec 04, 2020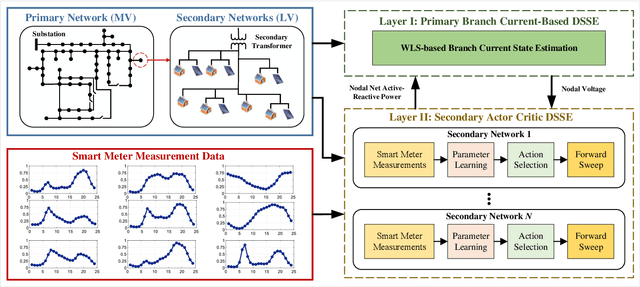
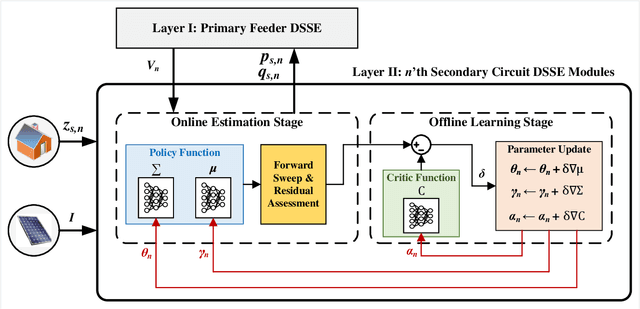
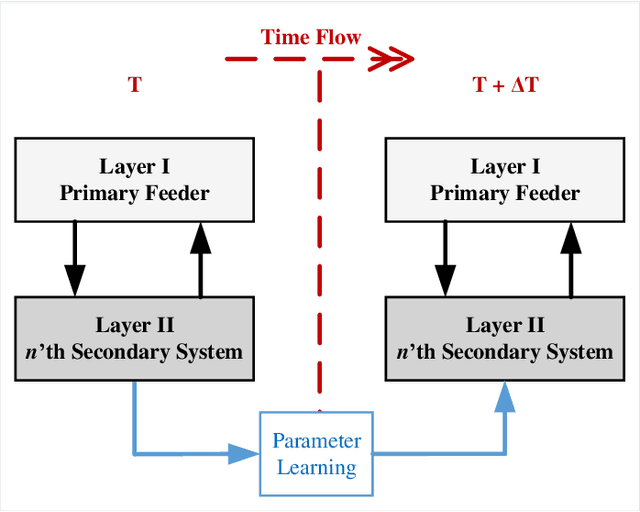
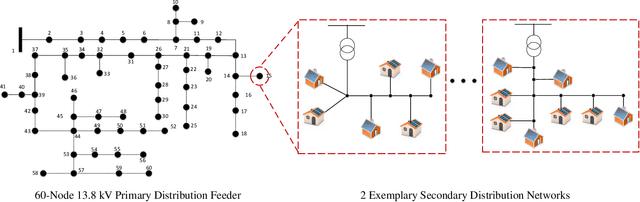
Due to increasing penetration of volatile distributed photovoltaic (PV) resources, real-time monitoring of customers at the grid-edge has become a critical task. However, this requires solving the distribution system state estimation (DSSE) jointly for both primary and secondary levels of distribution grids, which is computationally complex and lacks scalability to large systems. To achieve near real-time solutions for DSSE, we present a novel hierarchical reinforcement learning-aided framework: at the first layer, a weighted least squares (WLS) algorithm solves the DSSE over primary medium-voltage feeders; at the second layer, deep actor-critic (A-C) modules are trained for each secondary transformer using measurement residuals to estimate the states of low-voltage circuits and capture the impact of PVs at the grid-edge. While the A-C parameter learning process takes place offline, the trained A-C modules are deployed online for fast secondary grid state estimation; this is the key factor in scalability and computational efficiency of the framework. To maintain monitoring accuracy, the two levels exchange boundary information with each other at the secondary nodes, including transformer voltages (first layer to second layer) and active/reactive total power injection (second layer to first layer). This interactive information passing strategy results in a closed-loop structure that is able to track optimal solutions at both layers in few iterations. Moreover, our model can handle the topology changes using the Jacobian matrices of the first layer. We have performed numerical experiments using real utility data and feeder models to verify the performance of the proposed framework.
Multi-Source Data-Driven Outage Location in Distribution Systems Using Probabilistic Graph Learning
Dec 04, 2020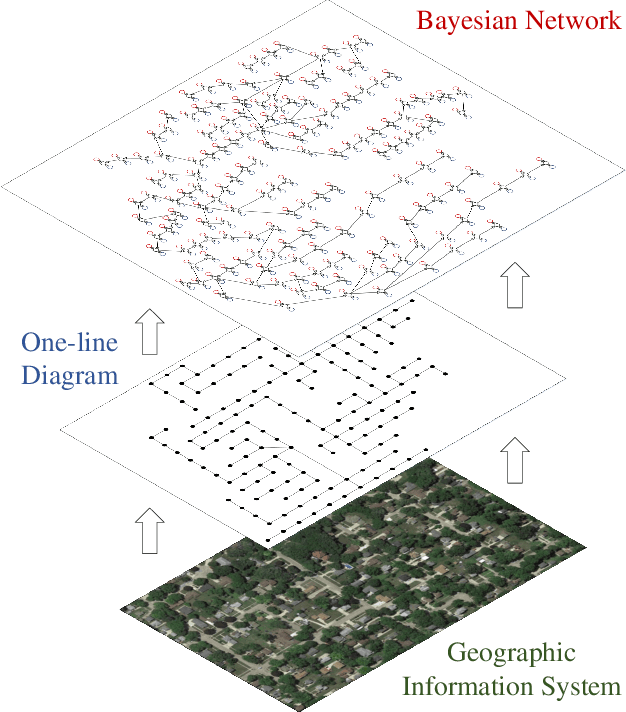
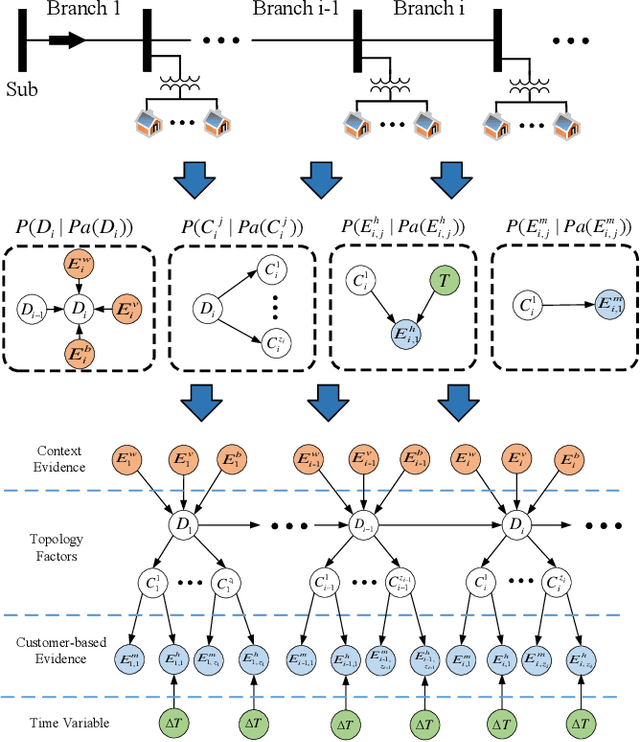
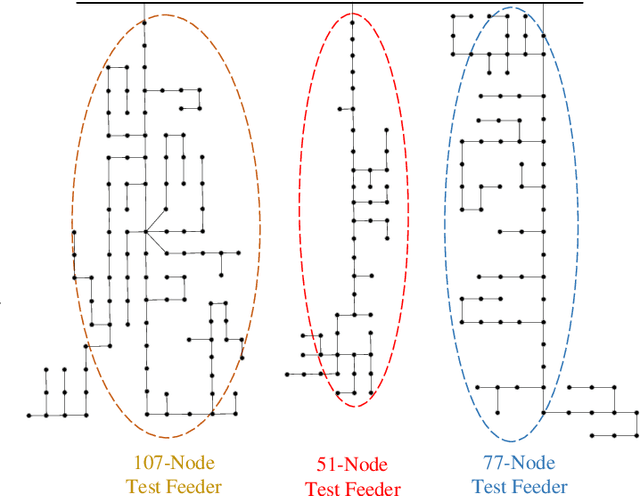
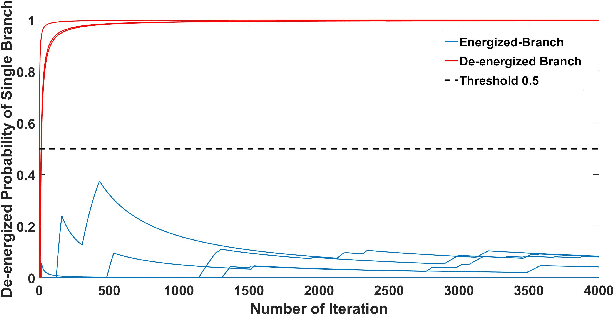
Efficient outage location is critical to enhancing the resilience of power systems. However, accurate outage location requires combining massive evidence received from diverse data sources, including smart meter (SM) signals, customer trouble calls, social media messages, weather data, vegetation information, and physical parameters of the network. This is a computationally complex task due to the high dimensionality of data in distribution grids. In this paper, we propose a multi-source data fusion approach to locate outage events in partially observable distribution systems using Bayesian networks (BNs). A novel aspect of the proposed approach is that it takes multi-source evidence and the complex structure of distribution systems into account using a probabilistic graphical method. This method can radically reduce the computational complexity of outage location inference in high-dimensional spaces. The graphical structure of the proposed BN is established based on the grid's topology and the causal relationship between random variables, such as the states of branches/customers and evidence. Utilizing this graphical model, the locations of outages are obtained by leveraging a Gibbs sampling (GS) method, to infer the probabilities of de-energization for all branches. Compared with commonly-used exact inference methods that have exponential complexity in the size of the BN, GS quantifies the target conditional probability distributions in a timely manner. A case study of several real partially observable systems is presented to validate the method.