 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContiGuard: A Framework for Continual Toxicity Detection Against Evolving Evasive Perturbations
Mar 16, 2026Toxicity detection mitigates the dissemination of toxic content (e.g., hateful comments, posts, and messages within online social actions) to safeguard a healthy online social environment. However, malicious users persistently develop evasive perturbations to disguise toxic content and evade detectors. Traditional detectors or methods are static over time and are inadequate in addressing these evolving evasion tactics. Thus, continual learning emerges as a logical approach to dynamically update detection ability against evolving perturbations. Nevertheless, disparities across perturbations hinder the detector's continual learning on perturbed text. More importantly, perturbation-induced noises distort semantics to degrade comprehension and also impair critical feature learning to render detection sensitive to perturbations. These amplify the challenge of continual learning against evolving perturbations. In this work, we present ContiGuard, the first framework tailored for continual learning of the detector on time-evolving perturbed text (termed continual toxicity detection) to enable the detector to continually update capability and maintain sustained resilience against evolving perturbations. Specifically, to boost the comprehension, we present an LLM-powered semantic enriching strategy, where we dynamically incorporate possible meaning and toxicity-related clues excavated by LLM into the perturbed text to improve the comprehension. To mitigate non-critical features and amplify critical ones, we propose a discriminability-driven feature learning strategy, where we strengthen discriminative features while suppressing the less-discriminative ones to shape a robust classification boundary for detection...
Beyond Static Snapshots: Dynamic Modeling and Forecasting of Group-Level Value Evolution with Large Language Models
Feb 15, 2026Social simulation is critical for mining complex social dynamics and supporting data-driven decision making. LLM-based methods have emerged as powerful tools for this task by leveraging human-like social questionnaire responses to model group behaviors. Existing LLM-based approaches predominantly focus on group-level values at discrete time points, treating them as static snapshots rather than dynamic processes. However, group-level values are not fixed but shaped by long-term social changes. Modeling their dynamics is thus crucial for accurate social evolution prediction--a key challenge in both data mining and social science. This problem remains underexplored due to limited longitudinal data, group heterogeneity, and intricate historical event impacts. To bridge this gap, we propose a novel framework for group-level dynamic social simulation by integrating historical value trajectories into LLM-based human response modeling. We select China and the U.S. as representative contexts, conducting stratified simulations across four core sociodemographic dimensions (gender, age, education, income). Using the World Values Survey, we construct a multi-wave, group-level longitudinal dataset to capture historical value evolution, and then propose the first event-based prediction method for this task, unifying social events, current value states, and group attributes into a single framework. Evaluations across five LLM families show substantial gains: a maximum 30.88\% improvement on seen questions and 33.97\% on unseen questions over the Vanilla baseline. We further find notable cross-group heterogeneity: U.S. groups are more volatile than Chinese groups, and younger groups in both countries are more sensitive to external changes. These findings advance LLM-based social simulation and provide new insights for social scientists to understand and predict social value changes.
SwiftVLM: Efficient Vision-Language Model Inference via Cross-Layer Token Bypass
Feb 03, 2026Visual token pruning is a promising approach for reducing the computational cost of vision-language models (VLMs), and existing methods often rely on early pruning decisions to improve efficiency. While effective on coarse-grained reasoning tasks, they suffer from significant performance degradation on tasks requiring fine-grained visual details. Through layer-wise analysis, we reveal substantial discrepancies in visual token importance across layers, showing that tokens deemed unimportant at shallow layers can later become highly relevant for text-conditioned reasoning. To avoid irreversible critical information loss caused by premature pruning, we introduce a new pruning paradigm, termed bypass, which preserves unselected visual tokens and forwards them to subsequent pruning stages for re-evaluation. Building on this paradigm, we propose SwiftVLM, a simple and training-free method that performs pruning at model-specific layers with strong visual token selection capability, while enabling independent pruning decisions across layers. Experiments across multiple VLMs and benchmarks demonstrate that SwiftVLM consistently outperforms existing pruning strategies, achieving superior accuracy-efficiency trade-offs and more faithful visual token selection behavior.
DTC: A Deformable Transposed Convolution Module for Medical Image Segmentation
Jan 25, 2026In medical image segmentation, particularly in UNet-like architectures, upsampling is primarily used to transform smaller feature maps into larger ones, enabling feature fusion between encoder and decoder features and supporting multi-scale prediction. Conventional upsampling methods, such as transposed convolution and linear interpolation, operate on fixed positions: transposed convolution applies kernel elements to predetermined pixel or voxel locations, while linear interpolation assigns values based on fixed coordinates in the original feature map. These fixed-position approaches may fail to capture structural information beyond predefined sampling positions and can lead to artifacts or loss of detail. Inspired by deformable convolutions, we propose a novel upsampling method, Deformable Transposed Convolution (DTC), which learns dynamic coordinates (i.e., sampling positions) to generate high-resolution feature maps for both 2D and 3D medical image segmentation tasks. Experiments on 3D (e.g., BTCV15) and 2D datasets (e.g., ISIC18, BUSI) demonstrate that DTC can be effectively integrated into existing medical image segmentation models, consistently improving the decoder's feature reconstruction and detail recovery capability.
MedSAM-based lung masking for multi-label chest X-ray classification
Dec 28, 2025Chest X-ray (CXR) imaging is widely used for screening and diagnosing pulmonary abnormalities, yet automated interpretation remains challenging due to weak disease signals, dataset bias, and limited spatial supervision. Foundation models for medical image segmentation (MedSAM) provide an opportunity to introduce anatomically grounded priors that may improve robustness and interpretability in CXR analysis. We propose a segmentation-guided CXR classification pipeline that integrates MedSAM as a lung region extraction module prior to multi-label abnormality classification. MedSAM is fine-tuned using a public image-mask dataset from Airlangga University Hospital. We then apply it to a curated subset of the public NIH CXR dataset to train and evaluate deep convolutional neural networks for multi-label prediction of five abnormalities (Mass, Nodule, Pneumonia, Edema, and Fibrosis), with the normal case (No Finding) evaluated via a derived score. Experiments show that MedSAM produces anatomically plausible lung masks across diverse imaging conditions. We find that masking effects are both task-dependent and architecture-dependent. ResNet50 trained on original images achieves the strongest overall abnormality discrimination, while loose lung masking yields comparable macro AUROC but significantly improves No Finding discrimination, indicating a trade-off between abnormality-specific classification and normal case screening. Tight masking consistently reduces abnormality level performance but improves training efficiency. Loose masking partially mitigates this degradation by preserving perihilar and peripheral context. These results suggest that lung masking should be treated as a controllable spatial prior selected to match the backbone and clinical objective, rather than applied uniformly.
Accelerated Patient-specific Non-Cartesian MRI Reconstruction using Implicit Neural Representations
Mar 07, 2025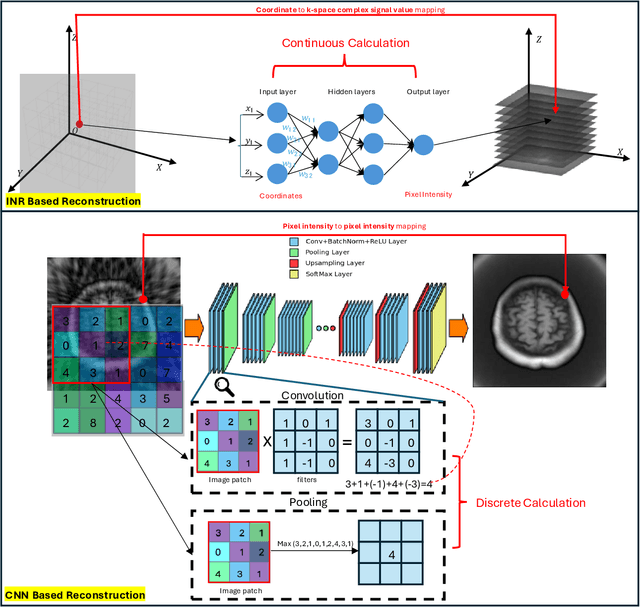
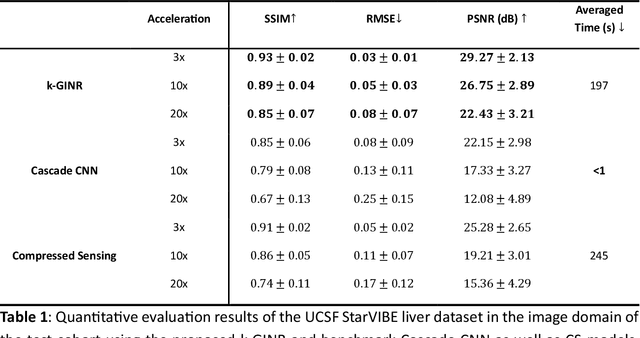
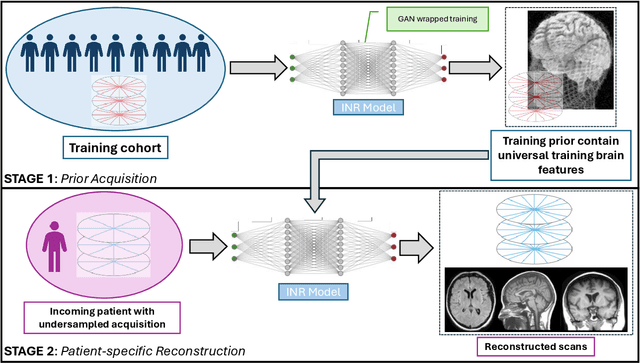
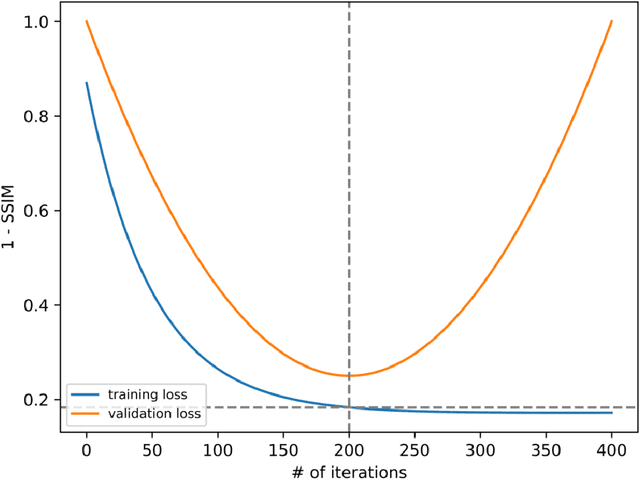
The scanning time for a fully sampled MRI can be undesirably lengthy. Compressed sensing has been developed to minimize image artifacts in accelerated scans, but the required iterative reconstruction is computationally complex and difficult to generalize on new cases. Image-domain-based deep learning methods (e.g., convolutional neural networks) emerged as a faster alternative but face challenges in modeling continuous k-space, a problem amplified with non-Cartesian sampling commonly used in accelerated acquisition. In comparison, implicit neural representations can model continuous signals in the frequency domain and thus are compatible with arbitrary k-space sampling patterns. The current study develops a novel generative-adversarially trained implicit neural representations (k-GINR) for de novo undersampled non-Cartesian k-space reconstruction. k-GINR consists of two stages: 1) supervised training on an existing patient cohort; 2) self-supervised patient-specific optimization. In stage 1, the network is trained with the generative-adversarial network on diverse patients of the same anatomical region supervised by fully sampled acquisition. In stage 2, undersampled k-space data of individual patients is used to tailor the prior-embedded network for patient-specific optimization. The UCSF StarVIBE T1-weighted liver dataset was evaluated on the proposed framework. k-GINR is compared with an image-domain deep learning method, Deep Cascade CNN, and a compressed sensing method. k-GINR consistently outperformed the baselines with a larger performance advantage observed at very high accelerations (e.g., 20 times). k-GINR offers great value for direct non-Cartesian k-space reconstruction for new incoming patients across a wide range of accelerations liver anatomy.
Reasoning based on symbolic and parametric knowledge bases: a survey
Jan 02, 2025Reasoning is fundamental to human intelligence, and critical for problem-solving, decision-making, and critical thinking. Reasoning refers to drawing new conclusions based on existing knowledge, which can support various applications like clinical diagnosis, basic education, and financial analysis. Though a good number of surveys have been proposed for reviewing reasoning-related methods, none of them has systematically investigated these methods from the viewpoint of their dependent knowledge base. Both the scenarios to which the knowledge bases are applied and their storage formats are significantly different. Hence, investigating reasoning methods from the knowledge base perspective helps us better understand the challenges and future directions. To fill this gap, this paper first classifies the knowledge base into symbolic and parametric ones. The former explicitly stores information in human-readable symbols, and the latter implicitly encodes knowledge within parameters. Then, we provide a comprehensive overview of reasoning methods using symbolic knowledge bases, parametric knowledge bases, and both of them. Finally, we identify the future direction toward enhancing reasoning capabilities to bridge the gap between human and machine intelligence.
Toxicity Detection towards Adaptability to Changing Perturbations
Dec 17, 2024Toxicity detection is crucial for maintaining the peace of the society. While existing methods perform well on normal toxic contents or those generated by specific perturbation methods, they are vulnerable to evolving perturbation patterns. However, in real-world scenarios, malicious users tend to create new perturbation patterns for fooling the detectors. For example, some users may circumvent the detector of large language models (LLMs) by adding `I am a scientist' at the beginning of the prompt. In this paper, we introduce a novel problem, i.e., continual learning jailbreak perturbation patterns, into the toxicity detection field. To tackle this problem, we first construct a new dataset generated by 9 types of perturbation patterns, 7 of them are summarized from prior work and 2 of them are developed by us. We then systematically validate the vulnerability of current methods on this new perturbation pattern-aware dataset via both the zero-shot and fine tuned cross-pattern detection. Upon this, we present the domain incremental learning paradigm and the corresponding benchmark to ensure the detector's robustness to dynamically emerging types of perturbed toxic text. Our code and dataset are provided in the appendix and will be publicly available at GitHub, by which we wish to offer new research opportunities for the security-relevant communities.
Rapid Reconstruction of Extremely Accelerated Liver 4D MRI via Chained Iterative Refinement
Dec 14, 2024



Abstract Purpose: High-quality 4D MRI requires an impractically long scanning time for dense k-space signal acquisition covering all respiratory phases. Accelerated sparse sampling followed by reconstruction enhancement is desired but often results in degraded image quality and long reconstruction time. We hereby propose the chained iterative reconstruction network (CIRNet) for efficient sparse-sampling reconstruction while maintaining clinically deployable quality. Methods: CIRNet adopts the denoising diffusion probabilistic framework to condition the image reconstruction through a stochastic iterative denoising process. During training, a forward Markovian diffusion process is designed to gradually add Gaussian noise to the densely sampled ground truth (GT), while CIRNet is optimized to iteratively reverse the Markovian process from the forward outputs. At the inference stage, CIRNet performs the reverse process solely to recover signals from noise, conditioned upon the undersampled input. CIRNet processed the 4D data (3D+t) as temporal slices (2D+t). The proposed framework is evaluated on a data cohort consisting of 48 patients (12332 temporal slices) who underwent free-breathing liver 4D MRI. 3-, 6-, 10-, 20- and 30-times acceleration were examined with a retrospective random undersampling scheme. Compressed sensing (CS) reconstruction with a spatiotemporal constraint and a recently proposed deep network, Re-Con-GAN, are selected as baselines. Results: CIRNet consistently achieved superior performance compared to CS and Re-Con-GAN. The inference time of CIRNet, CS, and Re-Con-GAN are 11s, 120s, and 0.15s. Conclusion: A novel framework, CIRNet, is presented. CIRNet maintains useable image quality for acceleration up to 30 times, significantly reducing the burden of 4DMRI.
Enhancing Relation Extraction via Supervised Rationale Verification and Feedback
Dec 10, 2024Despite the rapid progress that existing automated feedback methods have made in correcting the output of large language models (LLMs), these methods cannot be well applied to the relation extraction (RE) task due to their designated feedback objectives and correction manner. To address this problem, we propose a novel automated feedback framework for RE, which presents a rationale supervisor to verify the rationale and provide re-selected demonstrations as feedback to correct the initial prediction. Specifically, we first design a causal intervention and observation method for to collect biased/unbiased rationales for contrastive training the rationale supervisor. Then, we present a verification-feedback-correction procedure to iteratively enhance LLMs' capability of handling the RE task. Extensive experiments prove that our proposed framework significantly outperforms existing methods.