 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMC: Structure-Enhanced Mixture-of-Experts Contrastive Learning for Ultrasound Standard Plane Recognition
Nov 16, 2025Ultrasound standard plane recognition is essential for clinical tasks such as disease screening, organ evaluation, and biometric measurement. However, existing methods fail to effectively exploit shallow structural information and struggle to capture fine-grained semantic differences through contrastive samples generated by image augmentations, ultimately resulting in suboptimal recognition of both structural and discriminative details in ultrasound standard planes. To address these issues, we propose SEMC, a novel Structure-Enhanced Mixture-of-Experts Contrastive learning framework that combines structure-aware feature fusion with expert-guided contrastive learning. Specifically, we first introduce a novel Semantic-Structure Fusion Module (SSFM) to exploit multi-scale structural information and enhance the model's ability to perceive fine-grained structural details by effectively aligning shallow and deep features. Then, a novel Mixture-of-Experts Contrastive Recognition Module (MCRM) is designed to perform hierarchical contrastive learning and classification across multi-level features using a mixture-of-experts (MoE) mechanism, further improving class separability and recognition performance. More importantly, we also curate a large-scale and meticulously annotated liver ultrasound dataset containing six standard planes. Extensive experimental results on our in-house dataset and two public datasets demonstrate that SEMC outperforms recent state-of-the-art methods across various metrics.
ILNet: Trajectory Prediction with Inverse Learning Attention for Enhancing Intention Capture
Jul 09, 2025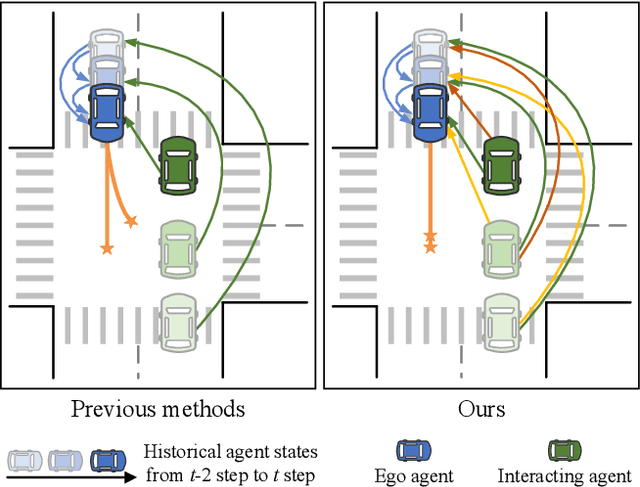
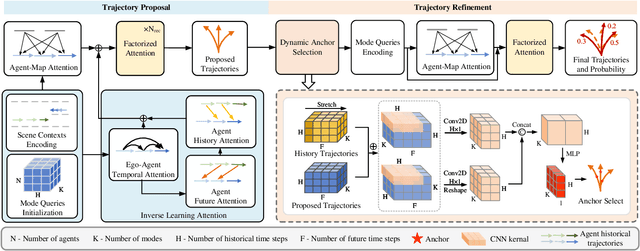
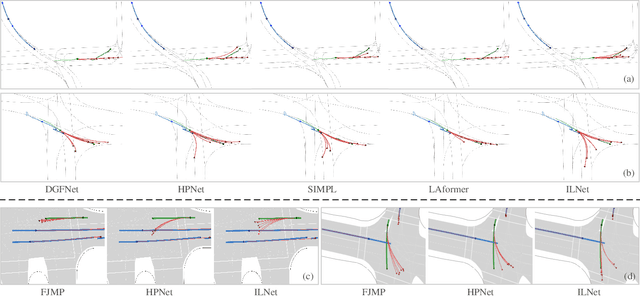
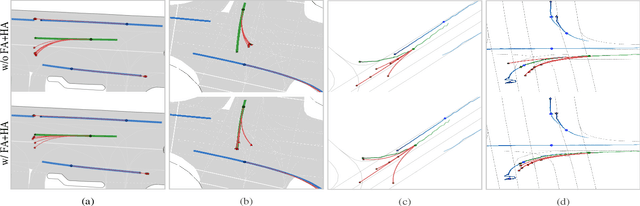
Trajectory prediction for multi-agent interaction scenarios is a crucial challenge. Most advanced methods model agent interactions by efficiently factorized attention based on the temporal and agent axes. However, this static and foward modeling lacks explicit interactive spatio-temporal coordination, capturing only obvious and immediate behavioral intentions. Alternatively, the modern trajectory prediction framework refines the successive predictions by a fixed-anchor selection strategy, which is difficult to adapt in different future environments. It is acknowledged that human drivers dynamically adjust initial driving decisions based on further assumptions about the intentions of surrounding vehicles. Motivated by human driving behaviors, this paper proposes ILNet, a multi-agent trajectory prediction method with Inverse Learning (IL) attention and Dynamic Anchor Selection (DAS) module. IL Attention employs an inverse learning paradigm to model interactions at neighboring moments, introducing proposed intentions to dynamically encode the spatio-temporal coordination of interactions, thereby enhancing the model's ability to capture complex interaction patterns. Then, the learnable DAS module is proposed to extract multiple trajectory change keypoints as anchors in parallel with almost no increase in parameters. Experimental results show that the ILNet achieves state-of-the-art performance on the INTERACTION and Argoverse motion forecasting datasets. Particularly, in challenged interaction scenarios, ILNet achieves higher accuracy and more multimodal distributions of trajectories over fewer parameters. Our codes are available at https://github.com/mjZeng11/ILNet.
MESC-3D:Mining Effective Semantic Cues for 3D Reconstruction from a Single Image
Feb 28, 2025Reconstructing 3D shapes from a single image plays an important role in computer vision. Many methods have been proposed and achieve impressive performance. However, existing methods mainly focus on extracting semantic information from images and then simply concatenating it with 3D point clouds without further exploring the concatenated semantics. As a result, these entangled semantic features significantly hinder the reconstruction performance. In this paper, we propose a novel single-image 3D reconstruction method called Mining Effective Semantic Cues for 3D Reconstruction from a Single Image (MESC-3D), which can actively mine effective semantic cues from entangled features. Specifically, we design an Effective Semantic Mining Module to establish connections between point clouds and image semantic attributes, enabling the point clouds to autonomously select the necessary information. Furthermore, to address the potential insufficiencies in semantic information from a single image, such as occlusions, inspired by the human ability to represent 3D objects using prior knowledge drawn from daily experiences, we introduce a 3D Semantic Prior Learning Module. This module incorporates semantic understanding of spatial structures, enabling the model to interpret and reconstruct 3D objects with greater accuracy and realism, closely mirroring human perception of complex 3D environments. Extensive evaluations show that our method achieves significant improvements in reconstruction quality and robustness compared to prior works. Additionally, further experiments validate the strong generalization capabilities and excels in zero-shot preformance on unseen classes. Code is available at https://github.com/QINGQINGLE/MESC-3D.
C2PD: Continuity-Constrained Pixelwise Deformation for Guided Depth Super-Resolution
Jan 13, 2025Guided depth super-resolution (GDSR) has demonstrated impressive performance across a wide range of domains, with numerous methods being proposed. However, existing methods often treat depth maps as images, where shading values are computed discretely, making them struggle to effectively restore the continuity inherent in the depth map. In this paper, we propose a novel approach that maximizes the utilization of spatial characteristics in depth, coupled with human abstract perception of real-world substance, by transforming the GDSR issue into deformation of a roughcast with ideal plasticity, which can be deformed by force like a continuous object. Specifically, we firstly designed a cross-modal operation, Continuity-constrained Asymmetrical Pixelwise Operation (CAPO), which can mimic the process of deforming an isovolumetrically flexible object through external forces. Utilizing CAPO as the fundamental component, we develop the Pixelwise Cross Gradient Deformation (PCGD), which is capable of emulating operations on ideal plastic objects (without volume constraint). Notably, our approach demonstrates state-of-the-art performance across four widely adopted benchmarks for GDSR, with significant advantages in large-scale tasks and generalizability.
SGTC: Semantic-Guided Triplet Co-training for Sparsely Annotated Semi-Supervised Medical Image Segmentation
Dec 20, 2024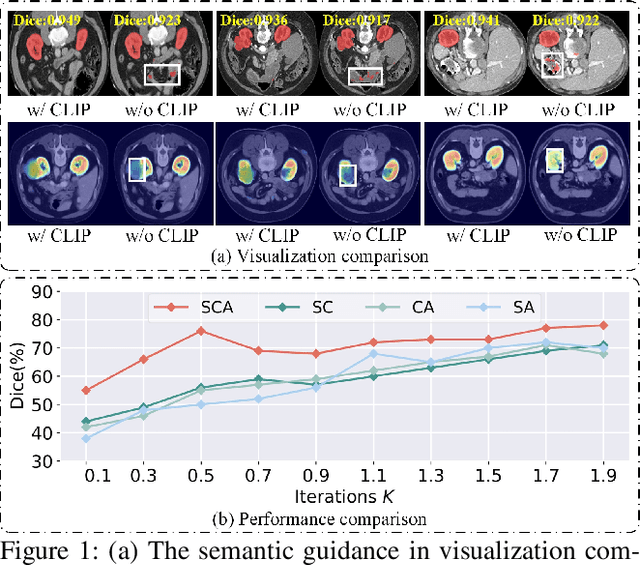

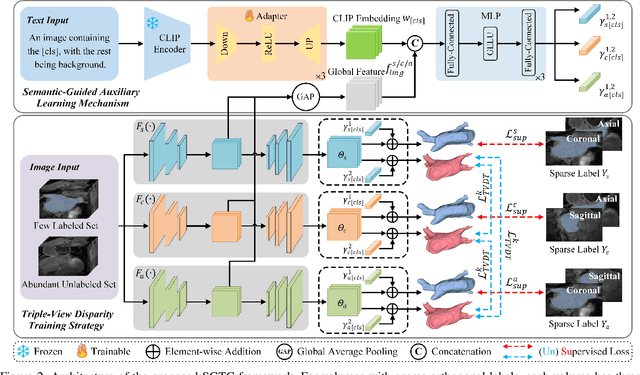

Although semi-supervised learning has made significant advances in the field of medical image segmentation, fully annotating a volumetric sample slice by slice remains a costly and time-consuming task. Even worse, most of the existing approaches pay much attention to image-level information and ignore semantic features, resulting in the inability to perceive weak boundaries. To address these issues, we propose a novel Semantic-Guided Triplet Co-training (SGTC) framework, which achieves high-end medical image segmentation by only annotating three orthogonal slices of a few volumetric samples, significantly alleviating the burden of radiologists. Our method consist of two main components. Specifically, to enable semantic-aware, fine-granular segmentation and enhance the quality of pseudo-labels, a novel semantic-guided auxiliary learning mechanism is proposed based on the pretrained CLIP. In addition, focusing on a more challenging but clinically realistic scenario, a new triple-view disparity training strategy is proposed, which uses sparse annotations (i.e., only three labeled slices of a few volumes) to perform co-training between three sub-networks, significantly improving the robustness. Extensive experiments on three public medical datasets demonstrate that our method outperforms most state-of-the-art semi-supervised counterparts under sparse annotation settings. The source code is available at https://github.com/xmeimeimei/SGTC.
BSAFusion: A Bidirectional Stepwise Feature Alignment Network for Unaligned Medical Image Fusion
Dec 11, 2024



If unaligned multimodal medical images can be simultaneously aligned and fused using a single-stage approach within a unified processing framework, it will not only achieve mutual promotion of dual tasks but also help reduce the complexity of the model. However, the design of this model faces the challenge of incompatible requirements for feature fusion and alignment; specifically, feature alignment requires consistency among corresponding features, whereas feature fusion requires the features to be complementary to each other. To address this challenge, this paper proposes an unaligned medical image fusion method called Bidirectional Stepwise Feature Alignment and Fusion (BSFA-F) strategy. To reduce the negative impact of modality differences on cross-modal feature matching, we incorporate the Modal Discrepancy-Free Feature Representation (MDF-FR) method into BSFA-F. MDF-FR utilizes a Modality Feature Representation Head (MFRH) to integrate the global information of the input image. By injecting the information contained in MFRH of the current image into other modality images, it effectively reduces the impact of modality differences on feature alignment while preserving the complementary information carried by different images. In terms of feature alignment, BSFA-F employs a bidirectional stepwise alignment deformation field prediction strategy based on the path independence of vector displacement between two points. This strategy solves the problem of large spans and inaccurate deformation field prediction in single-step alignment. Finally, Multi-Modal Feature Fusion block achieves the fusion of aligned features. The experimental results across multiple datasets demonstrate the effectiveness of our method. The source code is available at https://github.com/slrl123/BSAFusion.
PP-SSL : Priority-Perception Self-Supervised Learning for Fine-Grained Recognition
Nov 28, 2024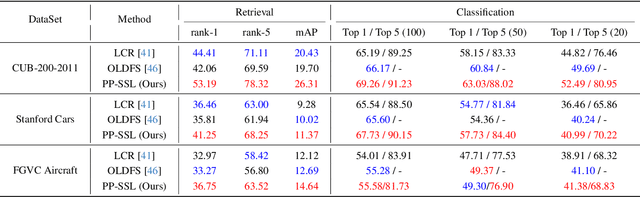
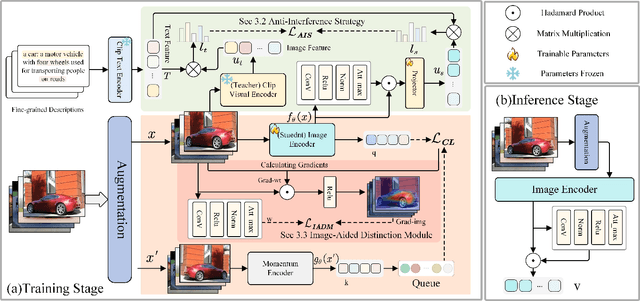
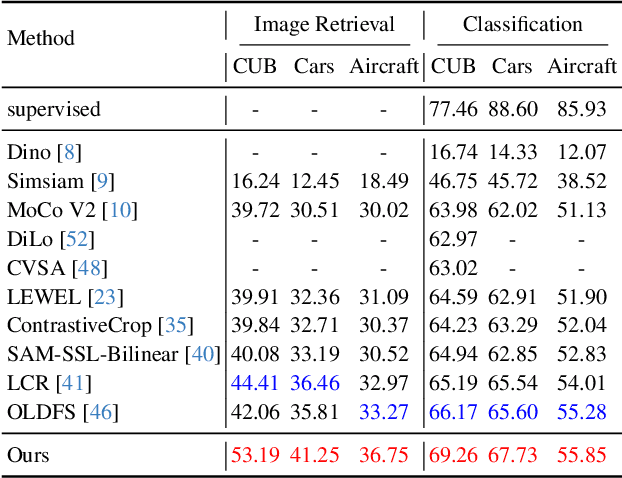

Self-supervised learning is emerging in fine-grained visual recognition with promising results. However, existing self-supervised learning methods are often susceptible to irrelevant patterns in self-supervised tasks and lack the capability to represent the subtle differences inherent in fine-grained visual recognition (FGVR), resulting in generally poorer performance. To address this, we propose a novel Priority-Perception Self-Supervised Learning framework, denoted as PP-SSL, which can effectively filter out irrelevant feature interference and extract more subtle discriminative features throughout the training process. Specifically, it composes of two main parts: the Anti-Interference Strategy (AIS) and the Image-Aided Distinction Module (IADM). In AIS, a fine-grained textual description corpus is established, and a knowledge distillation strategy is devised to guide the model in eliminating irrelevant features while enhancing the learning of more discriminative and high-quality features. IADM reveals that extracting GradCAM from the original image effectively reveals subtle differences between fine-grained categories. Compared to features extracted from intermediate or output layers, the original image retains more detail, allowing for a deeper exploration of the subtle distinctions among fine-grained classes. Extensive experimental results indicate that the PP-SSL significantly outperforms existing methods across various datasets, highlighting its effectiveness in fine-grained recognition tasks. Our code will be made publicly available upon publication.
ZipGait: Bridging Skeleton and Silhouette with Diffusion Model for Advancing Gait Recognition
Aug 22, 2024Current gait recognition research predominantly focuses on extracting appearance features effectively, but the performance is severely compromised by the vulnerability of silhouettes under unconstrained scenes. Consequently, numerous studies have explored how to harness information from various models, particularly by sufficiently utilizing the intrinsic information of skeleton sequences. While these model-based methods have achieved significant performance, there is still a huge gap compared to appearance-based methods, which implies the potential value of bridging silhouettes and skeletons. In this work, we make the first attempt to reconstruct dense body shapes from discrete skeleton distributions via the diffusion model, demonstrating a new approach that connects cross-modal features rather than focusing solely on intrinsic features to improve model-based methods. To realize this idea, we propose a novel gait diffusion model named DiffGait, which has been designed with four specific adaptations suitable for gait recognition. Furthermore, to effectively utilize the reconstructed silhouettes and skeletons, we introduce Perception Gait Integration (PGI) to integrate different gait features through a two-stage process. Incorporating those modifications leads to an efficient model-based gait recognition framework called ZipGait. Through extensive experiments on four public benchmarks, ZipGait demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both cross-domain and intra-domain settings, while achieving significant plug-and-play performance improvements.
Meta-heuristic Optimizer Inspired by the Philosophy of Yi Jing
Aug 10, 2024



Drawing inspiration from the philosophy of Yi Jing, the Yin-Yang pair optimization (YYPO) algorithm has been shown to achieve competitive performance in single objective optimizations, in addition to the advantage of low time complexity when compared to other population-based meta-heuristics. Building upon a reversal concept in Yi Jing, we propose the novel Yi optimization (YI) algorithm. Specifically, we enhance the Yin-Yang pair in YYPO with a proposed Yi-point, in which we use Cauchy flight to update the solution, by implementing both the harmony and reversal concept of Yi Jing. The proposed Yi-point balances both the effort of exploration and exploitation in the optimization process. To examine YI, we use the IEEE CEC 2017 benchmarks and compare YI against the dynamical YYPO, CV1.0 optimizer, and four classical optimizers, i.e., the differential evolution, the genetic algorithm, the particle swarm optimization, and the simulated annealing. According to the experimental results, YI shows highly competitive performance while keeping the low time complexity. The results of this work have implications for enhancing a meta-heuristic optimizer using the philosophy of Yi Jing. While this work implements only certain aspects of Yi Jing, we envisage enhanced performance by incorporating other aspects.
Exploring Cross-Domain Few-Shot Classification via Frequency-Aware Prompting
Jun 24, 2024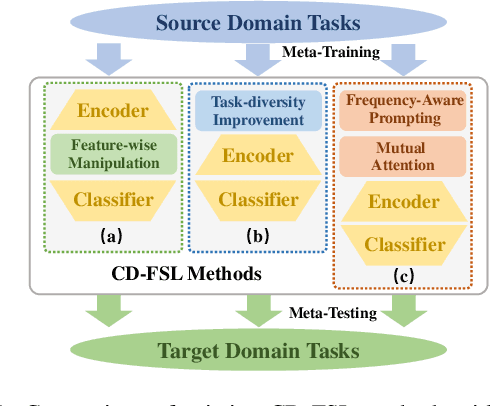
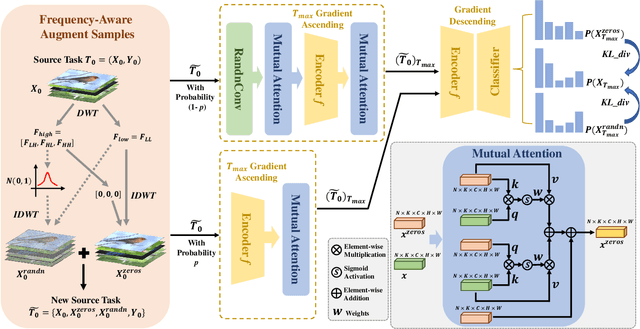
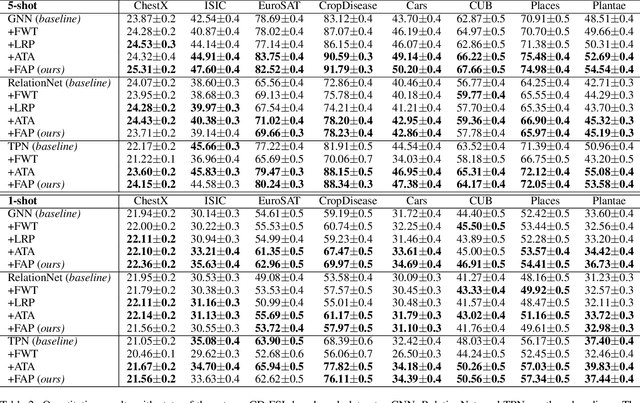
Cross-Domain Few-Shot Learning has witnessed great stride with the development of meta-learning. However, most existing methods pay more attention to learning domain-adaptive inductive bias (meta-knowledge) through feature-wise manipulation or task diversity improvement while neglecting the phenomenon that deep networks tend to rely more on high-frequency cues to make the classification decision, which thus degenerates the robustness of learned inductive bias since high-frequency information is vulnerable and easy to be disturbed by noisy information. Hence in this paper, we make one of the first attempts to propose a Frequency-Aware Prompting method with mutual attention for Cross-Domain Few-Shot classification, which can let networks simulate the human visual perception of selecting different frequency cues when facing new recognition tasks. Specifically, a frequency-aware prompting mechanism is first proposed, in which high-frequency components of the decomposed source image are switched either with normal distribution sampling or zeroing to get frequency-aware augment samples. Then, a mutual attention module is designed to learn generalizable inductive bias under CD-FSL settings. More importantly, the proposed method is a plug-and-play module that can be directly applied to most off-the-shelf CD-FLS methods. Experimental results on CD-FSL benchmarks demonstrate the effectiveness of our proposed method as well as robustly improve the performance of existing CD-FLS methods. Resources at https://github.com/tinkez/FAP_CDFSC.