 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESC-3D:Mining Effective Semantic Cues for 3D Reconstruction from a Single Image
Feb 28, 2025Reconstructing 3D shapes from a single image plays an important role in computer vision. Many methods have been proposed and achieve impressive performance. However, existing methods mainly focus on extracting semantic information from images and then simply concatenating it with 3D point clouds without further exploring the concatenated semantics. As a result, these entangled semantic features significantly hinder the reconstruction performance. In this paper, we propose a novel single-image 3D reconstruction method called Mining Effective Semantic Cues for 3D Reconstruction from a Single Image (MESC-3D), which can actively mine effective semantic cues from entangled features. Specifically, we design an Effective Semantic Mining Module to establish connections between point clouds and image semantic attributes, enabling the point clouds to autonomously select the necessary information. Furthermore, to address the potential insufficiencies in semantic information from a single image, such as occlusions, inspired by the human ability to represent 3D objects using prior knowledge drawn from daily experiences, we introduce a 3D Semantic Prior Learning Module. This module incorporates semantic understanding of spatial structures, enabling the model to interpret and reconstruct 3D objects with greater accuracy and realism, closely mirroring human perception of complex 3D environments. Extensive evaluations show that our method achieves significant improvements in reconstruction quality and robustness compared to prior works. Additionally, further experiments validate the strong generalization capabilities and excels in zero-shot preformance on unseen classes. Code is available at https://github.com/QINGQINGLE/MESC-3D.
Trajectory-User Linking via Hierarchical Spatio-Temporal Attention Networks
Feb 11, 2023



Trajectory-User Linking (TUL) is crucial for human mobility modeling by linking different trajectories to users with the exploration of complex mobility patterns. Existing works mainly rely on the recurrent neural framework to encode the temporal dependencies in trajectories, have fall short in capturing spatial-temporal global context for TUL prediction. To fill this gap, this work presents a new hierarchical spatio-temporal attention neural network, called AttnTUL, to jointly encode the local trajectory transitional patterns and global spatial dependencies for TUL. Specifically, our first model component is built over the graph neural architecture to preserve the local and global context and enhance the representation paradigm of geographical regions and user trajectories. Additionally, a hierarchically structured attention network is designed to simultaneously encode the intra-trajectory and inter-trajectory dependencies, with the integration of the temporal attention mechanism and global elastic attentional encoder. Extensive experiments demonstrate the superiority of our AttnTUL method as compared to state-of-the-art baselines on various trajectory datasets. The source code of our model is available at \url{https://anonymous.4open.science/r/Attn_TUL}.
Mutual Distillation Learning Network for Trajectory-User Linking
May 08, 2022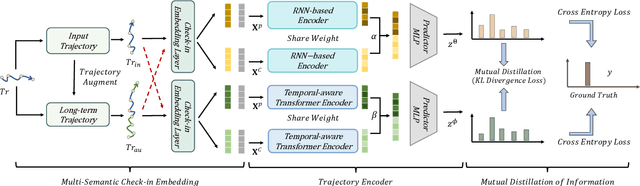
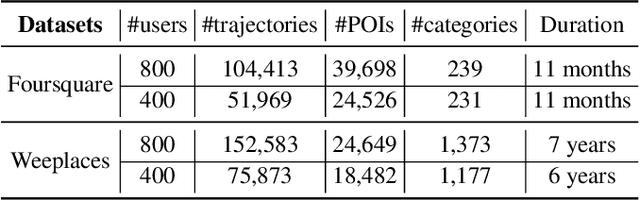
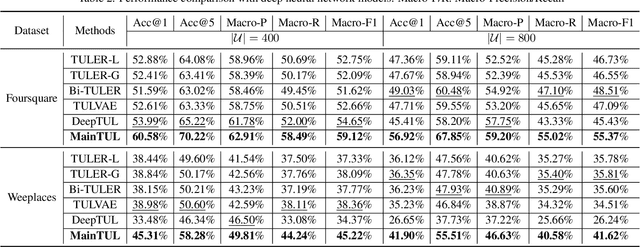
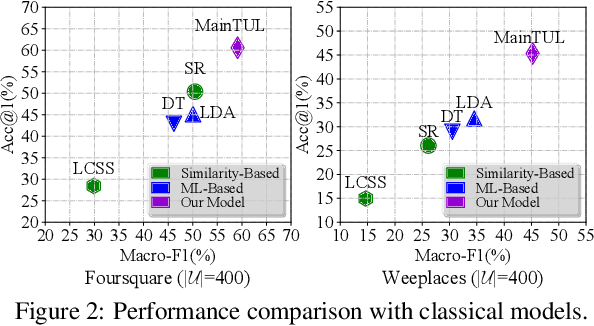
Trajectory-User Linking (TUL), which links trajectories to users who generate them, has been a challenging problem due to the sparsity in check-in mobility data. Existing methods ignore the utilization of historical data or rich contextual features in check-in data, resulting in poor performance for TUL task. In this paper, we propose a novel Mutual distillation learning network to solve the TUL problem for sparse check-in mobility data, named MainTUL. Specifically, MainTUL is composed of a Recurrent Neural Network (RNN) trajectory encoder that models sequential patterns of input trajectory and a temporal-aware Transformer trajectory encoder that captures long-term time dependencies for the corresponding augmented historical trajectories. Then, the knowledge learned on historical trajectories is transferred between the two trajectory encoders to guide the learning of both encoders to achieve mutual distillation of information. Experimental results on two real-world check-in mobility datasets demonstrate the superiority of MainTUL against state-of-the-art baselines. The source code of our model is available at https://github.com/Onedean/MainTUL.