 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal, Fake, or Manipulated? Detecting Machine-Influenced Text
Sep 18, 2025Large Language Model (LLMs) can be used to write or modify documents, presenting a challenge for understanding the intent behind their use. For example, benign uses may involve using LLM on a human-written document to improve its grammar or to translate it into another language. However, a document entirely produced by a LLM may be more likely to be used to spread misinformation than simple translation (\eg, from use by malicious actors or simply by hallucinating). Prior works in Machine Generated Text (MGT) detection mostly focus on simply identifying whether a document was human or machine written, ignoring these fine-grained uses. In this paper, we introduce a HiErarchical, length-RObust machine-influenced text detector (HERO), which learns to separate text samples of varying lengths from four primary types: human-written, machine-generated, machine-polished, and machine-translated. HERO accomplishes this by combining predictions from length-specialist models that have been trained with Subcategory Guidance. Specifically, for categories that are easily confused (\eg, different source languages), our Subcategory Guidance module encourages separation of the fine-grained categories, boosting performance. Extensive experiments across five LLMs and six domains demonstrate the benefits of our HERO, outperforming the state-of-the-art by 2.5-3 mAP on average.
Machine-generated Text Localization
Feb 19, 2024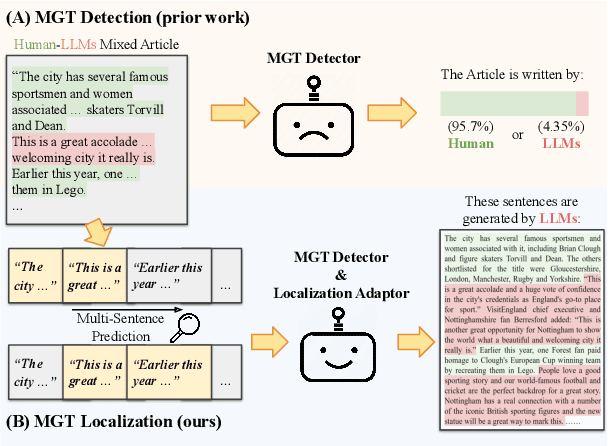
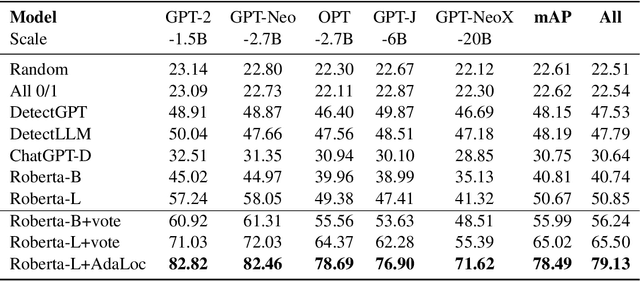
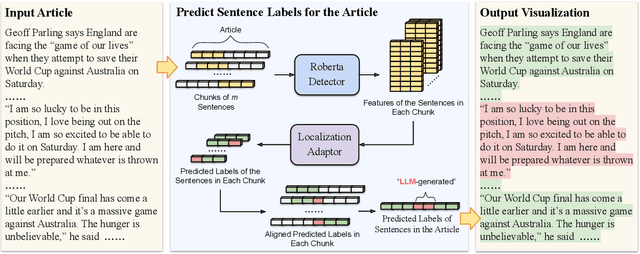
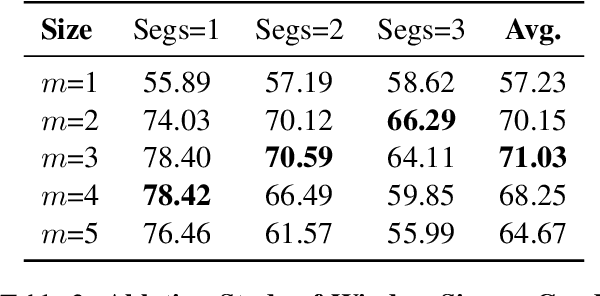
Machine-Generated Text (MGT) detection aims to identify a piece of text as machine or human written. Prior work has primarily formulated MGT as a binary classification task over an entire document, with limited work exploring cases where only part of a document is machine generated. This paper provides the first in-depth study of MGT that localizes the portions of a document that were machine generated. Thus, if a bad actor were to change a key portion of a news article to spread misinformation, whole document MGT detection may fail since the vast majority is human written, but our approach can succeed due to its granular approach. A key challenge in our MGT localization task is that short spans of text, e.g., a single sentence, provides little information indicating if it is machine generated due to its short length. To address this, we leverage contextual information, where we predict whether multiple sentences are machine or human written at once. This enables our approach to identify changes in style or content to boost performance. A gain of 4-13% mean Average Precision (mAP) over prior work demonstrates the effectiveness of approach on five diverse datasets: GoodNews, VisualNews, WikiText, Essay, and WP. We release our implementation at \href{https://github.com/Zhongping-Zhang/MGT_Localization}{this http URL}.
Text-to-image Editing by Image Information Removal
May 27, 2023Diffusion models have demonstrated impressive performance in text-guided image generation. To leverage the knowledge of text-guided image generation models in image editing, current approaches either fine-tune the pretrained models using the input image (e.g., Imagic) or incorporate structure information as additional constraints into the pretrained models (e.g., ControlNet). However, fine-tuning large-scale diffusion models on a single image can lead to severe overfitting issues and lengthy inference time. The information leakage from pretrained models makes it challenging to preserve the text-irrelevant content of the input image while generating new features guided by language descriptions. On the other hand, methods that incorporate structural guidance (e.g., edge maps, semantic maps, keypoints) as additional constraints face limitations in preserving other attributes of the original image, such as colors or textures. A straightforward way to incorporate the original image is to directly use it as an additional control. However, since image editing methods are typically trained on the image reconstruction task, the incorporation can lead to the identical mapping issue, where the model learns to output an image identical to the input, resulting in limited editing capabilities. To address these challenges, we propose a text-to-image editing model with Image Information Removal module (IIR) to selectively erase color-related and texture-related information from the original image, allowing us to better preserve the text-irrelevant content and avoid the identical mapping issue. We evaluate our model on three benchmark datasets: CUB, Outdoor Scenes, and COCO. Our approach achieves the best editability-fidelity trade-off, and our edited images are approximately 35% more preferred by annotators than the prior-arts on COCO.
Effectively leveraging Multi-modal Features for Movie Genre Classification
Mar 24, 2022



Movie genre classification has been widely studied in recent years due to its various applications in video editing, summarization, and recommendation. Prior work has typically addressed this task by predicting genres based solely on the visual content. As a result, predictions from these methods often perform poorly for genres such as documentary or musical, since non-visual modalities like audio or language play an important role in correctly classifying these genres. In addition, the analysis of long videos at frame level is always associated with high computational cost and makes the prediction less efficient. To address these two issues, we propose a Multi-Modal approach leveraging shot information, MMShot, to classify video genres in an efficient and effective way. We evaluate our method on MovieNet and Condensed Movies for genre classification, achieving 17% ~ 21% improvement on mean Average Precision (mAP) over the state-of-the-art. Extensive experiments are conducted to demonstrate the ability of MMShot for long video analysis and uncover the correlations between genres and multiple movie elements. We also demonstrate our approach's ability to generalize by evaluating the scene boundary detection task, achieving 1.1% improvement on Average Precision (AP) over the state-of-the-art.
Semantic Image Manipulation with Background-guided Internal Learning
Mar 24, 2022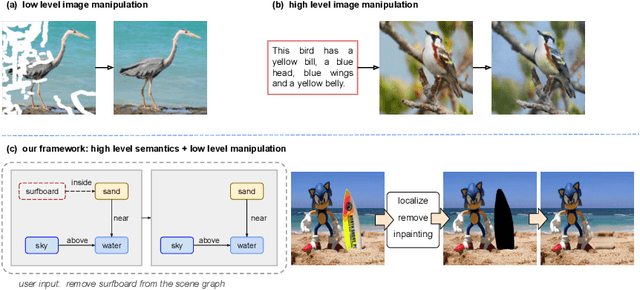



Image manipulation has attracted a lot of interest due to its wide range of applications. Prior work modifies images either from low-level manipulation, such as image inpainting or through manual edits via paintbrushes and scribbles, or from high-level manipulation, employing deep generative networks to output an image conditioned on high-level semantic input. In this study, we propose Semantic Image Manipulation with Background-guided Internal Learning (SIMBIL), which combines high-level and low-level manipulation. Specifically, users can edit an image at the semantic level by applying changes on a scene graph. Then our model manipulates the image at the pixel level according to the modified scene graph. There are two major advantages of our approach. First, high-level manipulation of scene graphs requires less manual effort from the user compared to manipulating raw image pixels. Second, our low-level internal learning approach is scalable to images of various sizes without reliance on external visual datasets for training. We outperform the state-of-the-art in a quantitative and qualitative evaluation on the CLEVR and Visual Genome datasets. Experiments show 8 points improvement on FID scores (CLEVR) and 27% improvement on user evaluation (Visual Genome), demonstrating the effectiveness of our approach.
Show and Write: Entity-aware News Generation with Image Information
Dec 11, 2021
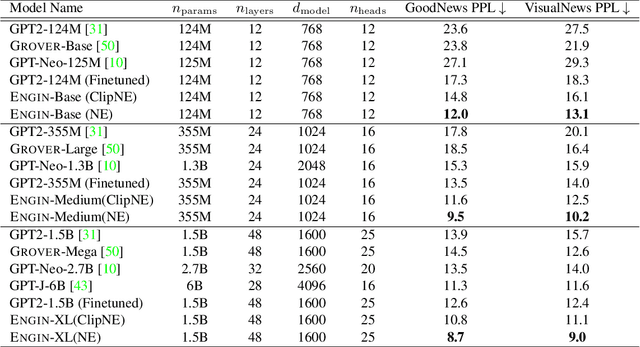
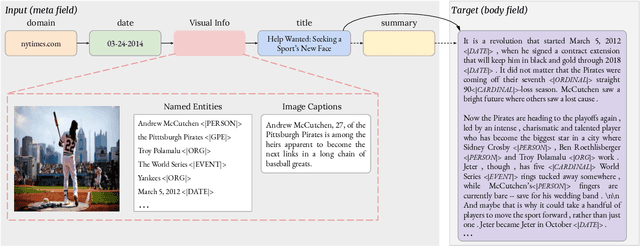

Automatically writing long articles is a complex and challenging language generation task. Prior work has primarily focused on generating these articles using human-written prompt to provide some topical context and some metadata about the article. That said, for many applications, such as generating news stories, these articles are often paired with images and their captions or alt-text, which in turn are based on real-world events and may reference many different named entities that are difficult to be correctly recognized and predicted by language models. To address these two problems, this paper introduces an Entity-aware News Generation method with Image iNformation, Engin, to incorporate news image information into language models. Engin produces news articles conditioned on both metadata and information such as captions and named entities extracted from images. We also propose an Entity-aware mechanism to help our model better recognize and predict the entity names in news. We perform experiments on two public large-scale news datasets, GoodNews and VisualNews. Quantitative results show that our approach improves article perplexity by 4-5 points over the base models. Qualitative results demonstrate the text generated by Engin is more consistent with news images. We also perform article quality annotation experiment on the generated articles to validate that our model produces higher-quality articles. Finally, we investigate the effect Engin has on methods that automatically detect machine-generated articles.
Effectively Leveraging Attributes for Visual Similarity
May 04, 2021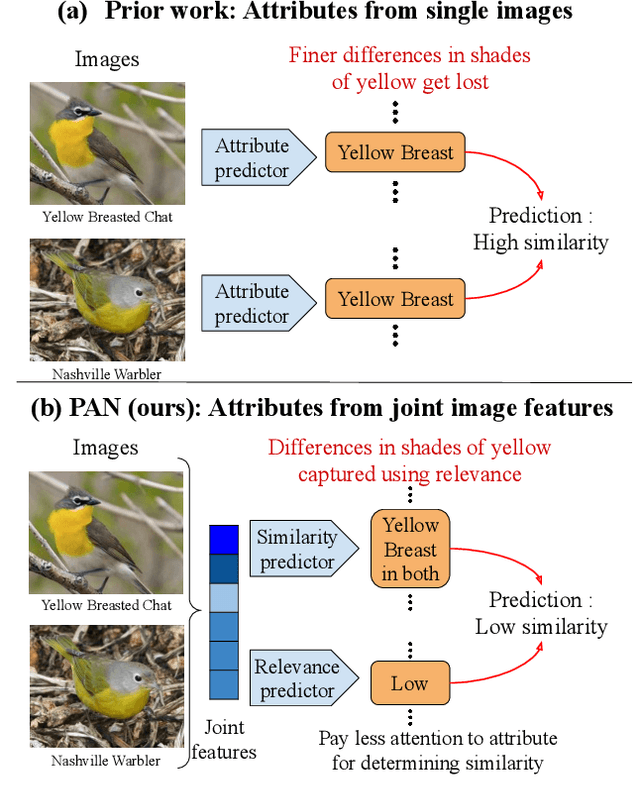
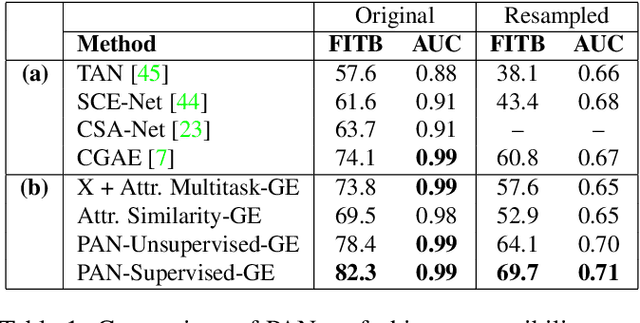


Measuring similarity between two images often requires performing complex reasoning along different axes (e.g., color, texture, or shape). Insights into what might be important for measuring similarity can can be provided by annotated attributes, but prior work tends to view these annotations as complete, resulting in them using a simplistic approach of predicting attributes on single images, which are, in turn, used to measure similarity. However, it is impractical for a dataset to fully annotate every attribute that may be important. Thus, only representing images based on these incomplete annotations may miss out on key information. To address this issue, we propose the Pairwise Attribute-informed similarity Network (PAN), which breaks similarity learning into capturing similarity conditions and relevance scores from a joint representation of two images. This enables our model to identify that two images contain the same attribute, but can have it deemed irrelevant (e.g., due to fine-grained differences between them) and ignored for measuring similarity between the two images. Notably, while prior methods of using attribute annotations are often unable to outperform prior art, PAN obtains a 4-9% improvement on compatibility prediction between clothing items on Polyvore Outfits, a 5\% gain on few shot classification of images using Caltech-UCSD Birds (CUB), and over 1% boost to Recall@1 on In-Shop Clothes Retrieval.
"Factual" or "Emotional": Stylized Image Captioning with Adaptive Learning and Attention
Jul 29, 2018
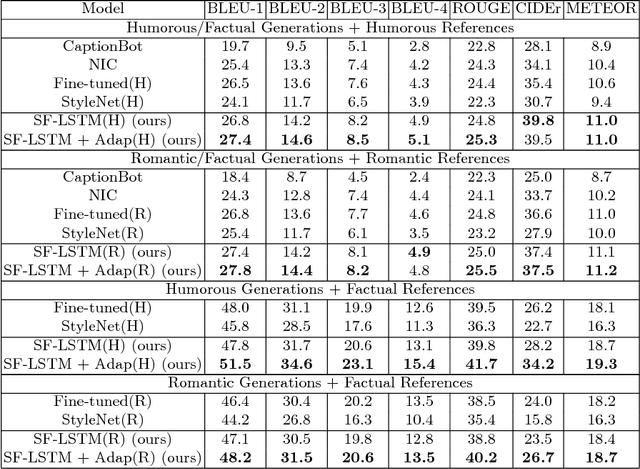
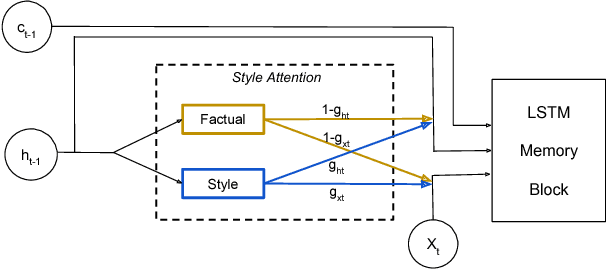
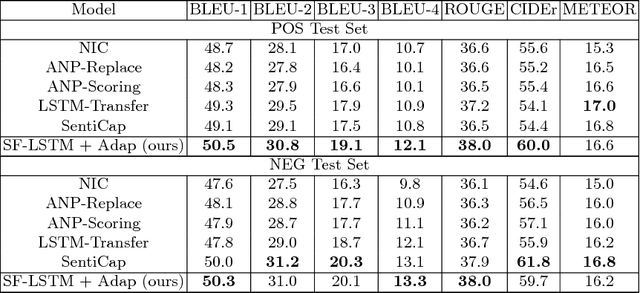
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
Boundary-based Image Forgery Detection by Fast Shallow CNN
Feb 03, 2018



Image forgery detection is the task of detecting and localizing forged parts in tampered images. Previous works mostly focus on high resolution images using traces of resampling features, demosaicing features or sharpness of edges. However, a good detection method should also be applicable to low resolution images because compressed or resized images are common these days. To this end, we propose a Shallow Convolutional Neural Network(SCNN), capable of distinguishing the boundaries of forged regions from original edges in low resolution images. SCNN is designed to utilize the information of chroma and saturation. Based on SCNN, two approaches that are named Sliding Windows Detection (SWD) and Fast SCNN, respectively, are developed to detect and localize image forgery region. In this paper, we substantiate that Fast SCNN can detect drastic change of chroma and saturation. In image forgery detection experiments Our model is evaluated on the CASIA 2.0 dataset. The results show that Fast SCNN performs well on low resolution images and achieves significant improvements over the state-of-the-art.