 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine intelligence supports the full chain of 2D dendrite synthesis
Mar 17, 2026Exemplified by the chemical vapor deposition growth of two-dimensional dendrites, which has potential applications in catalysis and presents a parameter-intensive, data-scarce and reaction process-complex model problem, we devise a machine intelligence-empowered framework for the full chain support of material synthesis, encompassing rapid process optimization, accurate customized synthesis, and comprehensive mechanism deciphering.First, active learning is integrated into the experimental workflow, identifying an optimal recipe for the growth of highly-branched, electrocatalytically-active ReSe2 dendrites through 60 experiments (4 iterations), which account for less than 1.3% of the numerous possible parameter combinations.Then, a prediction accuracy-guided data augmentation strategy is developed combined with a tree-based machine learning (ML) algorithm, unveiling a non-linear correlation between 5 process variables and fractal dimension (DF) of ReSe2 dendrites with only 9 experiment additions, which guides the synthesis of various user-defined DF. Finally, we construct a data-knowledge dual-driven mechanism model by integration of cross-scale characterizations, interpretable ML models, and domain knowledge in thermodynamics and kinetics, unraveling synergistic contributions of multiple process parameters to the product morphology. This work demonstrates the ML potential to transform the research paradigm and is adaptable to broader material synthesis.
Can a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Jul 28, 2025



Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed ``Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the ``Asymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
Reasoning based on symbolic and parametric knowledge bases: a survey
Jan 02, 2025Reasoning is fundamental to human intelligence, and critical for problem-solving, decision-making, and critical thinking. Reasoning refers to drawing new conclusions based on existing knowledge, which can support various applications like clinical diagnosis, basic education, and financial analysis. Though a good number of surveys have been proposed for reviewing reasoning-related methods, none of them has systematically investigated these methods from the viewpoint of their dependent knowledge base. Both the scenarios to which the knowledge bases are applied and their storage formats are significantly different. Hence, investigating reasoning methods from the knowledge base perspective helps us better understand the challenges and future directions. To fill this gap, this paper first classifies the knowledge base into symbolic and parametric ones. The former explicitly stores information in human-readable symbols, and the latter implicitly encodes knowledge within parameters. Then, we provide a comprehensive overview of reasoning methods using symbolic knowledge bases, parametric knowledge bases, and both of them. Finally, we identify the future direction toward enhancing reasoning capabilities to bridge the gap between human and machine intelligence.
Enhancing Relation Extraction via Supervised Rationale Verification and Feedback
Dec 10, 2024Despite the rapid progress that existing automated feedback methods have made in correcting the output of large language models (LLMs), these methods cannot be well applied to the relation extraction (RE) task due to their designated feedback objectives and correction manner. To address this problem, we propose a novel automated feedback framework for RE, which presents a rationale supervisor to verify the rationale and provide re-selected demonstrations as feedback to correct the initial prediction. Specifically, we first design a causal intervention and observation method for to collect biased/unbiased rationales for contrastive training the rationale supervisor. Then, we present a verification-feedback-correction procedure to iteratively enhance LLMs' capability of handling the RE task. Extensive experiments prove that our proposed framework significantly outperforms existing methods.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024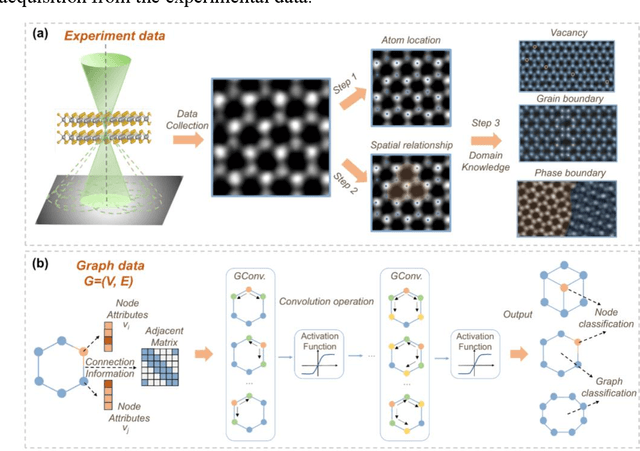
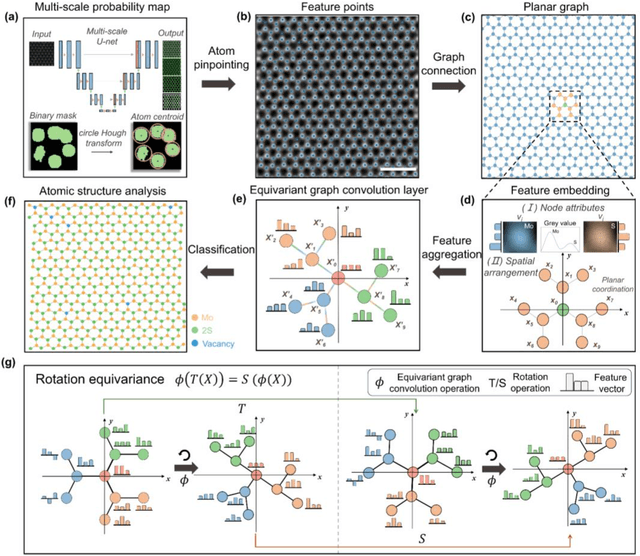
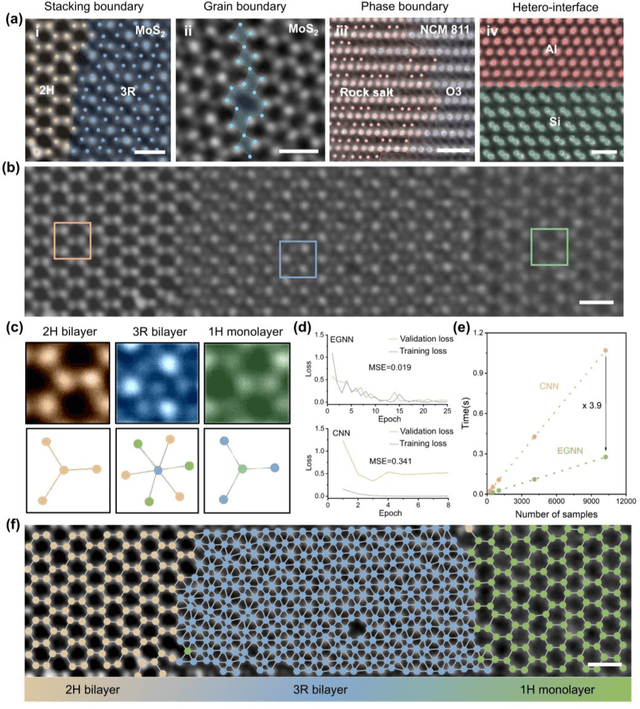
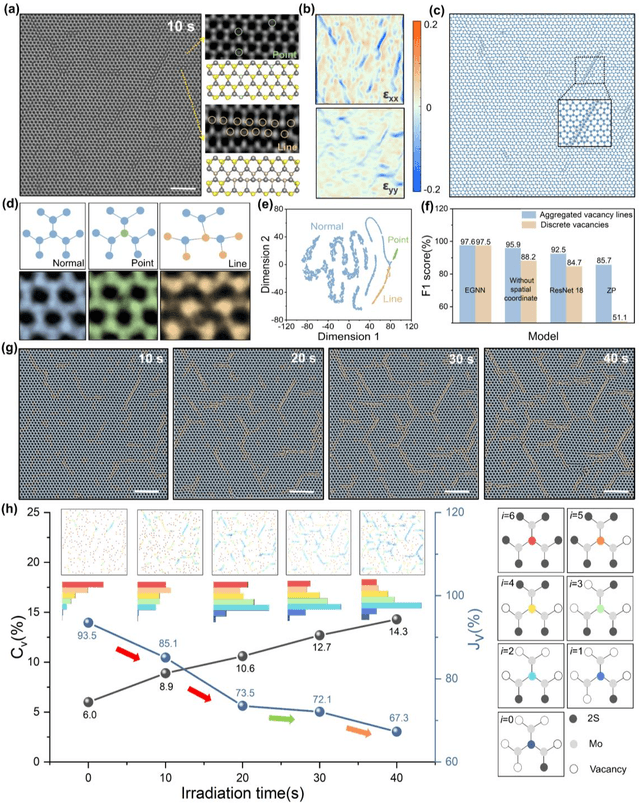
The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.
Multi-Expert Adaptive Selection: Task-Balancing for All-in-One Image Restoration
Jul 27, 2024
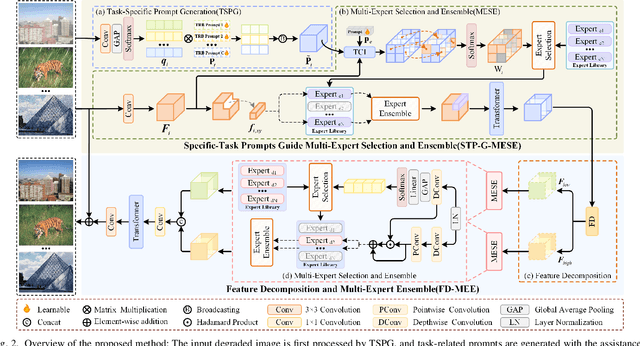
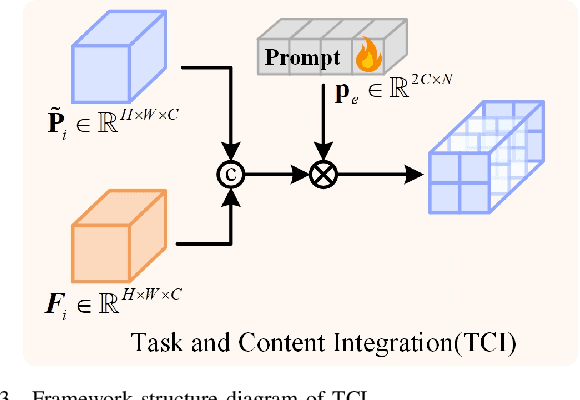

The use of a single image restoration framework to achieve multi-task image restoration has garnered significant attention from researchers. However, several practical challenges remain, including meeting the specific and simultaneous demands of different tasks, balancing relationships between tasks, and effectively utilizing task correlations in model design. To address these challenges, this paper explores a multi-expert adaptive selection mechanism. We begin by designing a feature representation method that accounts for both the pixel channel level and the global level, encompassing low-frequency and high-frequency components of the image. Based on this method, we construct a multi-expert selection and ensemble scheme. This scheme adaptively selects the most suitable expert from the expert library according to the content of the input image and the prompts of the current task. It not only meets the individualized needs of different tasks but also achieves balance and optimization across tasks. By sharing experts, our design promotes interconnections between different tasks, thereby enhancing overall performance and resource utilization. Additionally, the multi-expert mechanism effectively eliminates irrelevant experts, reducing interference from them and further improving the effectiveness and accuracy of image restoration. Experimental results demonstrate that our proposed method is both effective and superior to existing approaches, highlighting its potential for practical applications in multi-task image restoration.
Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing
Mar 02, 2024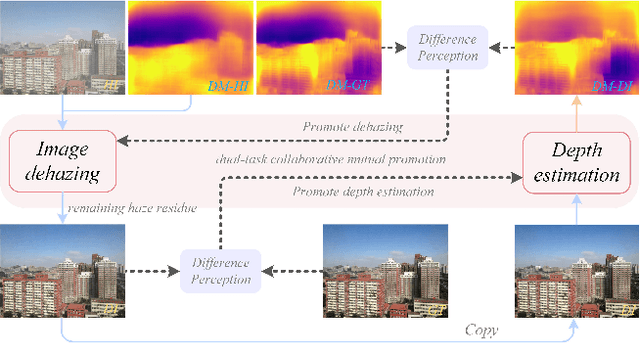
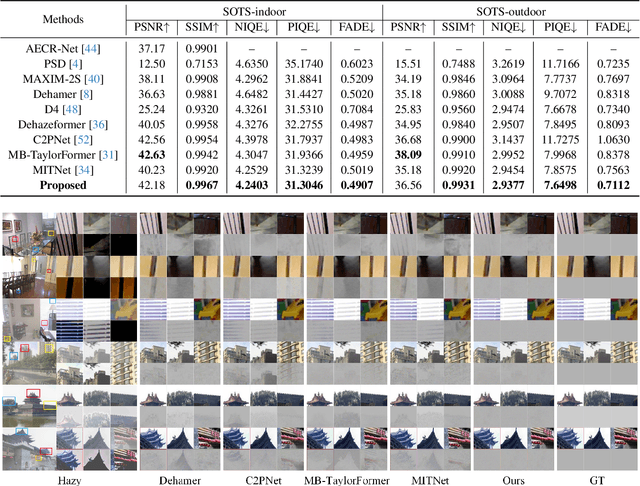
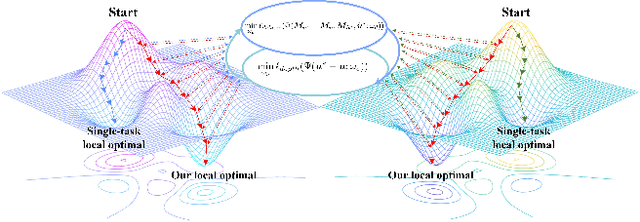

Recovering a clear image from a single hazy image is an open inverse problem. Although significant research progress has been made, most existing methods ignore the effect that downstream tasks play in promoting upstream dehazing. From the perspective of the haze generation mechanism, there is a potential relationship between the depth information of the scene and the hazy image. Based on this, we propose a dual-task collaborative mutual promotion framework to achieve the dehazing of a single image. This framework integrates depth estimation and dehazing by a dual-task interaction mechanism and achieves mutual enhancement of their performance. To realize the joint optimization of the two tasks, an alternative implementation mechanism with the difference perception is developed. On the one hand, the difference perception between the depth maps of the dehazing result and the ideal image is proposed to promote the dehazing network to pay attention to the non-ideal areas of the dehazing. On the other hand, by improving the depth estimation performance in the difficult-to-recover areas of the hazy image, the dehazing network can explicitly use the depth information of the hazy image to assist the clear image recovery. To promote the depth estimation, we propose to use the difference between the dehazed image and the ground truth to guide the depth estimation network to focus on the dehazed unideal areas. It allows dehazing and depth estimation to leverage their strengths in a mutually reinforcing manner. Experimental results show that the proposed method can achieve better performance than that of the state-of-the-art approaches.
Large Language Models as Counterfactual Generator: Strengths and Weaknesses
May 24, 2023Large language models (LLMs) have demonstrated remarkable performance in a range of natural language understanding and generation tasks. Yet, their ability to generate counterfactuals, which can be used for areas like data augmentation, remains under-explored. This study aims to investigate the counterfactual generation capabilities of LLMs and analysis factors that influence this ability. First, we evaluate how effective are LLMs in counterfactual generation through data augmentation experiments for small language models (SLMs) across four tasks: sentiment analysis, natural language inference, named entity recognition, and relation extraction. While LLMs show promising enhancements in various settings, they struggle in complex tasks due to their self-limitations and the lack of logical guidance to produce counterfactuals that align with commonsense. Second, our analysis reveals the pivotal role of providing accurate task definitions and detailed step-by-step instructions to LLMs in generating counterfactuals. Interestingly, we also find that LLMs can generate reasonable counterfactuals even with unreasonable demonstrations, which illustrates that demonstrations are primarily to regulate the output format.This study provides the first comprehensive insight into counterfactual generation abilities of LLMs, and offers a novel perspective on utilizing LLMs for data augmentation to enhance SLMs.