 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-generated Text Localization
Paper and Code
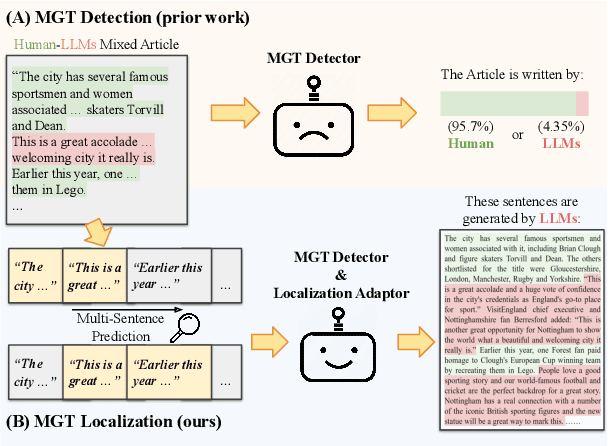
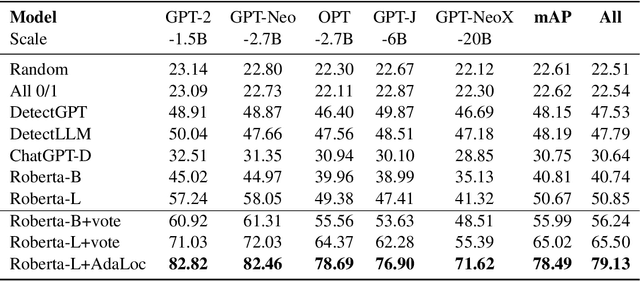
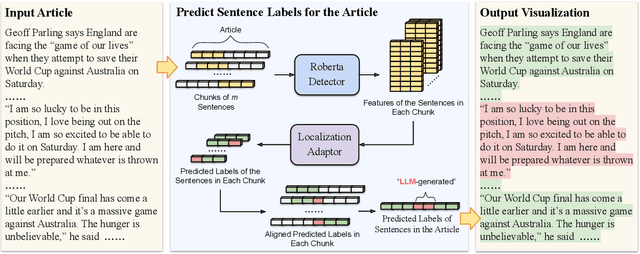
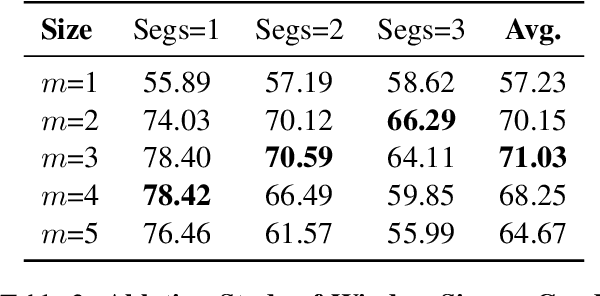
Machine-Generated Text (MGT) detection aims to identify a piece of text as machine or human written. Prior work has primarily formulated MGT as a binary classification task over an entire document, with limited work exploring cases where only part of a document is machine generated. This paper provides the first in-depth study of MGT that localizes the portions of a document that were machine generated. Thus, if a bad actor were to change a key portion of a news article to spread misinformation, whole document MGT detection may fail since the vast majority is human written, but our approach can succeed due to its granular approach. A key challenge in our MGT localization task is that short spans of text, e.g., a single sentence, provides little information indicating if it is machine generated due to its short length. To address this, we leverage contextual information, where we predict whether multiple sentences are machine or human written at once. This enables our approach to identify changes in style or content to boost performance. A gain of 4-13% mean Average Precision (mAP) over prior work demonstrates the effectiveness of approach on five diverse datasets: GoodNews, VisualNews, WikiText, Essay, and WP. We release our implementation at \href{https://github.com/Zhongping-Zhang/MGT_Localization}{this http URL}.