 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLR-WA: Online Weighted Average Linear Regression in Multivariate Data Streams
Dec 16, 2025
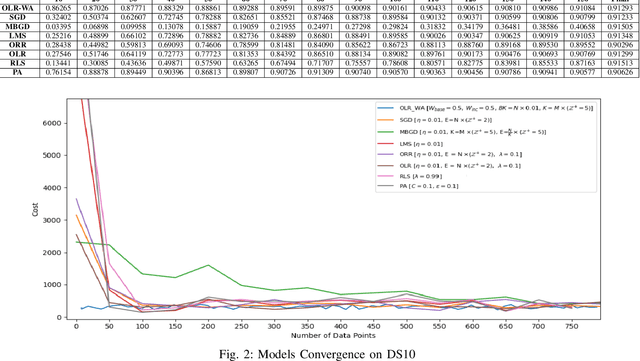
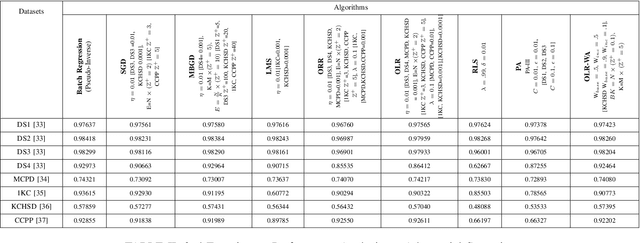
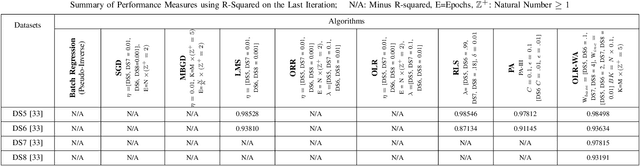
Online learning updates models incrementally with new data, avoiding large storage requirements and costly model recalculations. In this paper, we introduce "OLR-WA; OnLine Regression with Weighted Average", a novel and versatile multivariate online linear regression model. We also investigate scenarios involving drift, where the underlying patterns in the data evolve over time, conduct convergence analysis, and compare our approach with existing online regression models. The results of OLR-WA demonstrate its ability to achieve performance comparable to the batch regression, while also showcasing comparable or superior performance when compared with other state-of-the-art online models, thus establishing its effectiveness. Moreover, OLR-WA exhibits exceptional performance in terms of rapid convergence, surpassing other online models with consistently achieving high r2 values as a performance measure from the first iteration to the last iteration, even when initialized with minimal amount of data points, as little as 1% to 10% of the total data points. In addition to its ability to handle time-based (temporal drift) scenarios, remarkably, OLR-WA stands out as the only model capable of effectively managing confidence-based challenging scenarios. It achieves this by adopting a conservative approach in its updates, giving priority to older data points with higher confidence levels. In summary, OLR-WA's performance further solidifies its versatility and utility across different contexts, making it a valuable solution for online linear regression tasks.
Generalization Error Bound for Quantum Machine Learning in NISQ Era -- A Survey
Sep 11, 2024Despite the mounting anticipation for the quantum revolution, the success of Quantum Machine Learning (QML) in the Noisy Intermediate-Scale Quantum (NISQ) era hinges on a largely unexplored factor: the generalization error bound, a cornerstone of robust and reliable machine learning models. Current QML research, while exploring novel algorithms and applications extensively, is predominantly situated in the context of noise-free, ideal quantum computers. However, Quantum Circuit (QC) operations in NISQ-era devices are susceptible to various noise sources and errors. In this article, we conduct a Systematic Mapping Study (SMS) to explore the state-of-the-art generalization bound for supervised QML in NISQ-era and analyze the latest practices in the field. Our study systematically summarizes the existing computational platforms with quantum hardware, datasets, optimization techniques, and the common properties of the bounds found in the literature. We further present the performance accuracy of various approaches in classical benchmark datasets like the MNIST and IRIS datasets. The SMS also highlights the limitations and challenges in QML in the NISQ era and discusses future research directions to advance the field. Using a detailed Boolean operators query in five reliable indexers, we collected 544 papers and filtered them to a small set of 37 relevant articles. This filtration was done following the best practice of SMS with well-defined research questions and inclusion and exclusion criteria.
Embedding Data within Knowledge Spaces
Feb 04, 2009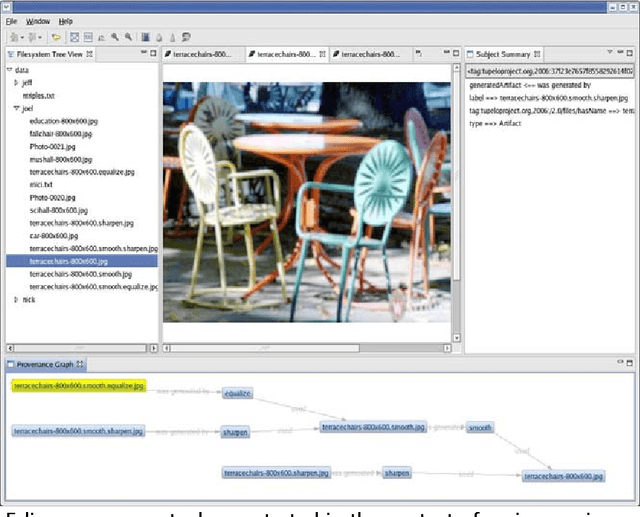
The promise of e-Science will only be realized when data is discoverable, accessible, and comprehensible within distributed teams, across disciplines, and over the long-term--without reliance on out-of-band (non-digital) means. We have developed the open-source Tupelo semantic content management framework and are employing it to manage a wide range of e-Science entities (including data, documents, workflows, people, and projects) and a broad range of metadata (including provenance, social networks, geospatial relationships, temporal relations, and domain descriptions). Tupelo couples the use of global identifiers and resource description framework (RDF) statements with an aggregatable content repository model to provide a unified space for securely managing distributed heterogeneous content and relationships.