 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Prompt Learning for Image- and Text-Based Person Re-Identification
Nov 17, 2025



Person re-identification (ReID) aims to retrieve target pedestrian images given either visual queries (image-to-image, I2I) or textual descriptions (text-to-image, T2I). Although both tasks share a common retrieval objective, they pose distinct challenges: I2I emphasizes discriminative identity learning, while T2I requires accurate cross-modal semantic alignment. Existing methods often treat these tasks separately, which may lead to representation entanglement and suboptimal performance. To address this, we propose a unified framework named Hierarchical Prompt Learning (HPL), which leverages task-aware prompt modeling to jointly optimize both tasks. Specifically, we first introduce a Task-Routed Transformer, which incorporates dual classification tokens into a shared visual encoder to route features for I2I and T2I branches respectively. On top of this, we develop a hierarchical prompt generation scheme that integrates identity-level learnable tokens with instance-level pseudo-text tokens. These pseudo-tokens are derived from image or text features via modality-specific inversion networks, injecting fine-grained, instance-specific semantics into the prompts. Furthermore, we propose a Cross-Modal Prompt Regularization strategy to enforce semantic alignment in the prompt token space, ensuring that pseudo-prompts preserve source-modality characteristics while enhancing cross-modal transferability. Extensive experiments on multiple ReID benchmarks validate the effectiveness of our method, achieving state-of-the-art performance on both I2I and T2I tasks.
Dual-Granularity Cross-Modal Identity Association for Weakly-Supervised Text-to-Person Image Matching
Jul 09, 2025Weakly supervised text-to-person image matching, as a crucial approach to reducing models' reliance on large-scale manually labeled samples, holds significant research value. However, existing methods struggle to predict complex one-to-many identity relationships, severely limiting performance improvements. To address this challenge, we propose a local-and-global dual-granularity identity association mechanism. Specifically, at the local level, we explicitly establish cross-modal identity relationships within a batch, reinforcing identity constraints across different modalities and enabling the model to better capture subtle differences and correlations. At the global level, we construct a dynamic cross-modal identity association network with the visual modality as the anchor and introduce a confidence-based dynamic adjustment mechanism, effectively enhancing the model's ability to identify weakly associated samples while improving overall sensitivity. Additionally, we propose an information-asymmetric sample pair construction method combined with consistency learning to tackle hard sample mining and enhance model robustness. Experimental results demonstrate that the proposed method substantially boosts cross-modal matching accuracy, providing an efficient and practical solution for text-to-person image matching.
RankPO: Preference Optimization for Job-Talent Matching
Mar 13, 2025Matching job descriptions (JDs) with suitable talent requires models capable of understanding not only textual similarities between JDs and candidate resumes but also contextual factors such as geographical location and academic seniority. To address this challenge, we propose a two-stage training framework for large language models (LLMs). In the first stage, a contrastive learning approach is used to train the model on a dataset constructed from real-world matching rules, such as geographical alignment and research area overlap. While effective, this model primarily learns patterns that defined by the matching rules. In the second stage, we introduce a novel preference-based fine-tuning method inspired by Direct Preference Optimization (DPO), termed Rank Preference Optimization (RankPO), to align the model with AI-curated pairwise preferences emphasizing textual understanding. Our experiments show that while the first-stage model achieves strong performance on rule-based data (nDCG@20 = 0.706), it lacks robust textual understanding (alignment with AI annotations = 0.46). By fine-tuning with RankPO, we achieve a balanced model that retains relatively good performance in the original tasks while significantly improving the alignment with AI preferences. The code and data are available at https://github.com/yflyzhang/RankPO.
BSAFusion: A Bidirectional Stepwise Feature Alignment Network for Unaligned Medical Image Fusion
Dec 11, 2024



If unaligned multimodal medical images can be simultaneously aligned and fused using a single-stage approach within a unified processing framework, it will not only achieve mutual promotion of dual tasks but also help reduce the complexity of the model. However, the design of this model faces the challenge of incompatible requirements for feature fusion and alignment; specifically, feature alignment requires consistency among corresponding features, whereas feature fusion requires the features to be complementary to each other. To address this challenge, this paper proposes an unaligned medical image fusion method called Bidirectional Stepwise Feature Alignment and Fusion (BSFA-F) strategy. To reduce the negative impact of modality differences on cross-modal feature matching, we incorporate the Modal Discrepancy-Free Feature Representation (MDF-FR) method into BSFA-F. MDF-FR utilizes a Modality Feature Representation Head (MFRH) to integrate the global information of the input image. By injecting the information contained in MFRH of the current image into other modality images, it effectively reduces the impact of modality differences on feature alignment while preserving the complementary information carried by different images. In terms of feature alignment, BSFA-F employs a bidirectional stepwise alignment deformation field prediction strategy based on the path independence of vector displacement between two points. This strategy solves the problem of large spans and inaccurate deformation field prediction in single-step alignment. Finally, Multi-Modal Feature Fusion block achieves the fusion of aligned features. The experimental results across multiple datasets demonstrate the effectiveness of our method. The source code is available at https://github.com/slrl123/BSAFusion.
Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Nov 26, 2024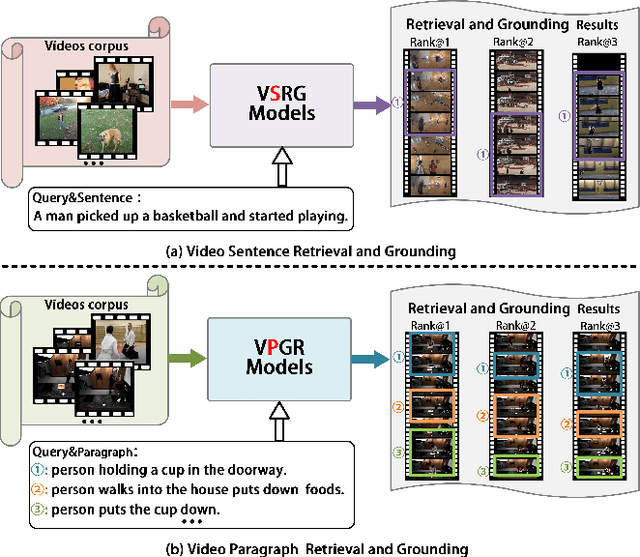
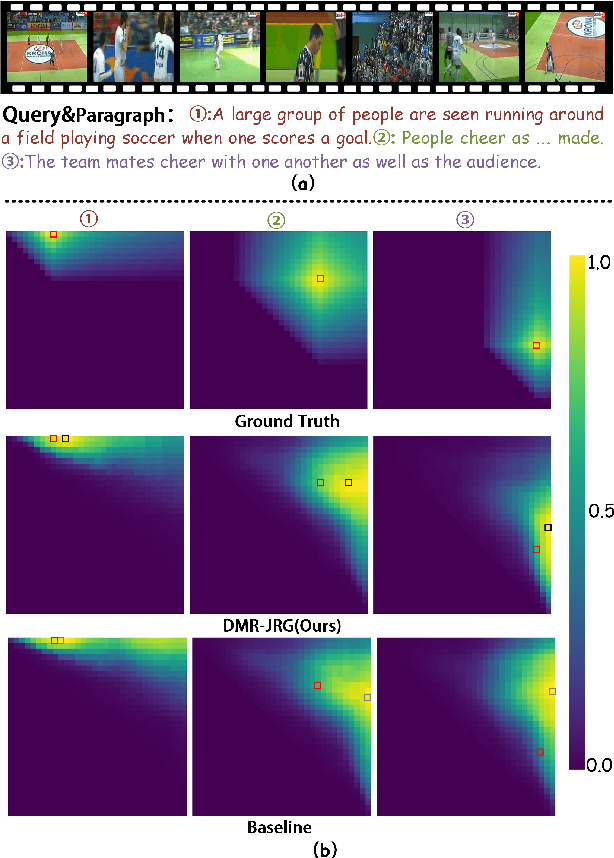

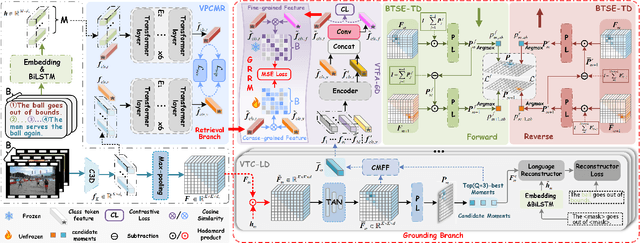
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.
Infrared-Assisted Single-Stage Framework for Joint Restoration and Fusion of Visible and Infrared Images under Hazy Conditions
Nov 16, 2024Infrared and visible (IR-VIS) image fusion has gained significant attention for its broad application value. However, existing methods often neglect the complementary role of infrared image in restoring visible image features under hazy conditions. To address this, we propose a joint learning framework that utilizes infrared image for the restoration and fusion of hazy IR-VIS images. To mitigate the adverse effects of feature diversity between IR-VIS images, we introduce a prompt generation mechanism that regulates modality-specific feature incompatibility. This creates a prompt selection matrix from non-shared image information, followed by prompt embeddings generated from a prompt pool. These embeddings help generate candidate features for dehazing. We further design an infrared-assisted feature restoration mechanism that selects candidate features based on haze density, enabling simultaneous restoration and fusion within a single-stage framework. To enhance fusion quality, we construct a multi-stage prompt embedding fusion module that leverages feature supplementation from the prompt generation module. Our method effectively fuses IR-VIS images while removing haze, yielding clear, haze-free fusion results. In contrast to two-stage methods that dehaze and then fuse, our approach enables collaborative training in a single-stage framework, making the model relatively lightweight and suitable for practical deployment. Experimental results validate its effectiveness and demonstrate advantages over existing methods.
Instruction-Driven Fusion of Infrared-Visible Images: Tailoring for Diverse Downstream Tasks
Nov 14, 2024



The primary value of infrared and visible image fusion technology lies in applying the fusion results to downstream tasks. However, existing methods face challenges such as increased training complexity and significantly compromised performance of individual tasks when addressing multiple downstream tasks simultaneously. To tackle this, we propose Task-Oriented Adaptive Regulation (T-OAR), an adaptive mechanism specifically designed for multi-task environments. Additionally, we introduce the Task-related Dynamic Prompt Injection (T-DPI) module, which generates task-specific dynamic prompts from user-input text instructions and integrates them into target representations. This guides the feature extraction module to produce representations that are more closely aligned with the specific requirements of downstream tasks. By incorporating the T-DPI module into the T-OAR framework, our approach generates fusion images tailored to task-specific requirements without the need for separate training or task-specific weights. This not only reduces computational costs but also enhances adaptability and performance across multiple tasks. Experimental results show that our method excels in object detection, semantic segmentation, and salient object detection, demonstrating its strong adaptability, flexibility, and task specificity. This provides an efficient solution for image fusion in multi-task environments, highlighting the technology's potential across diverse applications.
Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding
Oct 31, 2024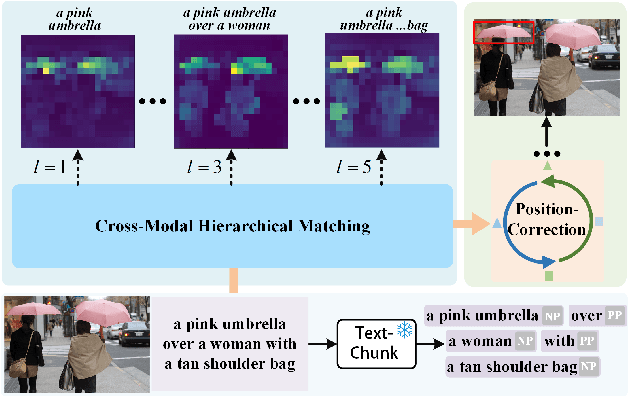

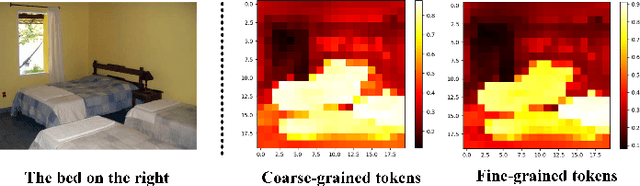
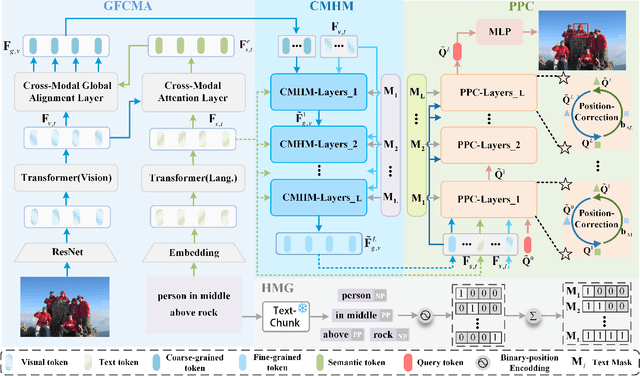
Visual grounding has attracted wide attention thanks to its broad application in various visual language tasks. Although visual grounding has made significant research progress, existing methods ignore the promotion effect of the association between text and image features at different hierarchies on cross-modal matching. This paper proposes a Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction Visual Grounding method. It first generates a mask through decoupled sentence phrases, and a text and image hierarchical matching mechanism is constructed, highlighting the role of association between different hierarchies in cross-modal matching. In addition, a corresponding target object position progressive correction strategy is defined based on the hierarchical matching mechanism to achieve accurate positioning for the target object described in the text. This method can continuously optimize and adjust the bounding box position of the target object as the certainty of the text description of the target object improves. This design explores the association between features at different hierarchies and highlights the role of features related to the target object and its position in target positioning. The proposed method is validated on different datasets through experiments, and its superiority is verified by the performance comparison with the state-of-the-art methods.
Single-Image HDR Reconstruction Assisted Ghost Suppression and Detail Preservation Network for Multi-Exposure HDR Imaging
Mar 07, 2024



The reconstruction of high dynamic range (HDR) images from multi-exposure low dynamic range (LDR) images in dynamic scenes presents significant challenges, especially in preserving and restoring information in oversaturated regions and avoiding ghosting artifacts. While current methods often struggle to address these challenges, our work aims to bridge this gap by developing a multi-exposure HDR image reconstruction network for dynamic scenes, complemented by single-frame HDR image reconstruction. This network, comprising single-frame HDR reconstruction with enhanced stop image (SHDR-ESI) and SHDR-ESI-assisted multi-exposure HDR reconstruction (SHDRA-MHDR), effectively leverages the ghost-free characteristic of single-frame HDR reconstruction and the detail-enhancing capability of ESI in oversaturated areas. Specifically, SHDR-ESI innovatively integrates single-frame HDR reconstruction with the utilization of ESI. This integration not only optimizes the single image HDR reconstruction process but also effectively guides the synthesis of multi-exposure HDR images in SHDR-AMHDR. In this method, the single-frame HDR reconstruction is specifically applied to reduce potential ghosting effects in multiexposure HDR synthesis, while the use of ESI images assists in enhancing the detail information in the HDR synthesis process. Technically, SHDR-ESI incorporates a detail enhancement mechanism, which includes a self-representation module and a mutual-representation module, designed to aggregate crucial information from both reference image and ESI. To fully leverage the complementary information from non-reference images, a feature interaction fusion module is integrated within SHDRA-MHDR. Additionally, a ghost suppression module, guided by the ghost-free results of SHDR-ESI, is employed to suppress the ghosting artifacts.
Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing
Mar 02, 2024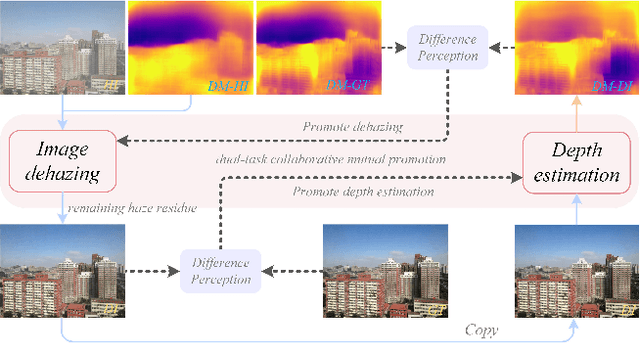
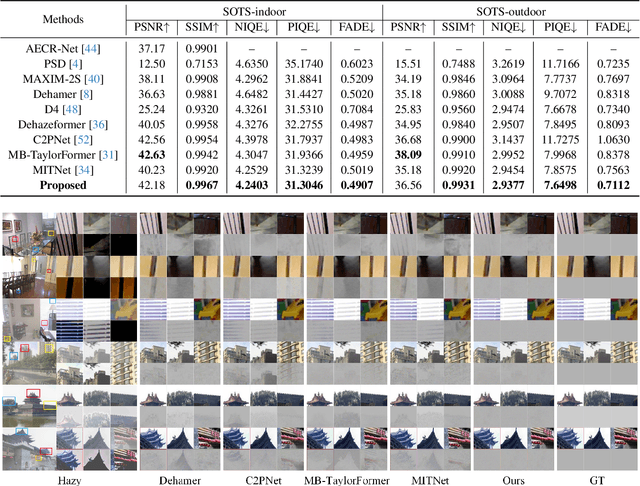
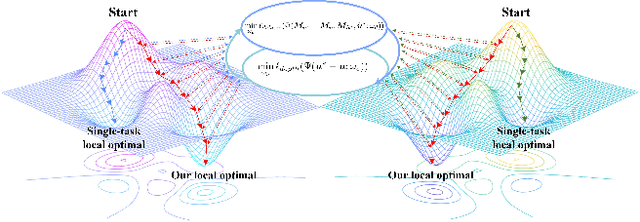

Recovering a clear image from a single hazy image is an open inverse problem. Although significant research progress has been made, most existing methods ignore the effect that downstream tasks play in promoting upstream dehazing. From the perspective of the haze generation mechanism, there is a potential relationship between the depth information of the scene and the hazy image. Based on this, we propose a dual-task collaborative mutual promotion framework to achieve the dehazing of a single image. This framework integrates depth estimation and dehazing by a dual-task interaction mechanism and achieves mutual enhancement of their performance. To realize the joint optimization of the two tasks, an alternative implementation mechanism with the difference perception is developed. On the one hand, the difference perception between the depth maps of the dehazing result and the ideal image is proposed to promote the dehazing network to pay attention to the non-ideal areas of the dehazing. On the other hand, by improving the depth estimation performance in the difficult-to-recover areas of the hazy image, the dehazing network can explicitly use the depth information of the hazy image to assist the clear image recovery. To promote the depth estimation, we propose to use the difference between the dehazed image and the ground truth to guide the depth estimation network to focus on the dehazed unideal areas. It allows dehazing and depth estimation to leverage their strengths in a mutually reinforcing manner. Experimental results show that the proposed method can achieve better performance than that of the state-of-the-art approaches.