 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Error Bound for Quantum Machine Learning in NISQ Era -- A Survey
Sep 11, 2024Despite the mounting anticipation for the quantum revolution, the success of Quantum Machine Learning (QML) in the Noisy Intermediate-Scale Quantum (NISQ) era hinges on a largely unexplored factor: the generalization error bound, a cornerstone of robust and reliable machine learning models. Current QML research, while exploring novel algorithms and applications extensively, is predominantly situated in the context of noise-free, ideal quantum computers. However, Quantum Circuit (QC) operations in NISQ-era devices are susceptible to various noise sources and errors. In this article, we conduct a Systematic Mapping Study (SMS) to explore the state-of-the-art generalization bound for supervised QML in NISQ-era and analyze the latest practices in the field. Our study systematically summarizes the existing computational platforms with quantum hardware, datasets, optimization techniques, and the common properties of the bounds found in the literature. We further present the performance accuracy of various approaches in classical benchmark datasets like the MNIST and IRIS datasets. The SMS also highlights the limitations and challenges in QML in the NISQ era and discusses future research directions to advance the field. Using a detailed Boolean operators query in five reliable indexers, we collected 544 papers and filtered them to a small set of 37 relevant articles. This filtration was done following the best practice of SMS with well-defined research questions and inclusion and exclusion criteria.
Efficacy of ByteT5 in Multilingual Translation of Biblical Texts for Underrepresented Languages
May 22, 2024

This study presents the development and evaluation of a ByteT5-based multilingual translation model tailored for translating the Bible into underrepresented languages. Utilizing the comprehensive Johns Hopkins University Bible Corpus, we trained the model to capture the intricate nuances of character-based and morphologically rich languages. Our results, measured by the BLEU score and supplemented with sample translations, suggest the model can improve accessibility to sacred texts. It effectively handles the distinctive biblical lexicon and structure, thus bridging the linguistic divide. The study also discusses the model's limitations and suggests pathways for future enhancements, focusing on expanding access to sacred literature across linguistic boundaries.
Is ReLU Adversarially Robust?
May 06, 2024



The efficacy of deep learning models has been called into question by the presence of adversarial examples. Addressing the vulnerability of deep learning models to adversarial examples is crucial for ensuring their continued development and deployment. In this work, we focus on the role of rectified linear unit (ReLU) activation functions in the generation of adversarial examples. ReLU functions are commonly used in deep learning models because they facilitate the training process. However, our empirical analysis demonstrates that ReLU functions are not robust against adversarial examples. We propose a modified version of the ReLU function, which improves robustness against adversarial examples. Our results are supported by an experiment, which confirms the effectiveness of our proposed modification. Additionally, we demonstrate that applying adversarial training to our customized model further enhances its robustness compared to a general model.
On Adversarial Examples for Text Classification by Perturbing Latent Representations
May 06, 2024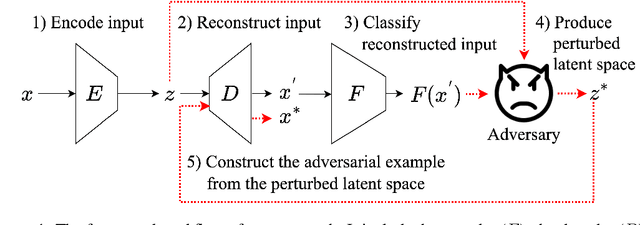


Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.